软工实践寒假作业(2/2)
| 这个作业属于哪个课程 | 2020春|S班 (福州大学) |
|---|---|
| 这个作业要求在哪里 | 软工实践寒假作业(2/2) |
| 这个作业的目标 | 开发一个疫情统计程序 |
| 作业正文 | 软工实践寒假作业(2/2) |
| 其他参考文献 |
1. Github仓库地址。
InfectStatistic-main
2. # PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 40 |
| Estimate | 估计这个任务需要多少时间 | 30 | 40 |
| Development | 开发 | 960 | 600 |
| Analysis | 需求分析 (包括学习新技术) | 70 | 85 |
| Design Spec | 生成设计文档 | 20 | 10 |
| Design Review | 设计复审 | 10 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 90 |
| Design | 具体设计 | 200 | 180 |
| Coding | 具体编码 | 360 | 400 |
| Code Review | 代码复审 | 60 | 50 |
| Test | 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | 120 | 200 |
| Test Repor | 测试报告 | 40 | 50 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 1140 | 840 |
3. 解题思路描述。
- 首先了解如何使用命令行选项和参数,学会了命令行传递参数并在程序中使用参数
- 选择用于存放疫情的数据的数据结构,用于统计和最后输出统计结果,选择了Map存放。
- 确定思路,根据日期来确定需要统计的日志文件,确定如恶化统计单个日志文件,确定如何处理单个日志文件的每一行记录。
- 从全局细分到日志文件的一行记录,处理好每一行记录,并处理好每个日志文件,并统计好全部的记录存放在数据结构里面,最后根据需要统计的省份和类型输出对应数据到输出文件即可。
4.实现过程。
大概的实现流程如图:


5. 代码说明。展示出项目关键代码,并解释思路。
- 首先是处理日志文件的代码,首先确定是否是需要的日志文件,然后将日志文件的文件名进行日期格式转换,转换成我们规定的日期格式,然后通过日期类已经分装好的方法进行判断日期合法性,判断日期大小,当该文件日期在我们所需要的日期之前,那么我们就将该文件进行处理统计。
public void dealLogs() {
if (log == null) {
System.out.println("请输入正确的日志地址!");
System.exit(-1);
}
File file = new File(log);
if (file.isDirectory() && file.list() != null) {
File[] files = file.listFiles();
if (files != null)
for (File aFile : files) {
String[] splitName = aFile.getName().split("\\.");
if (aFile.isFile() && splitName.length > 2 && splitName[1].equals("log")) {
if (date != null) {
try {
Date fileDate = sdf.parse(splitName[0]);
if (fileDate.before(date) || fileDate.equals(date)) {
caculateLogs(aFile);
}
}
catch (ParseException pE) {
}
}
else {
caculateLogs(aFile);
}
}
}
}
else {
System.out.println("请输入正确的日志地址!");
System.exit(-1);
}
}
- 单个文件的处理,我们读取每一行,就可以进行一行行地统计,统计一行,首先是根据日志的特征,以空格分离提取出数据存放在字符串数组中,然后判断字符串数组的长度,依据日志分析,把每行分为长度为3、4、5的长度分别进行处理,避免需要处理很多种情况带来的代码冗余。那么使用Map的好处,我们可以直接根据省份的名字,得到对应的存放数据的整数数组,然后拿出来进行与获得的人数进行操作数操作即可。当遍历完所有的需要处理的日志文件,那么数据就处理完并保存在数据结构总了。
private void caculateLogs(File file) {
try {
BufferedReader br = new BufferedReader(new InputStreamReader(new FileInputStream(file)));
String dataLine;
while ((dataLine = br.readLine()) != null) {
String[] words = dataLine.split("\\s+");
if (status.containsKey(words[0])) {
int[] tempStatus = status.get(words[0]);
if (words.length == 3) {
int num = Integer.parseInt(words[2].substring(0, words[2].indexOf("人")));
if (words[1].equals("死亡") && num > 0) {
tempStatus[ip] -= num;
tempStatus[dead] += num;
internal[ip] -= num;
internal[dead] += num;
status.put(words[0], tempStatus);
}
else if (words[1].equals("治愈") && num > 0) {
tempStatus[ip] -= num;
tempStatus[cure] += num;
internal[ip] -= num;
internal[cure] += num;
status.put(words[0], tempStatus);
}
}
......//其他情况类似
- 根据处理好的数据结构,我们最后输出到文件就可以了。值得注意的是,我们根据-province和-type命令行选项的对应参数的有无,可以分为四种情况,即有省份参数有类型参数,有省份参数无类型参数,有省份参数有类型参数,无省份参数无类型参数,而且每一种情况都得分别处理,并且无法放在一起处理,因为每一种需要获取的数据都是不一样的。这里就需要考虑一件事情,这四种情况的判断要放在处理每个文件的每一行数据就处理吗?当文件数少,日志文件小的时候,这样处理是没有什么影响的,但命令行输入的时候就确定的四种情况之一,在分析每一行日志的时候都需要判断,四种情况又要分别处理对应的数据,那么会造成大量的相似代码冗余。因此我这里是将这样的情况放在输出文件的时候输出,也就是刚开始就将每个省份的数据都保存起来,因为在读取每一行日志文件的时候,如果不存起来,就需要进行各种情况判断,判断是不是需要的省份,判断是不是流入的省份,判断是不是需要的类型等问题,加大解题的问题量。因此我把所有的数据都保存起来,最后要输出的时候根据已存在数据结构的数据提取需要的数据即可。并且这样做还有个好处,该程序可以优化成一个用于查询的程序,当数据库数据很多的时候,我们可以根据需要的筛选类型,快速地找出我们需要的数据。
......
