

版本兼容:
查看ceph和系统的版本是否兼容
节点说明
- ceph-admin: 192.168.83.133
- ceph 节点
| IP | Domain | Hostname | Services |
|---|---|---|---|
| 192.168.83.133 | stor01.kb.cx | ceph01 | mon,mgr,mds |
| 192.168.83.134 | stor02.kb.cx | ceph02 | mgr,mon,mds |
| 192.168.83.135 | stor03.kb.cx | ceph03 | osd,mds,mon |
- 操作系统 ubuntu20.04
cephadm 部署 ceph 集群时,需要如下依赖:
制作本地安装包的源:
-
在 Ubuntu 20.04 LTS 上安装 Docker (所有ceph节点都需要安装docker)
在 Ubuntu 20.04 LTS 上,虽然可以通过 Ubuntu 的官方仓库直接安装 Docker,但是这种方法通常无法获取到最新的 Docker 版本,而且安全更新也可能延迟。
因此,推荐从 Docker 的官方仓库进行安装,确保可以用上最新版本并和自动更新。
root@ceph01:/etc/ceph# lsb_release -a
No LSB modules are available.
Distributor ID: Ubuntu
Description: Ubuntu 20.04.6 LTS
Release: 20.04
Codename: focal
root@ceph01:/etc/ceph#
更新软件包并安装必要软件
运行以下命令,更新软件包索引并安装添加 Docker 仓库所需的前置软件包:
sudo apt update
sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
第 2 步:导入 Docker GPG 密钥
使用以下命令下载并导入 Docker 阿里云的 GPG 密钥:
curl -fsSL http://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
向 source.list 中添加Docker软件源
sudo add-apt-repository "deb [arch=amd64] http://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
再次更新索引包
sudo apt-get update
若想直接安装最新版本执行以下命令即可
sudo apt-get install docker-ce
查看docker版本
apt-cache madison docker-ce
安装cephadm,拉取ceph镜像
以下命令在controller节点执行
# 下面的命令会自动安装 docker 等依赖
apt install -y cephadm
安装cephadm
cephadm add-repo --release Quincy
cephadm install
root@cephadm:~# cephadm add-repo --release Quincy
Installing repo GPG key from https://download.ceph.com/keys/release.asc...
Installing repo file at /etc/apt/sources.list.d/ceph.list...
root@cephadm:~# cephadm install
Installing packages ['cephadm']...
root@cephadm:~# mkdir -p /etc/ceph
# 查看cpeh版本
root@cephadm:~# cephadm version
Using recent ceph image quay.io/ceph/ceph@sha256:c08064dde4bba4e72a1f55d90ca32df9ef5aafab82efe2e0a0722444a5aaacca
ceph version 15.2.17 (8a82819d84cf884bd39c17e3236e0632ac146dc4) octopus (stable)
root@cephadm:~#
# 查看docker镜像
root@cephadm:~# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
quay.io/ceph/ceph v15 93146564743f 23 months ago 1.2GB
quay.io/ceph/ceph-grafana 6.7.4 557c83e11646 2 years ago 486MB
quay.io/prometheus/prometheus v2.18.1 de242295e225 4 years ago 140MB
quay.io/prometheus/alertmanager v0.20.0 0881eb8f169f 4 years ago 52.1MB
quay.io/prometheus/node-exporter v0.18.1 e5a616e4b9cf 5 years ago 22.9MB
root@cephadm:~#
# 添加控制节点主机
cephadm shell --进入cephadm shell模式
ceph orch host add ceph01 --addr 192.168.34.133
初始化 mon 节点
引导新群集
要引导群集,需要先创建一个目录:/etc/ceph
mkdir -p /etc/ceph
root@cephadm:~# cephadm bootstrap --mon-ip 192.168.34.136
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit systemd-timesyncd.service is enabled and running
Repeating the final host check...
podman|docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit systemd-timesyncd.service is enabled and running
Host looks OK
Cluster fsid: 7ef6c16a-3da3-11ef-883c-b9d240548526
Verifying IP 192.168.34.136 port 3300 ...
