


python 并发编程多线程之进程池/线程池
一、验证GIL锁的存在
Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行。虽然 Python 解释器中可以“运行”多个线程,但在任意时刻只有一个线程在解释器中运行。
from threading import Thread from multiprocessing import Process def task(): while True: pass if __name__ == '__main__': for i in range(4): # t=Thread(target=task) # 因为有GIL锁,同一时刻,只有一条线程执行,所以cpu不会满 t=Process(target=task) # 由于是多进程,进程中的线程会被cpu调度执行,4个cpu全在工作,就会跑满 t.start()
二、GIL锁与普通互斥锁的区别
from threading import Thread, Lock import time mutex = Lock() money = 88 def task(): global money mutex.acquire() temp = money time.sleep(1) money = temp - 1 mutex.release() if __name__ == '__main__': ll=[] for i in range(10): t = Thread(target=task) t.start() # t.join() # 会怎么样?变成了串行,不能这么做 ll.append(t) for t in ll: t.join() print(money) 小结:GIL锁是不能保证数据的安全,普通互斥锁来保证数据安全
三、io密集型和计算密集型处理
-----以下只针对于cpython解释器
-在单核情况下:
-开多线程还是开多进程?不管干什么都是开线程
-在多核情况下:
-如果是计算密集型,需要开进程,能被多个cpu调度执行
-如果是io密集型,需要开线程,cpu遇到io会切换到其他线程执行
# 计算密集型 # def task(): # count = 0 # for i in range(100000000): # count += i # # # if __name__ == '__main__': # ctime = time.time() # ll = [] # for i in range(10): # t = Thread(target=task) # 开线程:42.68658709526062 # # t = Process(target=task) # 开进程:9.04949426651001 # t.start() # ll.append(t) # # for t in ll: # t.join() # print(time.time()-ctime) ## io密集型 def task(): time.sleep(2) if __name__ == '__main__': ctime = time.time() ll = [] for i in range(400): t = Thread(target=task) # 开线程:2.0559656620025635 # t = Process(target=task) # 开进程:9.506720781326294 t.start() ll.append(t) for t in ll: t.join() print(time.time()-ctime)
五、死锁现象
# 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
import time from threading import Thread,Lock noodle_lock = Lock() fork_lock = Lock() def eat1(name): noodle_lock.acquire() print('%s 抢到了面条'%name) fork_lock.acquire() print('%s 抢到了叉子'%name) print('%s 吃面'%name) fork_lock.release() noodle_lock.release() def eat2(name): fork_lock.acquire() print('%s 抢到了叉子' % name) time.sleep(1) noodle_lock.acquire() print('%s 抢到了面条' % name) print('%s 吃面' % name) noodle_lock.release() fork_lock.release() for name in ['哪吒','nick','tank']: t1 = Thread(target=eat1,args=(name,)) t2 = Thread(target=eat2,args=(name,)) t1.start() t2.start()
解决方法:递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁。
import time from threading import Thread,RLock fork_lock = noodle_lock = RLock() def eat1(name): noodle_lock.acquire() print('%s 抢到了面条'%name) fork_lock.acquire() print('%s 抢到了叉子'%name) print('%s 吃面'%name) fork_lock.release() noodle_lock.release() def eat2(name): fork_lock.acquire() print('%s 抢到了叉子' % name) time.sleep(1) noodle_lock.acquire() print('%s 抢到了面条' % name) print('%s 吃面' % name) noodle_lock.release() fork_lock.release() for name in ['哪吒','nick','tank']: t1 = Thread(target=eat1,args=(name,)) t2 = Thread(target=eat2,args=(name,)) t1.start() t2.start()
六、Semaphore信号量