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(new FileOutputStream(file)));
String dataLine;
if (province == null && type == null) {
for (String provin : provinces) {
int[] tempStatus = status.get(provin);
dataLine = String.format("%s 感染患者%d人 疑似患者%d人 治愈%d人 死亡%d人\n", provin,
tempStatus[ip], tempStatus[sp], tempStatus[cure], tempStatus[dead]);
bw.write(dataLine);
}
bw.close();
}
else if (province != null && type == null) {
int i = 0;
while (province[i] != null) {
if (status.containsKey(province[i])) {
int[] tempStatus = status.get(province[i]);
dataLine = String.format("%s 感染患者%d人 疑似患者%d人 治愈%d人 死亡%d人\n", province[i],
tempStatus[ip], tempStatus[sp], tempStatus[cure], tempStatus[dead]);
bw.write(dataLine);
}
i++;
}
bw.close();
}
......
- 以下有个细节,就是巧妙地将我们数据结构里面的数据,从int[]数组变成我们需要输出到文件的Sting[],那么根据我们输入的-type对应的可选参数有4个,根据组合排序,可能出现的输入参数类型情况就有432*1=24种,我们要根据输入的参数次序依次输出到统计文件中,那么我们需要每种情况都处理吗? 这里我巧妙地根据输入的参数的长度分为四种情况,即对应输入-type的参数为1-4个,例如当为1时,我们只需要输出对应的字符串即可,不需要知道输入的一个参数是ip|sp|cure|dead,多个参数的时候也不需要考虑参数组合的问题,只需要依次输出。
