论文阅读:D4
D4(2022-CVPR)
D4: Self-augmented Unpaired Image Dehazing via Density and Depth Decomposition
摘要
问题
1.基于深度学习的去雾方法,一种是基于物理模型,这些方法在分别估计透射和大气光时,可能会受到累计误差的影响(解决的方法是联合估计透射和大气光或者采用直接端到端估计去雾网络)。但是因为合成的模糊图像和真实世界的模糊图像之间存在相对较大的域差距。 仅在成对合成图像上训练的去雾模型很容易过度拟合,并且在现实世界的模糊条件下泛化能力很差。
2.一些无监督学习方法中,由于干净图像不参与训练,没有有效考虑干净图像域的内在属性,限制了他们的表现
3.真实世界模糊和干净的图像对是几乎无法获取,许多基于未成对图像数据集的学习方法被提出,构建去雾循环和再雾循环被广泛采用,因为它提供了一个简单有效的在执行时保持内容一致性的方案域转换。如果可以对模糊和干净的图像域进行准确建模,则循环框架为预计将在未配对的 dehaze上获得可观的表现。
4.现有的基于循环的去雾方法忽略现实世界朦胧环境的物理特性,即现实世界的雾度随密度和深度而变化。基于 CycleGAN 的方法很容易塌陷以合成具有固定密度的霾,并且可能错误地模拟了雾霾效应,例如雾霾应该是随着景深的增加而变厚。
网络
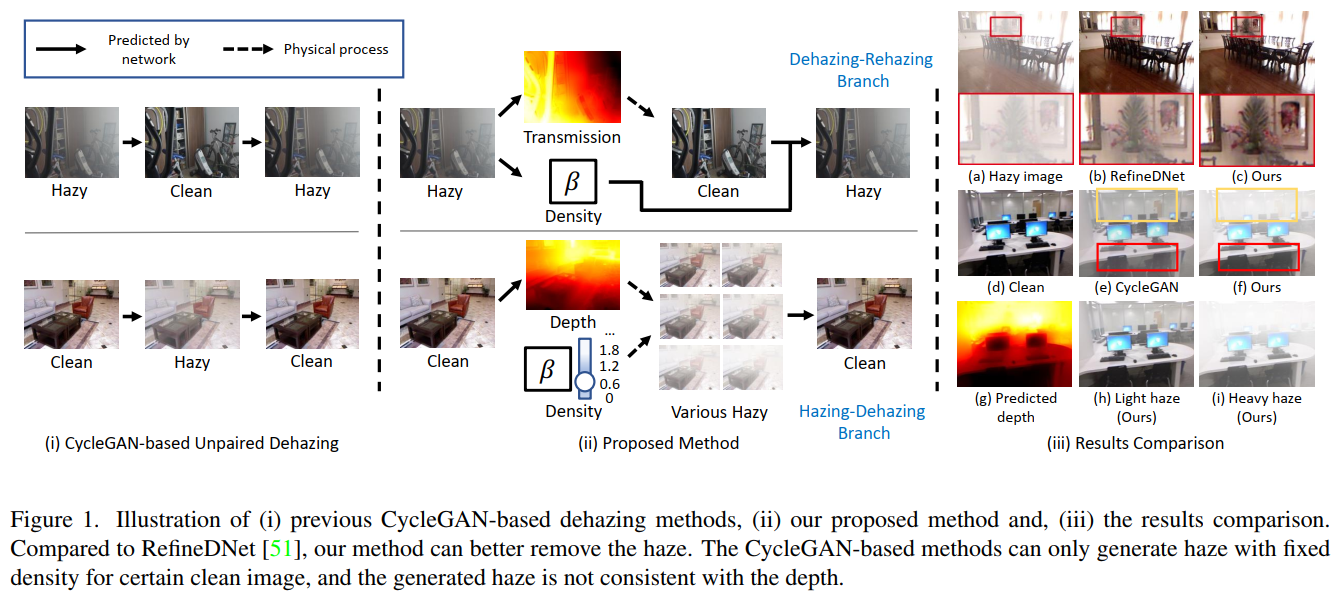
