
NLTK的使用
安装nltk.参考:http://www.cnblogs.com/kylinsblog/p/7755843.html
NLTK是Python很强大的第三方库,可以很方便的完成很多自然语言处理(NLP)的任务,包括分词、词性标注、命名实体识别(NER)及句法分析。
下面介绍如何利用NLTK快速完成NLP基本任务
一、NLTK进行分词
用到的函数:
nltk.sent_tokenize(text) #对文本按照句子进行分割
nltk.word_tokenize(sent) #对句子进行分词
#!/usr/bin/python # -*- coding: UTF-8 -*- print('nlp2 test') import nltk text = 'PathonTip.com is a very good website. We can learn a lot from it.' #将文本拆分成句子列表 sens = nltk.sent_tokenize(text) print(sens) #将句子进行分词,nltk的分词是句子级的,因此要先分句,再逐句分词,否则效果会很差. words = [] for sent in sens: words.append(nltk.word_tokenize(sent)) print(words)
执行结果:

二、NLTK进行词性标注
用到的函数:
nltk.pos_tag(tokens)#tokens是句子分词后的结果,同样是句子级的标注
tags = [] #词性标注要利用上一步分词的结果 for tokens in words: tags.append(nltk.pos_tag(tokens)) print(tags)
执行结果:

三、NLTK进行命名实体识别(NER)
用到的函数:
nltk.ne_chunk(tags)#tags是句子词性标注后的结果,同样是句子级
#!/usr/bin/python # -*- coding: UTF-8 -*- print('nlp3 test') import nltk text = 'Xi is the chairman of China in the year 2013.' #分词 tokens = nltk.word_tokenize(text) #词性标注 tags = nltk.pos_tag(tokens) print(tags) #NER需要利用词性标注的结果 ners = nltk.ne_chunk(tags) #print('%s---%s' % (str(ners),str(ners.node))) #报错,无解 #还是直接打印tree吧 print(ners)
执行结果:
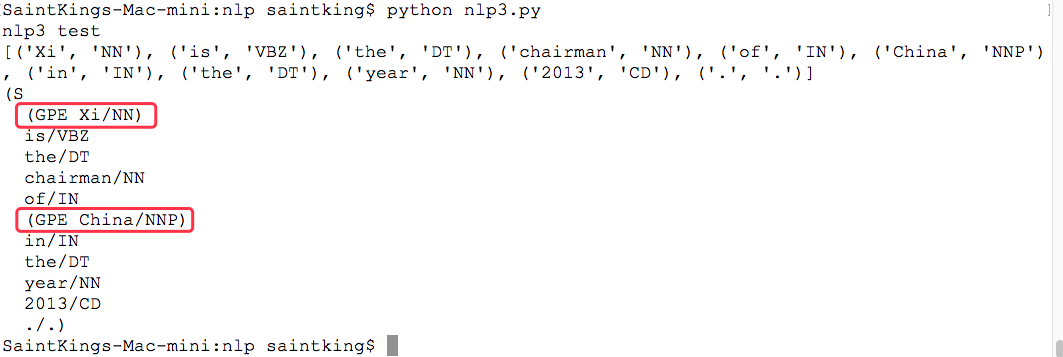
上例中,有两个命名实体,一个是Xi,这个应该是PER,被错误识别为GPE了; 另一个事China,被正确识别为GPE。
四、句法分析
nltk没有好的parser,推荐使用stanfordparser
但是nltk有很好的树类,该类用list实现
可以利用stanfordparser的输出构建一棵python的句法树
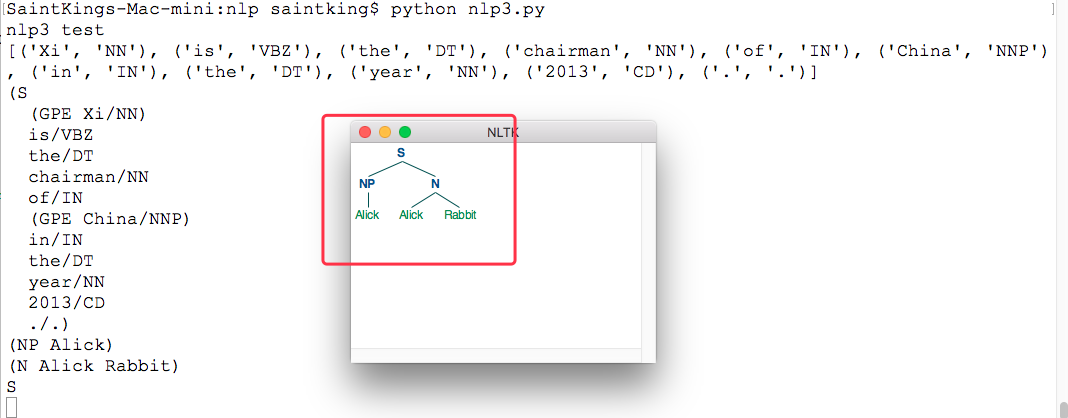
#报错,无解 #tparse = nltk.tree.Tree.parse #修改 #tree = tparse('(NP (DT the) (JJ fat) (NN man))') #tree = nltk.Tree('NP','DT') #for subtree in tree: # print(subtree,'---',subtree.node) tree1 = nltk.Tree('NP',['Alick']) print(tree1) tree2 = nltk.Tree('N',['Alick','Rabbit']) print(tree2) tree3 = nltk.Tree('S',[tree1,tree2]) print(tree3.label()) #查看树的结点 tree3.draw()
执行结果:
用双手改变人生,用代码改变世界!
| 微信 | Kylin开发技术交流群 | |||
 |
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号