for (String provin : provinces) {
int[] tempStatus = status.get(provin);
String[] intToSring = new String[]{"感染患者" + tempStatus[ip] + "人", "疑似患者" + tempStatus[sp]
+ "人", "治愈" + tempStatus[cure] + "人", "死亡" + tempStatus[dead] + "人"};
if (needTypes == 1) {
dataLine = String.format("%s %s\n", provin, intToSring[type[0]]);
}
else if (needTypes == 2) {
dataLine = String.format("%s %s %s\n", provin, intToSring[type[0]], intToSring[type[1]]);
}
else if (needTypes == 3) {
dataLine = String.format("%s %s %s %s\n", provin, intToSring[type[0]], intToSring[type[1]],
intToSring[type[2]]);
}
else if (needTypes == 4) {
dataLine = String.format("%s %s %s %s %s\n", provin, intToSring[type[0]], intToSring[type[1]],
intToSring[type[2]], intToSring[type[3]]);
}
else {
dataLine = "";
}
bw.write(dataLine);
}
6. 单元测试截图和描述。
本次一共进行了15个单元测试,其中包括输出测试和容错处理测试
测试选项 -log 和 -out
准确性测试
测试正确输入位置进行的疫情统计
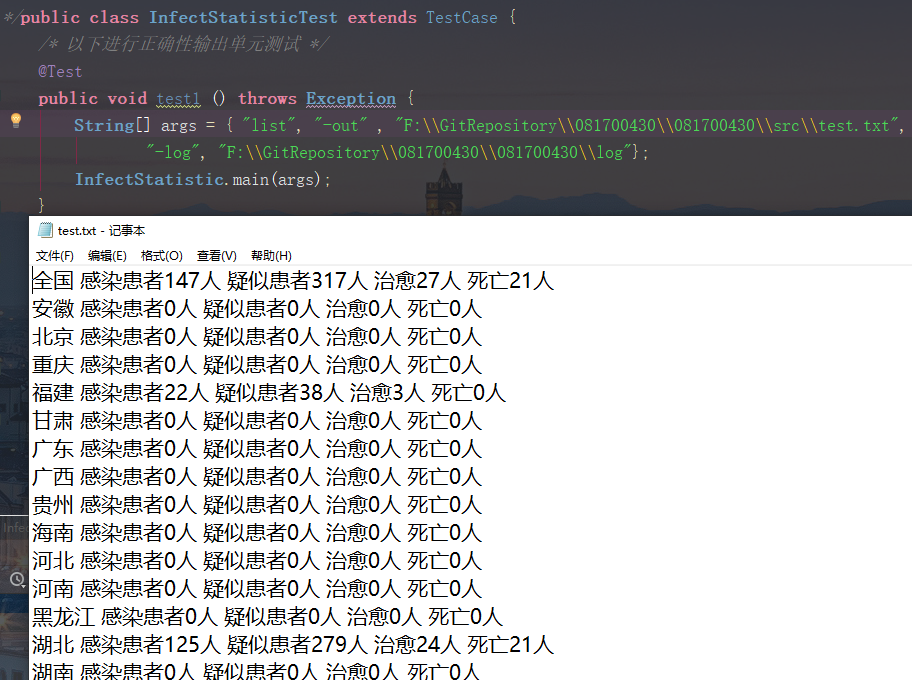
测试更换输入参数位置进行的疫情统计

容错性测试
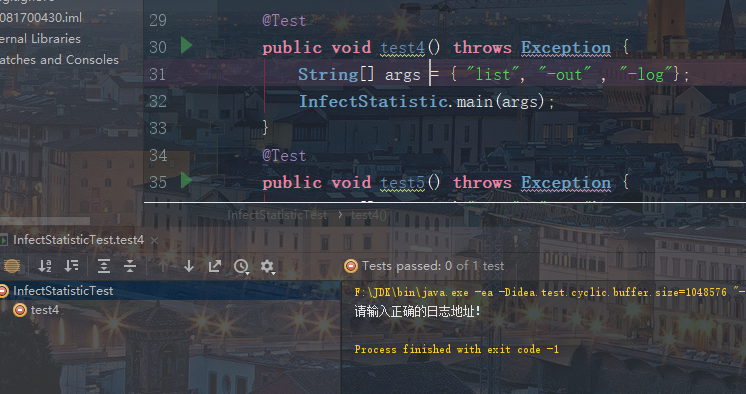
日志路径输入错误测试:
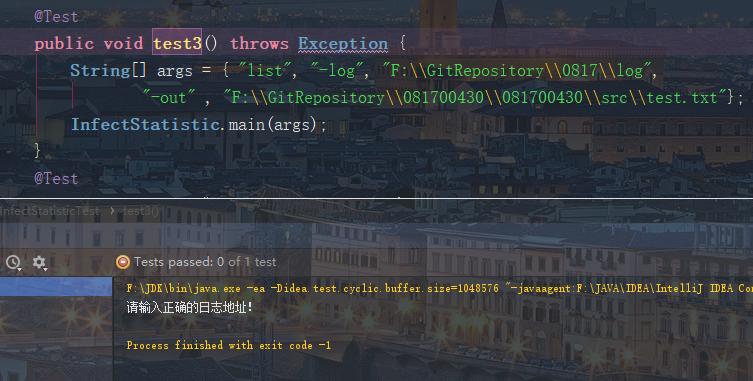
未输入路径测试

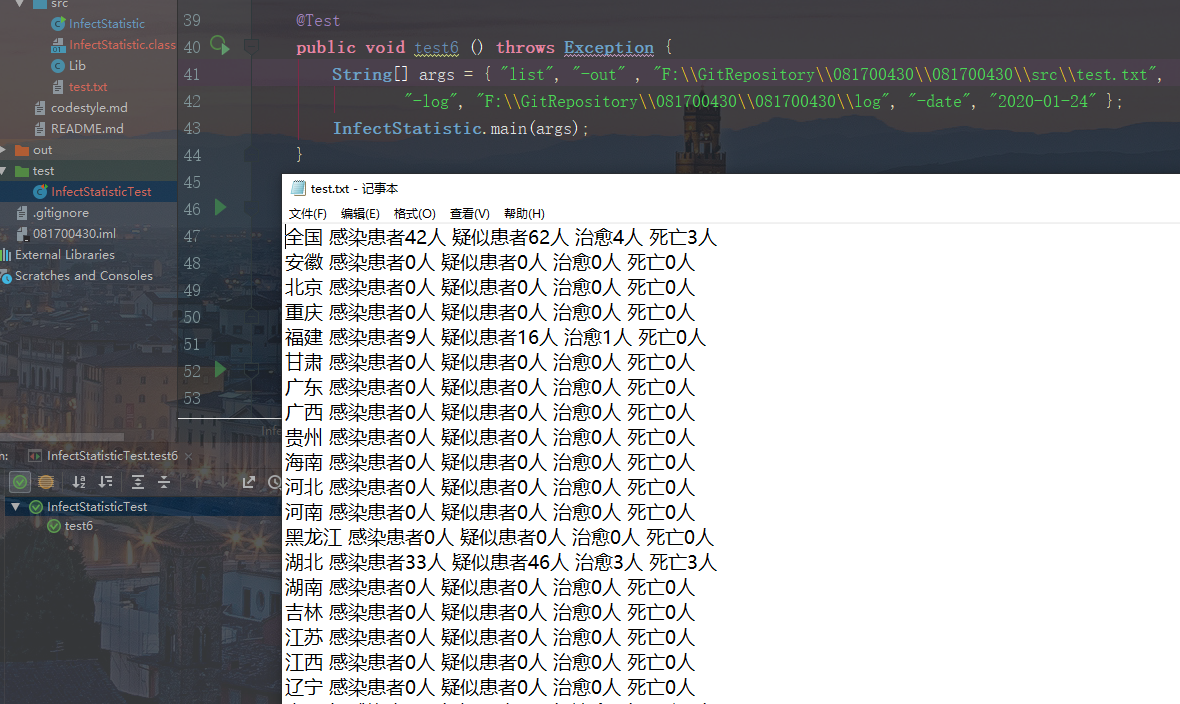
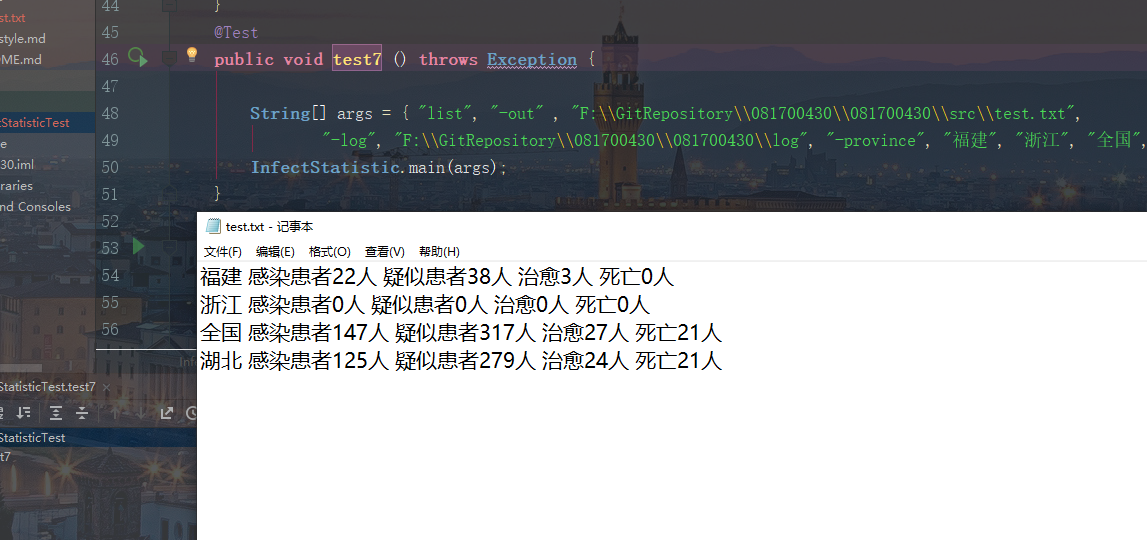
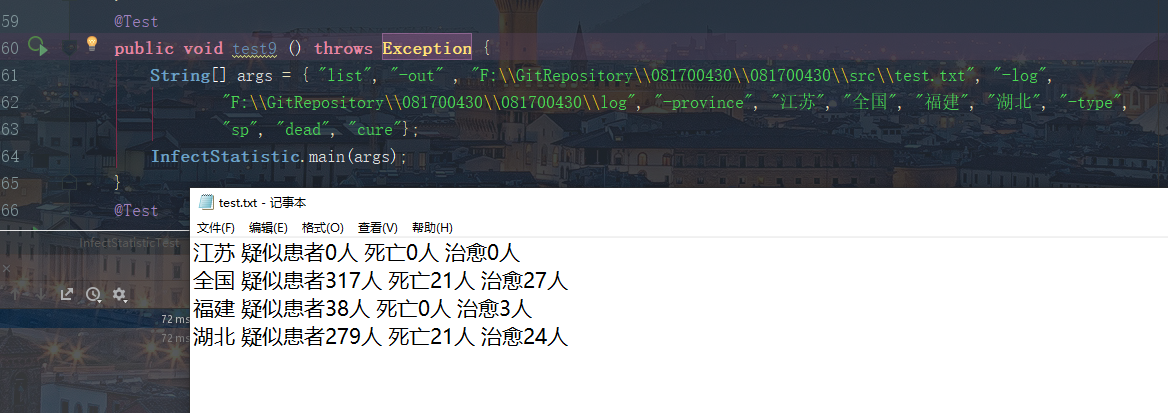
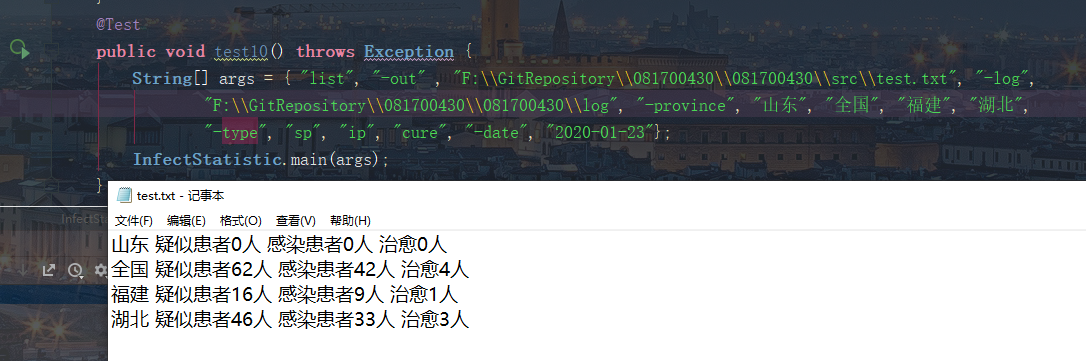
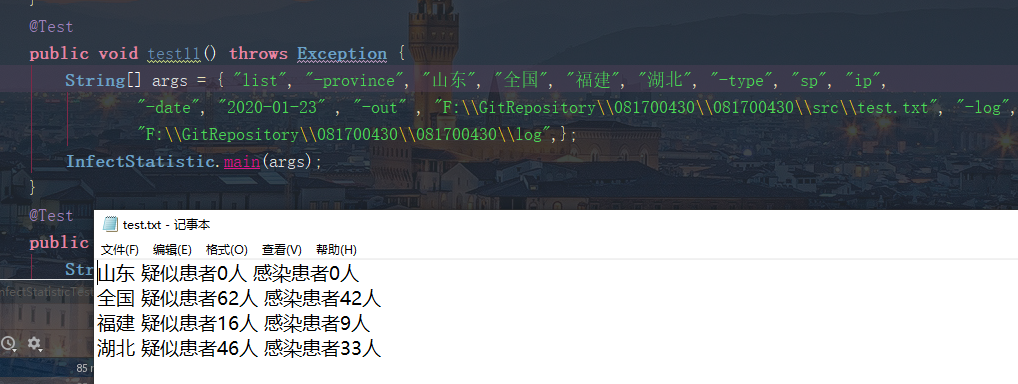
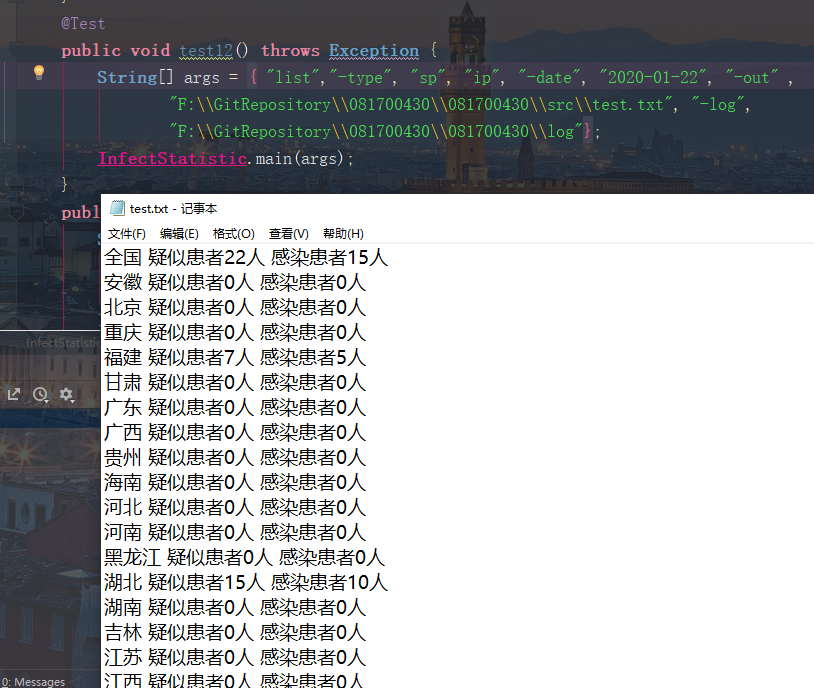
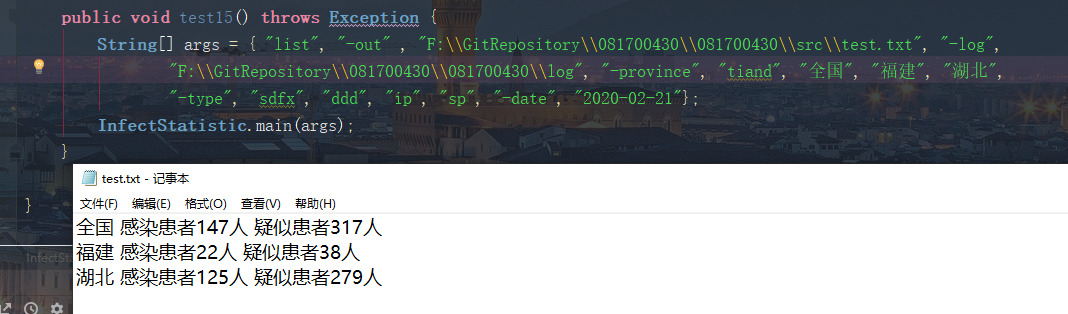
测试选项 -date、-province、-type的组合测试
准确性测试
测试正确组合三个选项参数,进行多种组合都没有问题,并且各个选项和参数的输入位置不影响程序正确执行,并能够根据合理的输入顺序输出文件。

 #### 容错性测试
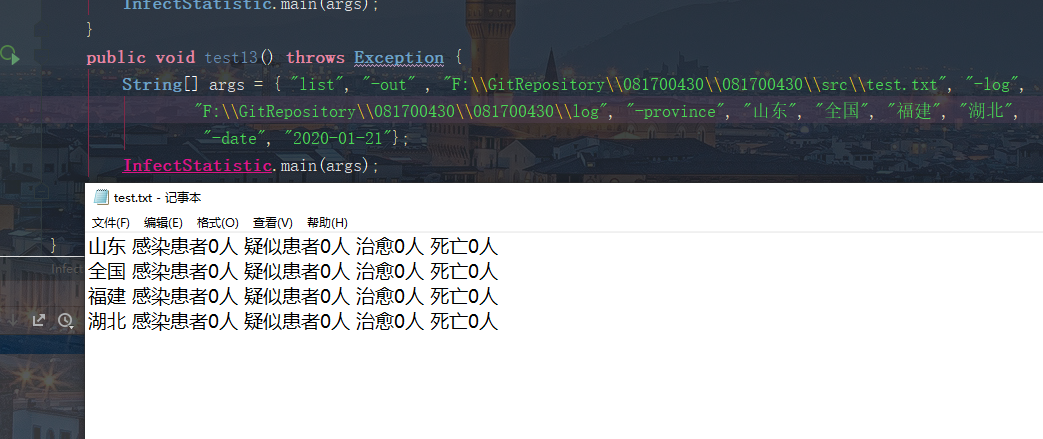
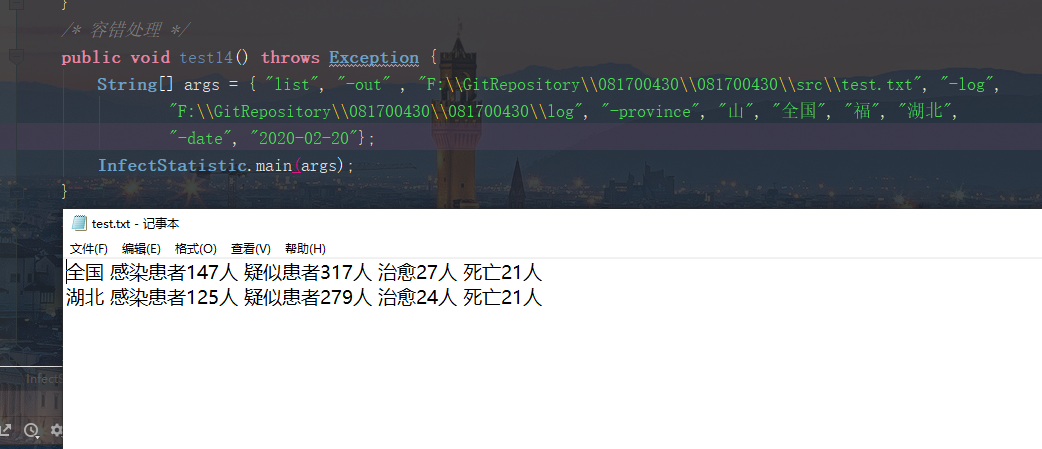
##### 说明:当进行省份参数输入的省份错误时,输出文件掠过输错省份,当输入的类型参数输入不和要求,该参数将不会出现在输出文件中。
#### 容错性测试
##### 说明:当进行省份参数输入的省份错误时,输出文件掠过输错省份,当输入的类型参数输入不和要求,该参数将不会出现在输出文件中。
 # 7. 单元测试覆盖率优化和性能测试,性能优化截图和描述。
## 单元测试的覆盖率:
# 7. 单元测试覆盖率优化和性能测试,性能优化截图和描述。
## 单元测试的覆盖率:
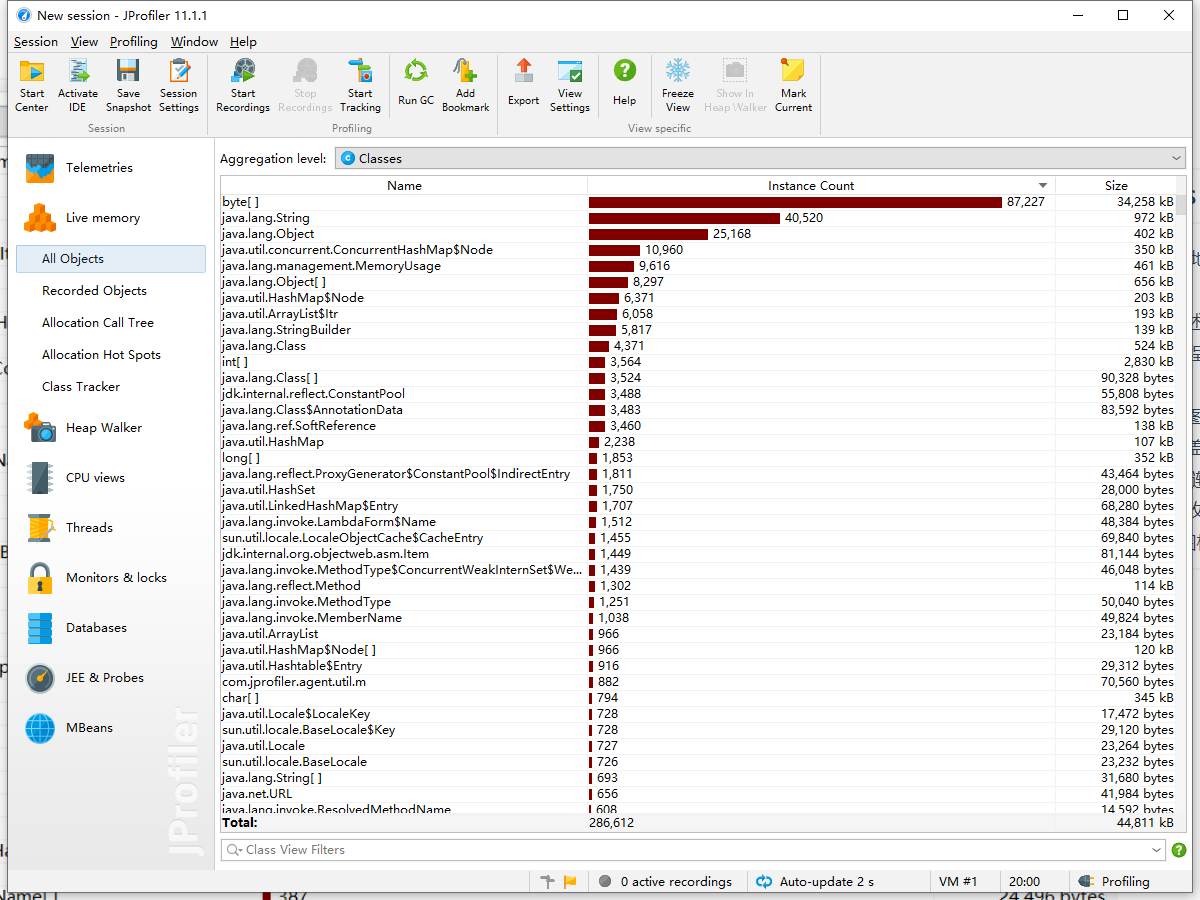