本文提出了一种称为 D4 的新型去雾框架,即通过将传输图分解为密度和深度进行去雾,用于非配对雾度合成和去除。在模糊图像形成过程之后,我们明确地对目标场景的散射系数 β 和深度图 d(z) 进行建模。如图 1 (ii) 所示,在 Dehzing-Rehazing 分支上,我们的模型被训练为直接从模糊图像中估计透射图和散射系数。根据方程式(1)表示的物理过程,场景深度和干净的内容可以直接推导出来。在 Hazing-Dehazing 分支上,我们的模型旨在估计输入干净图像的深度信息,然后合成具有不同密度的模糊图像,即散射系数。考虑到“空间变化的雾度厚度为感知场景深度提供了额外的线索”这一事实,从雾度图像估计的深度图充当了干净图像深度的伪地面实况。类似地,在 Hazing-Dehazing 分支中,Hazing 步骤中随机采样的散射系数 β 充当 Dehazing 步骤中预测的密度的伪真实值。
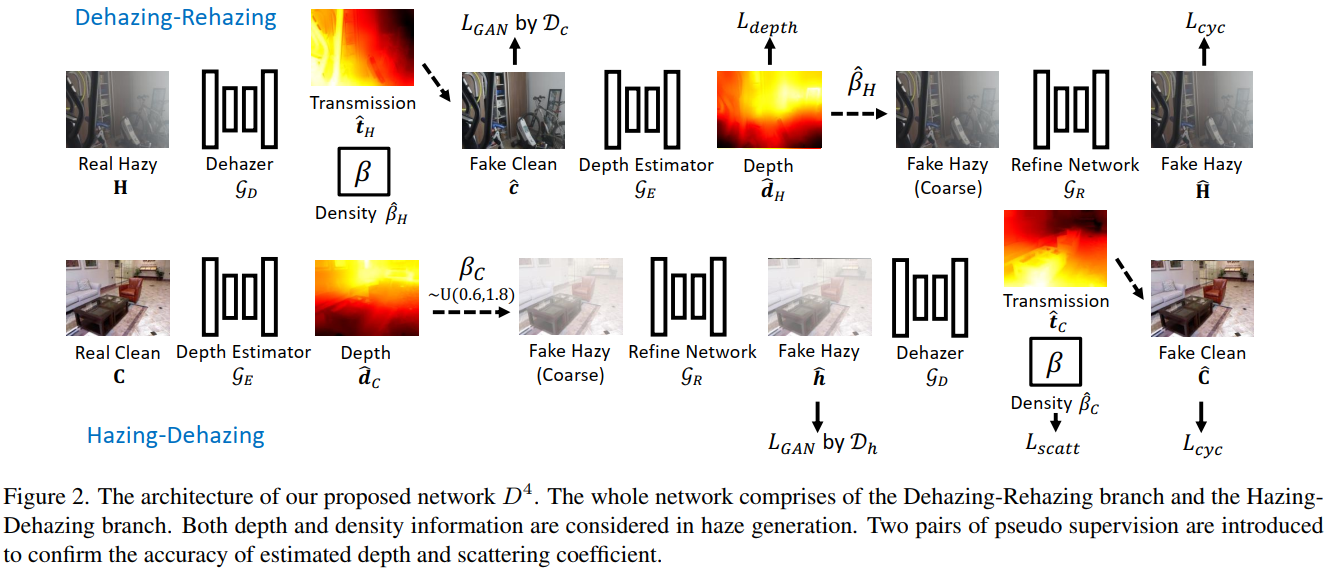
包含三个子网络:去雾网络G_D,深度评估网络G_E和细化网络G_R
structure of EfficientNet-lite3
![]()
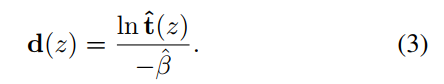
The depth estimation network G_E
![]()
The refine network G_R
structure of UNet
![]()
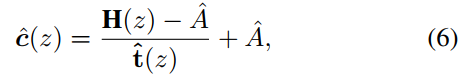
![]()
![]()
![]()
Cycle-consistency loss
![]()
Adversarial learning losses
adopt the LSGAN

![]()
Pseudo depth supervision loss