Verifying IP 192.168.34.136 port 6789 ...
Mon IP 192.168.34.136 is in CIDR network 192.168.34.0/24
Pulling container image quay.io/ceph/ceph:v15...
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network...
Creating mgr...
Verifying port 9283 ...
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Wrote config to /etc/ceph/ceph.conf
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/10)...
mgr not available, waiting (2/10)...
mgr not available, waiting (3/10)...
mgr not available, waiting (4/10)...
mgr not available, waiting (5/10)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 5...
Mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to to /etc/ceph/ceph.pub
Adding key to root@localhost's authorized_keys...
Adding host cephadm...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Enabling mgr prometheus module...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 13...
Mgr epoch 13 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://cephadm:8443/
User: admin
Password: 960yr2594m
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 7ef6c16a-3da3-11ef-883c-b9d240548526 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
启用ceph cli
root@cephadm:~# cephadm install ceph-common
Installing packages ['ceph-common']...
部署OSD
如果满足以下所有_条件_,则存储设备被视为可用:
- 设备必须没有分区。
- 设备不得具有任何 LVM 状态。
- 不得安装设备。
- 设备不能包含文件系统。
- 设备不得包含 Ceph BlueStore OSD。
- 设备必须大于 5 GB。
Ceph 拒绝在不可用的设备上预配 OSD。为保证能成功添加osd,我刚才在cephadm节点上新加了一块磁盘
导出docker镜像
需要把这些镜像导出来,做成离线包
root@cephadm:~# docker save -o ceph.tar quay.io/ceph/ceph:v15
root@cephadm:~# docker save -o prometheus.tar quay.io/prometheus/prometheus:v2.18.1
root@cephadm:~# docker save -o grafana.tar quay.io/ceph/ceph-grafana:6.7.4
root@cephadm:~# docker save -o alertmanager.tar quay.io/prometheus/alertmanager:v0.20.0
root@cephadm:~# docker save -o node-exporter.tar quay.io/prometheus/node-exporter:v0.18.1
root@cephadm:~# ls
alertmanager.tar ceph.tar grafana.tar node-exporter.tar prometheus.tar snap
root@cephadm:~# du -sh *
52M alertmanager.tar
1.2G ceph.tar
473M grafana.tar
24M node-exporter.tar
135M prometheus.tar
16K snap
root@cephadm:~# ls -lrt
total 1910436
drwx------ 3 root root 4096 Jul 9 02:37 snap
-rw------- 1 root root 1241181696 Jul 9 04:10 ceph.tar
-rw------- 1 root root 141409792 Jul 9 04:10 prometheus.tar
-rw------- 1 root root 495826432 Jul 9 04:10 grafana.tar
-rw------- 1 root root 53499392 Jul 9 04:11 alertmanager.tar
-rw------- 1 root root 24352256 Jul 9 04:11 node-exporter.tar
导出deb包
刚才我们装了docker和chrony还有cephadm,deb包会默认存放在
/var/cache/apt/archives目录下,可以把这个目录下的deb包缓存下来,新建一个文件夹,将下载的deb包拷贝到上述新建的文件夹下,并建立deb包的依赖关系
