论文阅读:BSNR(2022-CVPR)
BSNR(2022-CVPR)
Blueprint Separable Residual Network for Efficient Image Super-Resolution
摘要
问题
-
深度网络使性能上的巨大进步,他们中的大多数都带来了高计算成本,这促使研究人员开发SR任务的更轻量且高效方法
-
前人使用的轻量化超分网络使用的策略:参数共享策略、使用组卷积、信息或特征蒸馏机制和注意力机制。虽然他们应用了紧凑的架构并提高了映射效率,但卷积操作仍然存在冗余
网络
Overall Framework
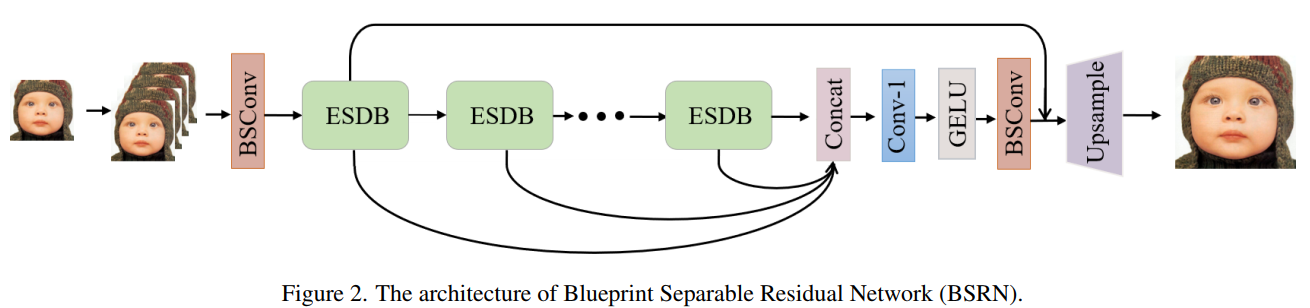
网络包括四个部分:浅层特征提取、深层特征提取、多层特征融合和重建
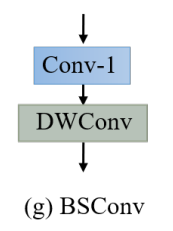
ESDB
Efficient Separable Distillation Block
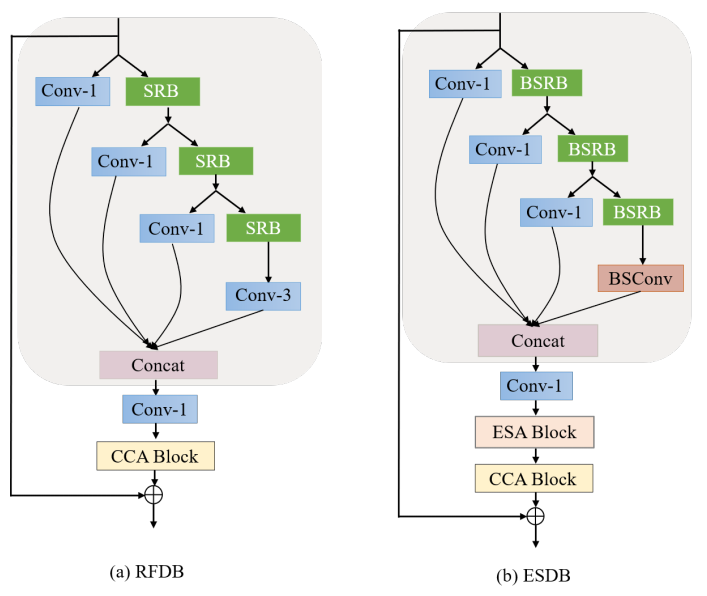
ESDB由3个阶段组成:特征蒸馏、特征浓缩和特征增强

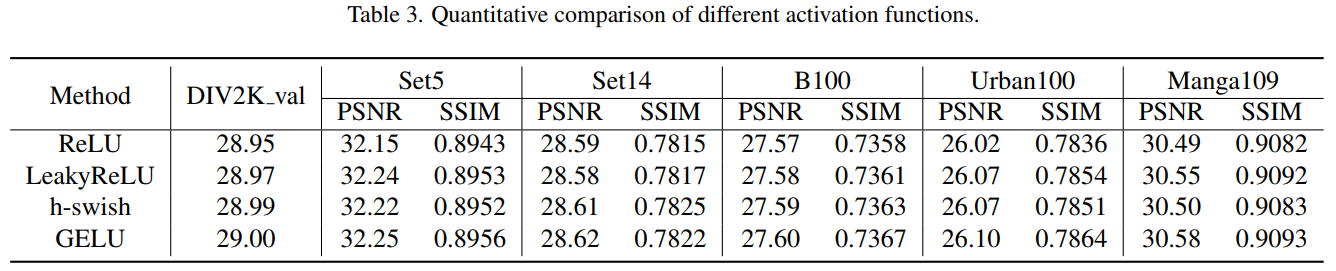
GELU可以看作是 ReLU 的一个更平滑的变体, 发现 GELU 比通常使用的ReLU和LeakyReLU表现更好
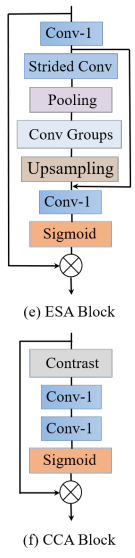
ESA-CCA
LOSS
L1 loss
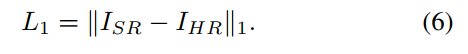
创新
-
-
我们利用两个有效的注意力模块限制额外的计算以增强模型能力:ESA和CCA
-
使用GELU做为激活函数
实验
Datasets
Training images: 2650 images from Flickr2K and 800 images from DIV2K.
Use the five standard benchmark datasets of Set5, Set14, B100, Urban100, and Manga109 to evaluate the performance of different approaches.
Metrics
PSNR, SSIM
Ablation Study
Effects of different convolution decompositions