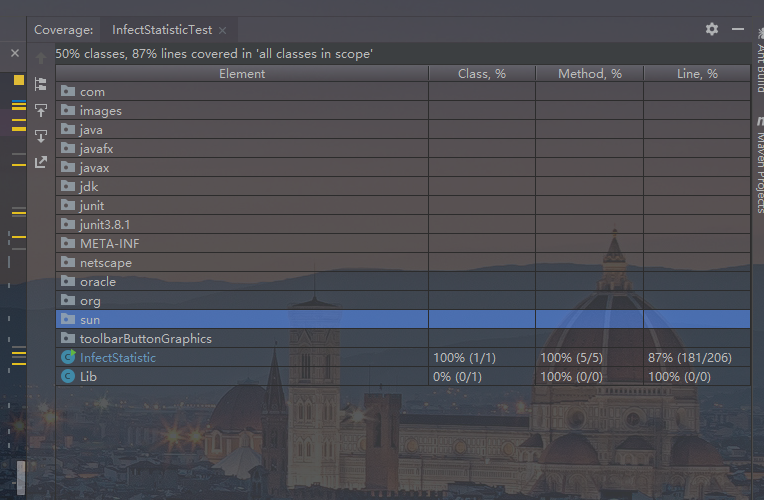 ## 单元测试的性能测试(整体偏大,但是基于很大的数据量的情况下相对会有一定优化):
## 单元测试的性能测试(整体偏大,但是基于很大的数据量的情况下相对会有一定优化):
 # 8. 代码规范的链接
### [codestyle](https://github.com/kylin773/InfectStatistic-main/blob/master/081700430/codestyle.md)
# 9. 解决项目的心路历程与收获
- 此次解决项目过程中遇到好多问题,在编码中就出现了很多问题,首先考虑数据结构,要使用二维数组呢还是使用别的数据结构?参数会出现的情况很多,该如何优化代码,避免冗余代码行数在做重复的东西,首先提取一个共共的函数是不太可靠的,因为不一样或者参数组合情况处理数据的方法就不一样,都需要进行判断,难以提取公共函数,那怎么办?遇到需要存储到数据结构内容可以根据参数来定制,但是需要大量做判断的情况下,和需要存储所有省份的数据,但是可以避免在文件中做大量复杂情况的分类的判断,这时我该怎么权衡?因此在了解这些问题的存在的时候,我有在考虑代码该如何优化,如何考虑使用怎样的方法去解决问题,而不是想到什么代码就敲什么代码,只为了完成编码,实现功能而去敲代码,对代码有更多的考虑。
- 对于代码规范,在我大二暑期实习的时候就感受到过代码规范的重要性,并且当时的实习导师还让我根据公司的编码规范,找出公司已经投入使用的代码的规范问题,并解决代码不规范的问题,然后这次看了别的公司的代码规范,发现好的代码规范,其实很多都很类似的,几乎有一套很好的代码规范体系,并且在平时的编码中都遵循或者清楚明确的话,到以后代码敲多了,自然就养成了良好的习惯。良好的代码规范让人看着舒服,我也写下了我遵循的大概的代码规范。