apt-get install dpkg-dev -y
mkdir /offlinePackage
cp -r /var/cache/apt/archives /offlinePackage
chmod 777 -R /offlinePackage/
dpkg-scanpackages /offlinePackage/ /dev/null |gzip >/offlinePackage/Packages.gz
tar zcvf offlinePackage.tar.gz /offlinePackage/
-
修改cephadm脚本
最后需要修改的是cephadm安装脚本,默认安装的时候cephadm是去网上pull镜像,但是实际生产环境是没有外网的,需要修改成直接用本地的镜像,修改_pull_image函数的cmd列表中的pull,将其修改为images。
安装cephadm脚本:
上传cephadm_15.2.17-0ubuntu0.20.04.6_amd64.deb安装包
安装
dpkg -i cephadm_15.2.17-0ubuntu0.20.04.6_amd64.deb
修改/usr/sbin/cephadm安装脚本:

-
开始离线部署
前提条件
Cephadm使用容器和systemd安装和管理Ceph集群,并与CLI和仪表板GUI紧密集成。
- cephadm仅支持octopus v15.2.0和更高版本。
- cephadm与新的业务流程API完全集成,并完全支持新的CLI和仪表板功能来管理集群部署。
- cephadm需要容器支持(podman或docker)和Python 3。(所有节点都需要安装docker和python3)
- 时间同步
基础配置
这里我使用的ubuntu20.04来安装的ceph,已经内置了python3,不再单独安装,不做特殊说明三台服务器都要执行下面的步骤
配置hosts解析
cat >> /etc/hosts <<EOF
192.168.34.133 stor01.kb.cx ceph01
192.168.34.134 stor02.kb.cx ceph02
192.168.34.135 stor03.kb.cx ceph03
EOF
分别在三个节点设置主机名
hostnamectl set-hostname ceph01
hostnamectl set-hostname ceph02
hostnamectl set-hostname ceph03
配置本地源
注意:offlinedeb前面有一个空格,添加[trusted=yes]
tar zxvf offlinePackage.tar.gz -C /
mv /etc/apt/sources.list /etc/apt/sources.list.bak
vi /etc/apt/sources.list
deb [trusted=yes] file:/// offlinePackage/
apt update
安装docker
cd /offlinePackage/archives
dpkg -i containerd.io_1.7.18-1_amd64.deb
dpkg -i docker-ce-cli_5%3a20.10.10~3-0~ubuntu-focal_amd64.deb
dpkg -i docker-ce-rootless-extras_5%3a20.10.10~3-0~ubuntu-focal_amd64.deb
dpkg -i docker-ce_5%3a20.10.10~3-0~ubuntu-focal_amd64.deb
systemctl start docker
systemctl enable docker
导入docker镜像
docker load -i node-exporter.tar
docker load -i alertmanager.tar
docker load -i prometheus.tar
docker load -i ceph.tar
docker load -i grafana.tar
安装cephadm(只需在一台机器安装)
最后需要修改的是cephadm安装脚本,默认安装的时候cephadm是去网上pull镜像,但是实际生产环境是没有外网的,需要修改成直接用本地的镜像,修改_pull_image函数的cmd列表中的pull,将其修改为images。
安装cephadm脚本:
上传cephadm_15.2.17-0ubuntu0.20.04.6_amd64.deb安装包
安装
dpkg -i cephadm_15.2.17-0ubuntu0.20.04.6_amd64.deb
修改/usr/sbin/cephadm安装脚本:

chmod +x cephadm
cp cephadm /usr/bin/
apt install cephadm --allow-unauthenticated
#如果有报错,先执行 apt --fix-broken install
引导新群集
以下操作只在一台节点执行就可以,然运行该命令:ceph bootstrap
cephadm bootstrap --mon-ip 192.168.34.133


安装ceph
cd /offlinePackage/archives
dpkg -i *.deb #执行此命令会将我们之前缓存的包都安装完
添加主机到集群
将公钥添加到新主机
ssh-copy-id -f -i /etc/ceph/ceph.pub ceph02
ssh-copy-id -f -i /etc/ceph/ceph.pub ceph03
https://developer.aliyun.com/article/943314
告诉Ceph,新节点是集群的一部分
[root@localhost ~]# ceph orch host add ceph02
Added host 'ceph02'
