学习论文:In-Datacenter Performance Analysis of a Tensor Processing UnitTM (TPU)
TPU--Tensor Processing UnitTM-张量处理单元
TPU的核心
是一个65,536的8位MAC矩阵相乘单元,
提供了92 TeraOps/秒(top)的峰值吞吐量和
一个大的(28 MiB)软件管理的片上存储器。
量子化
将浮点数转换为狭窄的整数(通常只有8位)(这对于推断来说已经足够了)
8位整数乘 比ieee754 16位浮点乘能量小6倍,面积小6倍,
整数加法的优点是能量小13X,面积小38X [Dal16]。
为了简化硬件设计和调试,主机服务器发送TPU指令让它执行,而不是自己获取指令。
因此,TPU在本质上更接近于FPU(浮点单元)协处理器,而不是GPU。
TPU框图
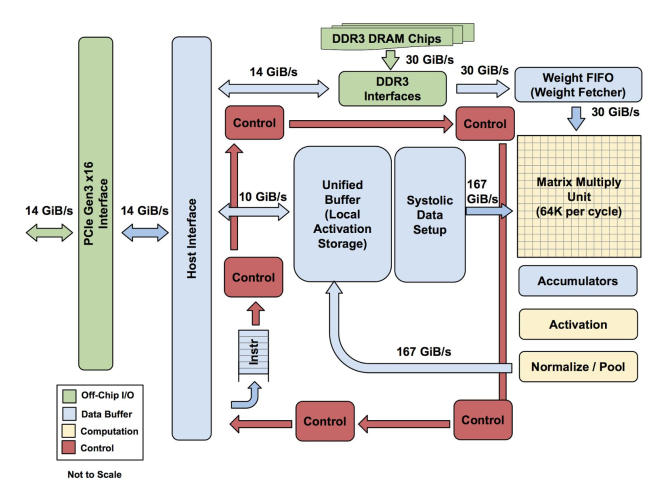
主要计算部分是黄色矩阵乘单元。它的输入是蓝色权重FIFO和蓝色统一缓冲区(UB)。
它的输出是蓝色累加器,黄色激活单元(Activation)执行非线性函数,并发送到UB上。
TPU指令通过PCIe Gen3 x16总线从主机发送到指令缓冲区。内部块通常由256字节宽
的路径连接在一起。从右上角开始,矩阵乘法单位是TPU的核心。它包含256x256个mac,
可以对有符号或无符号整数执行8位乘加运算。16位积在矩阵单元下面32位累加器的4个
MiB中收集。4MiB代表4096,256个32位的累加器。矩阵单元在每个时钟周期产生一个256
个元素的部分和。我们选择了4096,因为我们首先注意到每个字节的操作需要达到峰值
性能(第4节中的roofline knee),即~1350,所以我们将其四舍五入到2048,然后复制它,
以便编译器可以在运行峰值性能时使用双缓冲。
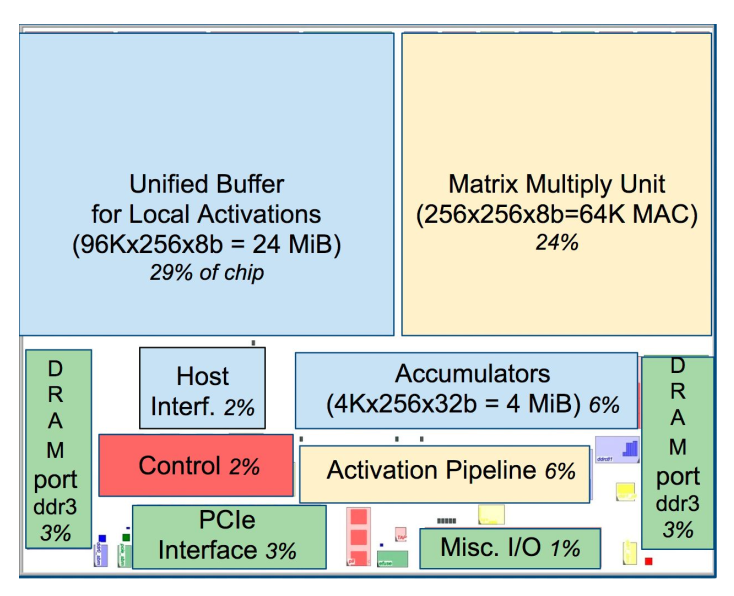
TPU模具平面布置图
指令
由于指令通过相对缓慢的PCIe总线发送,TPU指令遵循CISC传统,包括重复字段。
这些CISC指令的每条指令的平均时钟周期(CPI)通常是10到20。它总共有十几条指令,
但这五条是最关键的:
1. Read_Host_Memory从CPU主机内存中读取数据到UB中。
2. Read_Weights从权重存储器读取权重到权重FIFO作为矩阵单位的输入。
3.MatrixMultiply/Convolve (矩阵乘/卷积) 使矩阵单元执行矩阵乘或从统一缓冲区到累加
器的卷积。一个矩阵运算需要一个可变大小的B*256输入,乘以一个256x256等权值输
入,并产生一个B*256输出,需要B流水线周期来完成。
4. Activate执行人工神经元的非线性功能,有ReLU、Sigmoid等选项。它的输入是累加
器,输出是统一的缓冲区。它还可以使用die上的专用硬件执行卷积所需的池操作,因为
它连接到非线性函数逻辑。
5. Write_Host_Memory将统一缓冲区的数据写入CPU主机内存。
其他指令包括备用主机内存读写、设置配置、两个版本的同步、中断主机、调试标记、nop和halt。
(PS: CISC矩阵乘法指令为12字节,其中3个为统一的缓冲地址;2为累加器地址;
4是长度(有时是二维的卷积);剩下的是操作码和标志。)
矩阵乘法单位的收缩压数据流

由于读取一个大的SRAM比算术使用更多的功率,矩阵单元使用收缩执行,通过减少对统一缓
冲区的读写来节省能量。图4显示数据从左侧流入,权重从顶部加载。给定的256个元素的乘积
运算以对角波前的形式通过矩阵。这些重量是预先加载的,并随着新区块的第一批数据的推进
波而起作用。控制和数据被流水线化,从而产生一种假象,即256个输入被一次读取,并且它
们会立即更新256个累加器中的每个位置。从正确性的角度来看,软件不知道矩阵单元的收缩
特性,但就性能而言,它确实担心单元的延迟。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号