Effectiveness of ESA and CCA

Exploration of different activation functions
Effectiveness of the proposed architecture

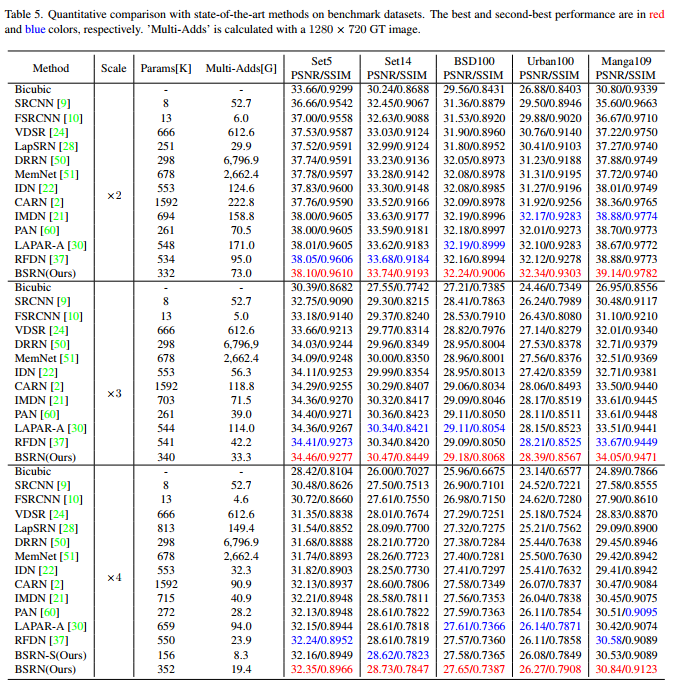
Comparison with State-of-the-art Methods
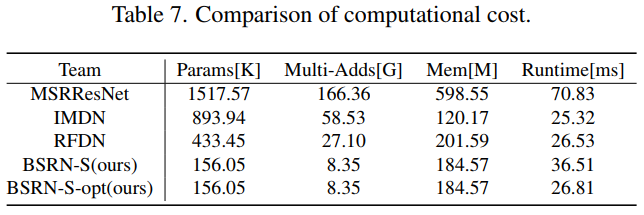
BSRN-S for NTIRE2022 Challenge
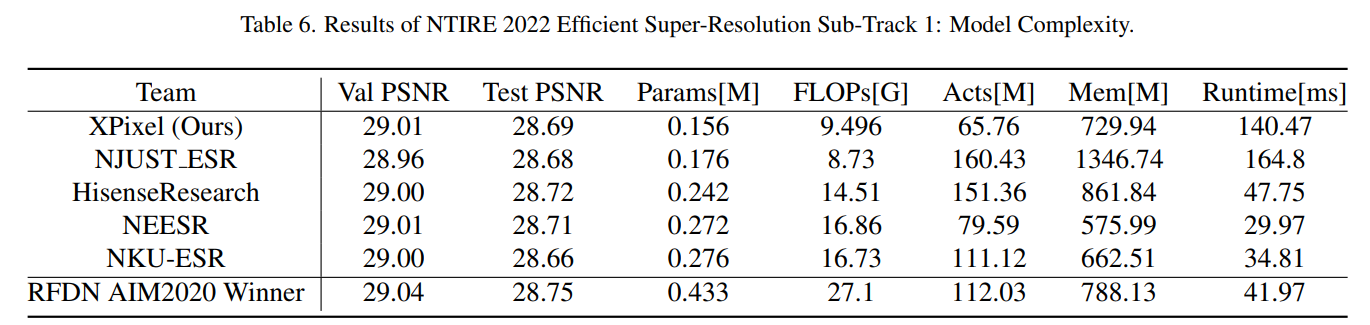
After optimization, BSRN-S-opt obtains similar runtime to IMDN and RFDN on the same GPU shown in Tab. 7.
在本文中,我们提出了一种用于单幅图像超分辨率的轻量级网络,称为蓝图可分离残差网络(BSRN)。 BSRN 的设计灵感来自残差特征蒸馏网络(RFDN)和蓝图可分离卷积(BSConv)。 我们采用了与 RFDN 类似的架构,但通过在 RFDN 中的浅残差块 (SRB) 中用 BSConv 替换标准卷积来引入更有效的蓝图浅残差块 (BSRB)。 此外,我们使用有效的 ECA 块和 CCA 块来增强模型的代表能力。 大量实验表明,与最先进的高效 SR 方法相比,我们的方法以更少的参数和 Multi-Adds 实现了最佳性能。 此外,我们的解决方案在 NTIRE 2022 高效超分辨率挑战的模型复杂度赛道上获得第一名。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号