[root@localhost ~]# ceph orch host add ceph03
Added host 'ceph03'

部署OSD
可以用以下命令显示集群中的存储设备清单
root@ceph01:/usr/sbin# ceph orch device ls ceph03
Hostname Path Type Serial Size Health Ident Fault Available
ceph03 /dev/sdb hdd 6442M Unknown N/A N/A Yes
root@ceph01:/usr/sbin# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
ceph03 /dev/sdb hdd 6442M Unknown N/A N/A Yes
从特定主机上的特定设备创建 OSD
root@ceph01:/usr/sbin# ceph orch daemon add osd ceph03:/dev/sdb
Created osd(s) 0 on host 'ceph03'
# 使用参数 `unmanaged` 禁用在可用设备上自动创建 OSD
ceph orch apply osd --all-available-devices --unmanaged=true

其他节点的ceph配置
libvirt的rbd存储需要在其他ceph节点上能执行ceph的命令,需要将node1的配置拷贝到node2和node3上
root@ceph01:/usr/sbin# cd /etc/ceph
root@ceph01:/etc/ceph# ls
ceph.client.admin.keyring ceph.conf ceph.pub rbdmap
root@ceph01:/etc/ceph# scp ceph* ceph02:/etc/ceph
root@ceph02's password:
ceph.client.admin.keyring 100% 63 34.4KB/s 00:00
ceph.conf 100% 179 73.9KB/s 00:00
ceph.pub 100% 595 391.9KB/s 00:00
root@ceph01:/etc/ceph# scp ceph* ceph03:/etc/ceph
root@ceph03's password:
ceph.client.admin.keyring 100% 63 13.0KB/s 00:00
ceph.conf 100% 179 104.5KB/s 00:00
ceph.pub 100% 595 354.7KB/s 00:00
root@ceph01:/etc/ceph#
部署MDS
使用 CephFS 文件系统需要一个或多个 MDS 守护程序。如果使用新的ceph fs卷接口来创建新文件系统,则会自动创建这些文件 部署元数据服务器:
ceph orch apply mds *<fs-name>* --placement="*<num-daemons>* [*<host1>* ...]"
CephFS 需要两个 Pools,cephfs-data 和 cephfs-metadata,分别存储文件数据和文件元数据
root@ceph01:/etc/ceph# ceph osd pool create cephfs_data 64 64
pool 'cephfs_data' created
root@ceph01:/etc/ceph# ceph osd pool create cephfs_matedata 64 64
pool 'cephfs_matedata' created
创建一个 CephFS, 名字为 cephfs
root@ceph01:/etc/ceph# ceph fs new cephfs cephfs_matedata cephfs_data
new fs with metadata pool 3 and data pool 2
root@ceph01:/etc/ceph# ceph orch apply mds cephfs --placement="3 ceph01 ceph02 ceph03"
Scheduled mds.cephfs update...
root@ceph01:/etc/ceph# ceph -s
cluster:
id: f6b0f67c-3db6-11ef-b4b9-d505f67b6293
health: HEALTH_WARN
1 failed cephadm daemon(s)
clock skew detected on mon.ceph03, mon.ceph02
Reduced data availability: 129 pgs inactive
Degraded data redundancy: 129 pgs undersized
OSD count 1 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 27m)
mgr: ceph01.euptqy(active, since 97m), standbys: ceph02.nyboos
mds: cephfs:1 {0=cephfs.ceph03.iczyhr=up:creating}
osd: 1 osds: 1 up (since 16m), 1 in (since 16m)
data:
pools: 3 pools, 129 pgs
objects: 0 objects, 0 B
usage: 1.0 GiB used, 5.0 GiB / 6.0 GiB avail
pgs: 100.000% pgs not active
129 undersized+peered
progress:
PG autoscaler decreasing pool 3 PGs from 64 to 16 (5m)
[............................]