- 当然,在编码解决问题的同时,还会遇到在编码的过程中带来的一系列相关技术的使用问题,比如Jprofiler软件的使用,结合IDEA,我仍然不是很熟悉该专业代码分析软件是如何运行,以及该如何合理的利用该软件来分析代码?利用Juit的时候,怎么样进行单元测试才是合理的?在github的使用上,我将老师仓库的代码clone下来并且在自己的github发布了自己创建的仓库,并且在代码完成后才发现,我想要pr代码到老师的代码的仓库下,但是这时候却没有办法,我解决了好久仍然没有解决,甚至在编写该博客的时候也还没完成,我的思路是fork了老师代码,然后再老师代码上新建了我的代码分支,然后将两份代码合并,但是合并后代码却无法使用github destop进行push到我的remote上面。这也算经历了崩溃,也尝试了网上各种方法,仍然需要解决。
# 8. 代码规范的链接
### [codestyle](https://github.com/kylin773/InfectStatistic-main/blob/master/081700430/codestyle.md)
# 9. 解决项目的心路历程与收获
- 此次解决项目过程中遇到好多问题,在编码中就出现了很多问题,首先考虑数据结构,要使用二维数组呢还是使用别的数据结构?参数会出现的情况很多,该如何优化代码,避免冗余代码行数在做重复的东西,首先提取一个共共的函数是不太可靠的,因为不一样或者参数组合情况处理数据的方法就不一样,都需要进行判断,难以提取公共函数,那怎么办?遇到需要存储到数据结构内容可以根据参数来定制,但是需要大量做判断的情况下,和需要存储所有省份的数据,但是可以避免在文件中做大量复杂情况的分类的判断,这时我该怎么权衡?因此在了解这些问题的存在的时候,我有在考虑代码该如何优化,如何考虑使用怎样的方法去解决问题,而不是想到什么代码就敲什么代码,只为了完成编码,实现功能而去敲代码,对代码有更多的考虑。