# Semaphore:信号量可以理解为多把锁,同时允许多个线程来更改数据
from threading import Thread,Semaphore import time import random sm=Semaphore(5) # 数字表示可以同时有多少个线程操作 def task(name): sm.acquire() print('%s 正在王者荣耀五排'%name) time.sleep(random.randint(1,5)) sm.release()
七、Event事件
# 一些线程需要等到其他线程执行完成之后才能执行,类似于发射信号
# 比如一个线程等待另一个线程执行结束再继续执行
from threading import Thread, Event import time import os event = Event() # 获取文件总大小 size = os.path.getsize('a.txt') def read_first(): with open('a.txt', 'r', encoding='utf-8') as f: n = size // 2 # 取文件一半,整除 data = f.read(n) print(data) print('我一半读完了,发了个信号') event.set() def read_last(): event.wait() # 等着发信号 with open('a.txt', 'r', encoding='utf-8') as f: n = size // 2 # 取文件一半,整除 # 光标从文件开头开始,移动了n个字节,移动到文件一半 f.seek(n, 0) data = f.read() print(data) if __name__ == '__main__': t1=Thread(target=read_first) t1.start() t2=Thread(target=read_last) t2.start()
八、线程Queue
from multiprocessing import Queue
from queue import Queue,LifoQueue,PriorityQueue
queue是线程安全的
三种线程Queue -Queue:队列,先进先出 -PriorityQueue:优先级队列,谁小谁先出 -LifoQueue:栈,后进先出 ''' # 如何使用 # q=Queue(5) # q.put("老林") # q.put("老刘") # q.put("铁蛋") # q.put("钢弹") # q.put("金蛋") # # # # q.put("银蛋") # # q.put_nowait("银蛋") # # 取值 # print(q.get()) # print(q.get()) # print(q.get()) # print(q.get()) # print(q.get()) # # 卡住 # # print(q.get()) # # q.get_nowait() # # 是否满,是否空 # print(q.full()) # print(q.empty()) # LifoQueue # q=LifoQueue(5) # q.put("lqz") # q.put("egon") # q.put("铁蛋") # q.put("钢弹") # q.put("金蛋") # # # # q.put("ddd蛋") # print(q.get()) #PriorityQueue:数字越小,级别越高 # q=PriorityQueue(3) # q.put((-10,'金蛋')) # q.put((100,'银蛋')) # q.put((101,'铁蛋')) # # q.put((1010,'铁dd蛋')) # 不能再放了 # # print(q.get()) # print(q.get()) # print(q.get())
九、进程池
在利用Python进行系统管理的时候,特别是同时操作多个文件目录,或者远程控制多台主机,并行操作可以节约大量的时间。多进程是实现并发的手段之一,需要注意的问题是:
- 很明显需要并发执行的任务通常要远大于核数
- 一个操作系统不可能无限开启进程,通常有几个核就开几个进程
- 进程开启过多,效率反而会下降(开启进程是需要占用系统资源的,而且开启多余核数目的进程也无法做到并行)
例如当被操作对象数目不大时,可以直接利用multiprocessing中的Process动态成生多个进程,十几个还好,但如果是上百个,上千个。。。手动的去限制进程数量却又太过繁琐,此时可以发挥进程池的功效。
我们就可以通过维护一个进程池来控制进程数目,比如httpd的进程模式,规定最小进程数和最大进程数...
ps:对于远程过程调用的高级应用程序而言,应该使用进程池,Pool可以提供指定数量的进程,供用户调用,当有新的请求提交到pool中时,如果池还没有满,那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到规定最大值,那么该请求就会等待,直到池中有进程结束,就重用进程池中的进程。(线程池与进程池非常类似就是导的类不同)
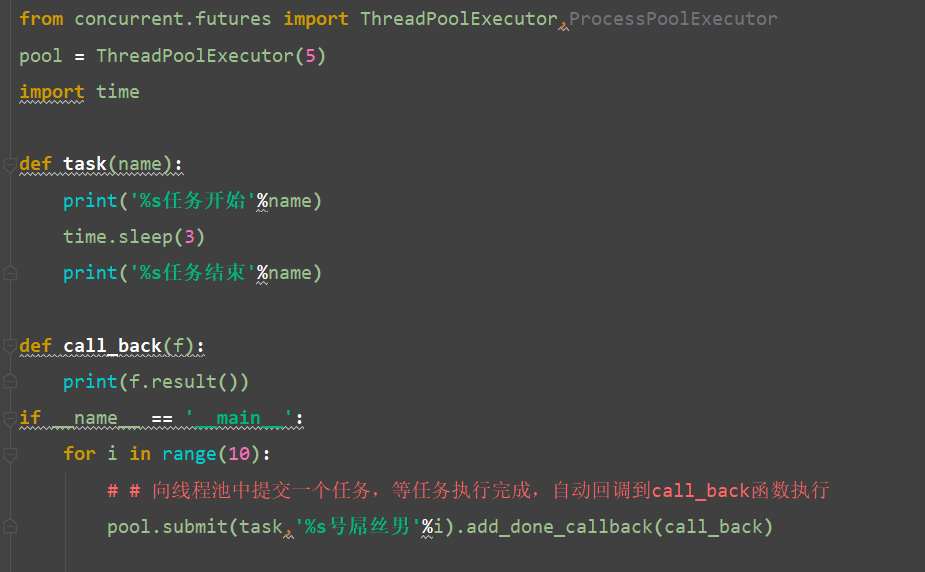
```python
# 1 如何使用
from concurrent.futures import ProcessPoolExecutor
pool = ProcessPoolExecutor(2)
pool.submit(get_pages, url).add_done_callback(call_back)
```
最终版
初始版

爬虫实例版
import requests import re import time headers = { 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36' } resbonse = requests.get(url='https://www.mzitu.com/',headers=headers) # print(resbonse.text) res = resbonse.text urls = re.findall('''data-original='(.*?)' ''',res,re.S) print(urls) for url1 in urls: time.sleep(0.1) file_name = url1.split('/')[-1] res = requests.get(url = url1) with open(file_name,'wb')as f: f.write(res.content)