root@ceph01:/etc/ceph#
验证至少有一个MDS已经进入active状态,默认情况下,ceph只支持一个活跃的MDS,其他的作为备用MDS
root@ceph01:/etc/ceph# ceph fs status cephfs
cephfs - 0 clients
======
RANK STATE MDS ACTIVITY DNS INOS
0 creating cephfs.ceph03.iczyhr 10 13
POOL TYPE USED AVAIL
cephfs_matedata metadata 0 1602M
cephfs_data data 0 1602M
STANDBY MDS
cephfs.ceph01.qophgp
cephfs.ceph02.nmayjo
MDS version: ceph version 15.2.17 (8a82819d84cf884bd39c17e3236e0632ac146dc4) octopus (stable)
root@ceph01:/etc/ceph#

部署RGW
Cephadm将radosgw部署为管理特定领域和区域的守护程序的集合,RGW是Ceph对象存储网关服务RADOS Gateway的简称,是一套基于LIBRADOS接口封装而实现的FastCGI服务,对外提供RESTful风格的对象存储数据访问和管理接口。
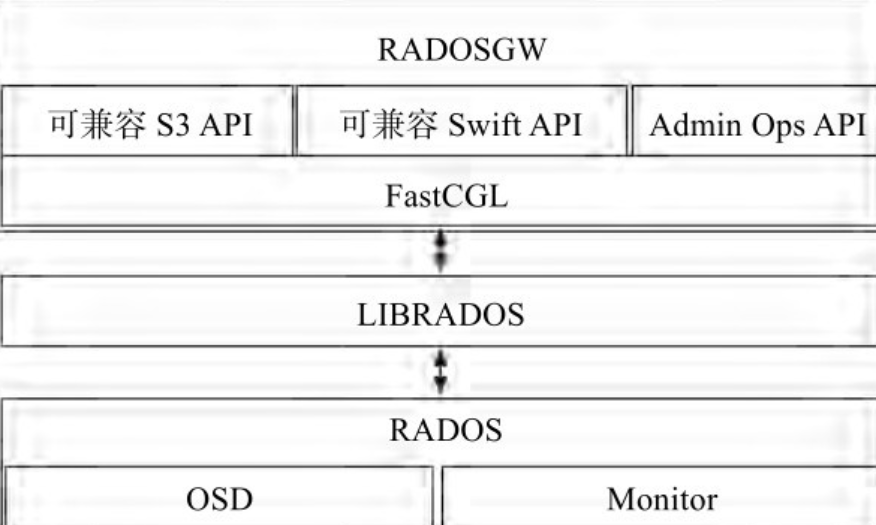
使用 cephadm 时,radosgw 守护程序是通过mon配置数据库而不是通过ceph.conf 或命令行配置的。如果该配置尚未就绪,则 radosgw 守护进程将使用默认设置启动(默认绑定到端口 80)。要在node1、node2和node3上部署3个服务于myorg领域和us-east-1区域的rgw守护进程,在部署 rgw 守护进程之前,如果它们不存在,则自动创建提供的域和区域:
root@ceph01:/etc/ceph# ceph orch apply rgw myorg cn-east-1 --placement="3 ceph01 ceph02 ceph03"
Scheduled rgw.myorg.cn-east-1 update...
或者可以使用radosgw-admin命令手动创建区域、区域组和区域:
radosgw-admin realm create --rgw-realm=myorg --default
radosgw-admin zonegroup create --rgw-zonegroup=default --master --default
radosgw-admin zone create --rgw-zonegroup=default --rgw-zone=cn-east-1 --master --default
radosgw-admin period update --rgw-realm=myorg --commit
可以看到已经创建完成

root@ceph01:/etc/ceph# ceph -s
cluster:
id: f6b0f67c-3db6-11ef-b4b9-d505f67b6293
health: HEALTH_WARN
1 failed cephadm daemon(s)
1 MDSs report slow metadata IOs
clock skew detected on mon.ceph03, mon.ceph02
Reduced data availability: 129 pgs inactive
Degraded data redundancy: 129 pgs undersized
OSD count 1 < osd_pool_default_size 3
services:
mon: 3 daemons, quorum ceph01,ceph03,ceph02 (age 32m)
mgr: ceph01.euptqy(active, since 102m), standbys: ceph02.nyboos
mds: cephfs:1 {0=cephfs.ceph03.iczyhr=up:creating} 2 up:standby
osd: 1 osds: 1 up (since 22m), 1 in (since 22m)
data:
pools: 3 pools, 129 pgs
objects: 0 objects, 0 B
usage: 1.0 GiB used, 5.0 GiB / 6.0 GiB avail
pgs: 100.000% pgs not active
129 undersized+peered
progress:
PG autoscaler decreasing pool 3 PGs from 64 to 16 (10m)
[............................]
