
从零开始打造完整评分系统
1. 概述
大多数的网站都需要一个评分系统,来考量该网站条目的质量,例如时光网:

那么在本文中,我们就来学着如何打造一个可用的评分系统。
2. 构建简单的评分系统
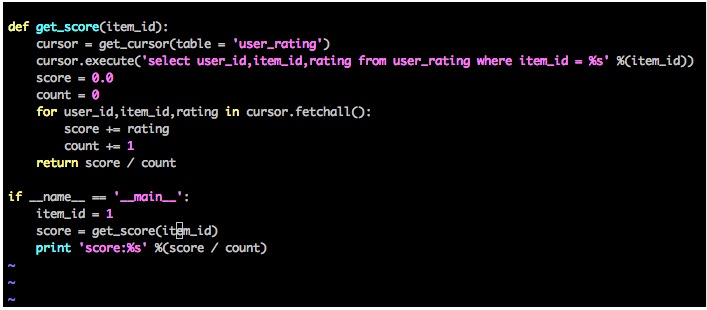
其实最初做一个评分系统很简单,我们首先先设计评分系统所需要的数据表,即用户评分表(user_rating):
CREATE TABLE `user_rating` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`user_id` int(11) DEFAULT NULL,
`item_id` int(11) DEFAULT NULL,
`rating` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
接下来只需要计算一个简单的平均数即可:
3. 从搜索引擎说起
我们先不考虑评分系统,让我们先来简单回顾下搜索引擎发展的历史吧。
1994年,杨致远和David创办了Yahoo!,标志着现代搜索引擎的开始,但是Yahoo其实并不能算一个真正意义上的搜索引擎,因为他的很多网页大部分都是人工增加的,我们不妨将之称为“网站收录集”。
随着互联网上网站越来越多,人工已经没有办法负载这么大的工作量了,于是出现了一种全文检索的技术,用户输入关键词,然后搜索引擎去网页中去搜索这些词,然后返回给用户。
其实这种方式很好,可是不幸地是,网站赖以生存的就是PV和点击量,于是有很多网站不择手段地堆砌关键字,做着所谓的SEO。
互联网于是开始陷入混乱时期。
这时候,1997年Google成立,引入了著名的Page-rank算法,很大程度解决了这一问题,也成为了搜索引擎发展的一个里程碑。而Page-rank的概念,也第一次让Collective Intelligence(集体智慧)飞入了寻常百姓家。
4. 什么是集体智慧
我们先去Wiki上看一下相关的定义:
Collective intelligence is a shared or group intelligence that emerges from the collaboration and competition of many individuals and appears in consensus decision making in bacteria[clarification needed], animals, humans and computer networks.
我们简要地来说:集体智慧是一种共享的或者是群体的智能,是由许多个体通过协作与竞争中体现出来的智能。也许这么说依然很抽象,我们来举一个现实中例子:当你想买一个笔记本的时候,你会去问你的朋友,这个笔记本怎么样怎么样,然后综合了很多人的意见之后,你会做出自己的决策,那么这一个过程就是集体智慧的体现。
接下来让我们回到条目评分的例子上来,用电影来说,当刚刚上映了一部电影的时候,你怎么知道你是否要去看这个电影,最简单的办法就是你去网上看看大家对这部电影的评分怎么样,也许一个人两个人的口味和你不大一样,但是综合了很多人的意见之后,这个电影的评分就很有意义了,算法也如我们在第二节中提到的,取平均分即可。
5. PageRank算法
PageRank,在SEO领域,我们常称之为PR值,我们也常常用PR值来作为一个网站权威性的度量方式。
这个算法基于一个前提假设,他认为权威的网站大家都会去指向他,而权威的网站指向的则一定也是权威的网站。那么简单来说,我们可以认为,被指向越多的网站,他的权重也就越高。另外,一个页面也只能为其他的页面投一票,如果某网页指向了N个网站,那么每个网站其实只被投了1/N票。
所以我们可以得出这样的一个简单的公式:
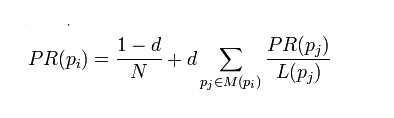
PR(x)为某网页的PageRank,L(x)为该网页只想外站的链接个数,而1-q则为系统为每个网页赋予的最小Rank值。
转换成矩阵运算极为这样的格式:

接下来,系统便开始迭代计算,直到整个系统的PR值都收敛到了某一个值为止。
我们将之反映成代码(使用R语言):