- 对于代码规范,在我大二暑期实习的时候就感受到过代码规范的重要性,并且当时的实习导师还让我根据公司的编码规范,找出公司已经投入使用的代码的规范问题,并解决代码不规范的问题,然后这次看了别的公司的代码规范,发现好的代码规范,其实很多都很类似的,几乎有一套很好的代码规范体系,并且在平时的编码中都遵循或者清楚明确的话,到以后代码敲多了,自然就养成了良好的习惯。良好的代码规范让人看着舒服,我也写下了我遵循的大概的代码规范。
- 当然,在编码解决问题的同时,还会遇到在编码的过程中带来的一系列相关技术的使用问题,比如Jprofiler软件的使用,结合IDEA,我仍然不是很熟悉该专业代码分析软件是如何运行,以及该如何合理的利用该软件来分析代码?利用Juit的时候,怎么样进行单元测试才是合理的?在github的使用上,我将老师仓库的代码clone下来并且在自己的github发布了自己创建的仓库,并且在代码完成后才发现,我想要pr代码到老师的代码的仓库下,但是这时候却没有办法,我解决了好久仍然没有解决,甚至在编写该博客的时候也还没完成,我的思路是fork了老师代码,然后再老师代码上新建了我的代码分支,然后将两份代码合并,但是合并后代码却无法使用github destop进行push到我的remote上面。这也算经历了崩溃,也尝试了网上各种方法,仍然需要解决。
10. 相关技术学习
- mybatis
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Ordinary Java Object)映射成数据库中的记录。 - Maven
Apache Maven is a software project management and comprehension tool. Based on the concept of a project object model (POM), Maven can manage a project's build, reporting and documentation from a central piece of information. - spring
spring的框架 - JaveEETest