root@ceph01:/etc/ceph#
配置RBD Service
8.1 配置rbd
ceph osd pool create rbd 128 128 hdd-rule
ceph osd pool application enable rbd rbd
rbd pool init rbd
# 创建rbd 用户
ceph auth get-or-create client.rbduser mon 'profile rbd' osd 'profile rbd pool=rbd' mgr 'profile rbd pool=rbd'
# output
[client.rbduser]
key = AQA4T9xktgRlGRAAaxh9Czn4DaCliyvzVONsHw==
vim /etc/ceph/ceph.client.rbd.keyring # 将output填入
rbd create --size 512000 rbd/rbd1
rbd ls rbd
rbd info rbd/rbd1
客户端挂载rbd
# 在 rbd 客户端挂载rbd
rbd create foo --size 4096 --image-feature layering # 可选参数 [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring] [-p {pool-name}]
rbd map foo --name client.admin # 可选参数 [-m {mon-IP}] [-k /path/to/ceph.client.admin.keyring] [-p {pool-name}]
mkfs.ext4 -m0 /dev/rbd/rbd/foo
mkdir /rbd
mount /dev/rbd/rbd/foo /rbd
df -h
/dev/rbd0 468M 24K 458M 1% /rbd
root@ceph01:/etc/ceph# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
loop0 7:0 0 63.3M 1 loop /snap/core20/1828
loop1 7:1 0 49.9M 1 loop /snap/snapd/18357
loop2 7:2 0 91.9M 1 loop /snap/lxd/24061
sda 8:0 0 40G 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 2G 0 part /boot
└─sda3 8:3 0 38G 0 part
└─ubuntu--vg-ubuntu--lv 253:0 0 19G 0 lvm /
sr0 11:0 1 1024M 0 rom
rbd0 252:0 0 500M 0 disk /rbd
root@ceph01:/etc/ceph#

设置cephfs
要使用CephFS文件系统,需要一个或多个MDS守护程序。如果使用较新的ceph fs volume 接口创建文件系统,则会自动创建mds。
部署元数据服务器,创建一个CephFS, 名字为cephfs
ceph fs volume create cephfs --placement="3 Node1 Node2 Node2"
# 查看状态
ceph fs volume ls
root@ceph01:/etc/ceph# ceph fs volume ls
[
{
"name": "cephfs"
}
]
ceph orch ps --daemon-type mds
root@ceph01:/etc/ceph# ceph orch ps --daemon-type mds
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
mds.cephfs.ceph01.qophgp ceph01 running (106m) 5m ago 106m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 7f5dfc1e64dd
mds.cephfs.ceph02.nmayjo ceph02 running (38m) 5m ago 106m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 110484575bea
mds.cephfs.ceph03.iczyhr ceph03 running (106m) 5m ago 106m 15.2.17 quay.io/ceph/ceph:v15 93146564743f 19cd85d4a27a
root@ceph01:/etc/ceph#
ceph fs status cephfs
root@ceph01:/etc/ceph# ceph fs status cephfs
cephfs - 0 clients
======
RANK STATE MDS ACTIVITY DNS INOS
0 active cephfs.ceph03.iczyhr Reqs: 0 /s 10 13
POOL TYPE USED AVAIL
cephfs_matedata metadata 1280k 5560M
cephfs_data data 0 4802M
STANDBY MDS
cephfs.ceph01.qophgp
cephfs.ceph02.nmayjo
MDS version: ceph version 15.2.17 (8a82819d84cf884bd39c17e3236e0632ac146dc4) octopus (stable)
root@ceph01:/etc/ceph#
ceph mds stat
root@ceph01:/etc/ceph# ceph mds stat
cephfs:1 {0=cephfs.ceph03.iczyhr=up:active} 2 up:standby
root@ceph01:/etc/ceph#
# 将cephfs的数据文件放到hdd上,元数据放到ssd上
ceph osd pool set cephfs.cephfs.data crush_rule hdd-rule
ceph osd pool set cephfs.cephfs.meta crush_rule ssd-rule
参考文档