G_E仅由L_depth损失优化
![]()
Total Loss
![]()
1.提出了一个新颖的不成对去雾框架,明确对散射系数(即密度)和朦胧场景的深度图进行建模。拟议的基于物理的框架在很大程度上减轻了现有的未配对去雾方法中存在的不良问题
2.受到:“空间变化的雾度厚度反映场景深度”的启发,模型学会了预测来自模糊图像的深度信息。然后,在只有未配对的模糊和干净的图像下,模型经过训练从干净的图像中预测深度信息
3.通过估计的场景深度,模型能够通过改变散射系数产生不同浓度的雾图。这种特性作为自我论证策略,以更好地训练去雾网络
实验
Datasets:RESIDE,I-HAZE,Fattal
Metrics:PSNR,SSIM,CIEDE2000
对比实验
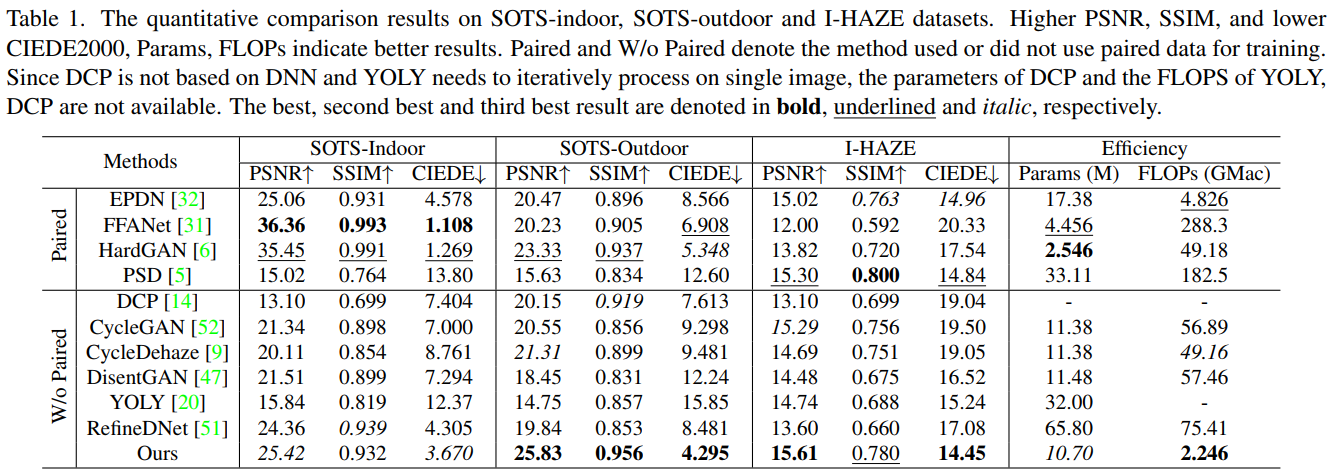
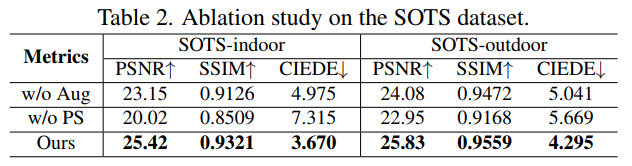
Ablation Study
结论
本文提出了一种称为 D4 的自增强非配对图像去雾框架,它将透射图的估计分解为预测密度和深度图。通过估计的深度,我们的方法能够重新渲染具有不同密度的模糊图像作为自增强,从而大大提高去雾性能。广泛的实验已经验证了我们的方法相对于其他最先进的去雾方法的明显优势。然而,我们的方法也有局限性,它通常会高估极亮区域的透射率,这会误导深度估计网络预测过亮区域的低深度值。此外,我们发现低质量的训练数据会使训练不稳定。但值得肯定的是,我们在物理模型中进一步分解变量的想法可以扩展到其他任务,例如弱光增强。我们希望我们的方法可以创新未来的工作,特别是对于低级视觉任务中的非配对学习