总结了一些Spring、SpringMVC、MyBatis、Spring Boot案例 - JAVAWeb-Project
初学JAVA-WEB开发的小项目,也适合初学者进行练习
11. 解决无法pull requests到fork过来仓库的办法(保持commit日志记录存在)
(可能出现原因:当你fork一个项目并clone到本地,然后你复制了一些文件,并且自己创建了一个仓库,此时和原来的仓库已经无关了,并且多次commit并完成了项目,
但是后面你发现你可能要pr该项目到原来的作者那,那此时你可以使用下面这个方法。我的个人原因:因为刚开始不明白pr规则,只把代码拷贝下来并进行修改,然后后面需要保留commit
message并pr,经过了好久才解决了这个问题,也就是将两个仓库进行合并,两个仓库没有很大的关系)
- fork老师的仓库,并clone到电脑,然后在目录上进行git。(或者进入clone到的本地地址执行git命令)
- git remote add other ../repo1/ #../repo1/ 参数为你已经完成git地址,如https://github.com/xxxx/xxx
- git fetch other # 把你完成的项目同步到本仓库
- git checkout -b repo1 other/master #创建分支repo1,并切换到分支repo1,并把刚同步的项目放到该分支上
- git checkout master #换到该项目主分支
- git merge repo1 --allow-unrelated-histories #将repo1分支合并到master分支,加--allow-unrelated-histories参数是因为两个项目可能经过修改已经没有什么关系了(一个初始项目,一个做好的项目)
- 后面可能会出现文件冲突,如两个都有.gitignore,可以先保存副本,然后删除项目中的.gitignore,然后就合并完成了
- 再到github上面发现fork下来的项目,已经有了已经完成的项目的commit message,并且可以pull requests