这里我们将最大的迭代次数设置为100次。
此外,PageRank算法还引入了基尼系数的概念,并且也对性能,以及一些参数的细节做了很大的调整,在这里我们并不深究,了解即可。
5. Page_rank vs. 关键词匹配
还记得我们在第三节中说过,关键词匹配是一个很好的方式,他被PageRank所击败很大程度上是因为垃圾网页的出现。
其实对于评分系统也是一样,无论对于读书电影的条目,还是对于商品的评分,都有着巨大的商业价值,所以我们再也不能依赖于平均分,而需要也模仿Page-rank来对每个User引入Rank的概念。
6. 计算UserRank
我们想一下PageRank的意义,就是衡量一个网页的重要程度,那么把PageRank的思想完整的迁移到UserRank上,那么也就是说UserRank衡量的是一个User的重要程度。
那么我们如何衡量用户的重要程度,在评分系统中,我认为Rank的意义在于用户的品味,在电影评分中,我们认为每个用户的权重取决于用户的电影品味,而读书中取决与用户的读书品味。
所以接下来,我们将整个评分系统的计算分成两步:
A. 计算User-Rank
B. 计算条目评分
这里我们采用迭代逼近的方式来计算用户的权重。等同于PageRank算法,我们首先认为每个用户的权重是等同的,那么其实条目的评分就是所有用户的平均分。
在任何算法中,我们都需要基于一个前提假设,这是算法和数据挖掘领域的前提,那么这里我们做的前提假设是:与大众品味接近,则代表该用户的评分影响力更大,即权重更高。
所以我们来进行第一次迭代,一个简单的方式,即比较该用户所有条目的评分 与 其对应条目当前分数的皮尔逊相关度。

迭代之后,我们即能得出每个用户的皮尔逊相关度,这个相关度我们便认为是该用户本次迭代后的权重,由于可能会出现负相关,所以我们认为负相关应该为0,即:

接下来我们再次根据该权重来重新计算本次迭代后条目的评分:

每次迭代后,我们都可以计算出本次迭代后,与上次迭代后条目评分之间的差距:

我们一般认为当两次迭代后的条目评分差距小于某一阈值时,我们称之为结果是可收敛的。
但是在一般的工程型实践中,例如有5000W的用户和2000W的条目,每次迭代都需要耗费极大的时间,所以我们需要采取一些取巧的方式。
7. 评分系统的工程性实践
一般意义上,我们可能会采用如下两种方式的优化:
A. 减少条目的数量。我们知道2-8法则,其实这一法则大多数情况下也适用于评分系统,80%的评分都是来自于20%的条目,所以我们只需要选出这20%的条目,或者更少的有代表性的条目,就可以使每次迭代的计算量大大减小。
B. 指定迭代次数。 就像我之前在R代码中计算PageRank一样,我们可以人为地指定迭代次数,而不用等待完全收敛。
8. UserRank算法的意义
我们说PageRank算法的诞生极大地减少了垃圾网页的数量,那么UserRank的意义何在呢?
我们将Spammer分成两种,
A. 恶意评分,例如恶意地去刷高软件评分,电影评分等等,那么他们的典型特征是给某一批条目或者很高或者很低的评分,那么他们必然会和大部分用户的平均分相背离,于是他们的Rank会很低。
B. 扰乱秩序,他们并非恶意地去刷高或者刷低评分,他们只是用网站的评分作为玩笑而已,那么该算法也能起到弱化该行为的目的。
9. Rank是否真的能够代替Anti-spammer
之前我们提到PageRank有效地防止了垃圾网页的产生,但是道高一尺魔高一丈,Spammer也想出了很多办法来遏制PageRank算法,例如建很多垃圾站,然后互相做内链。
但是Google不会被这样的行为所击倒,是因为他们的算法不只只是PageRank(我甚至怀疑他们是否在用PageRank),还有着优异的Anti-spammer算法。同样,在工程化实践中,很多论文上的算法都希望借助于Rank算法来抵制Spammer行为,但是我一直认为Rank仅仅应该反映的是用户的品味,反映的是该用户与大众品味的相似程度。而在Rank的前一层,应该存在着Anti-spammer算法来识别出Spammer用户。
在不同的网站,有着不同的识别方法,简单地有只是通过ip地址来识别出垃圾用户,复杂地有通过行为属性做机器学习来识别出垃圾用户。这也不归结于本文的范畴了。
10. 综述
几乎大部分存在条目的网站都需要一个评分系统来辅助用户做选择,这不但可以为用户提供一个消费的参考,也可以为网站内部的数据做一个良好的支撑作用(例如最受用户好评的TOP10)。
那么本文介绍了如何通过计算UserRank来打造出一个几乎算是完整的评分系统,希望可以对大家有所帮助。

