组合公式
c(n,m)=p(n,m)/m!=n!/((n-m)!*m!)
c(n,m)=c(n,n-m)
c(n,m)=c(n-1,m)+c(n-1,m-1)
欧拉定理
欧拉定理,(也称费马-欧拉定理)是一个关于同余的性质。欧拉定理表明,若n,a为正整数,且n,a互质,则:

φ(n)表示1~n中与n互质的数的个数
看一个基本的例子。令a = 3,n = 5,这两个数是互素的。比5小的正整数中与5互素的数有1、2、3和4,所以φ(5)=4(详情见[欧拉函数])。计算:a^{φ(n)} = 3^4 =81,而81= 80 + 1 Ξ 1 (mod 5)
这个定理可以用来简化幂的模运算。比如计算7^{222}的个位数,实际是求7^{222}被10除的余数。7和10[[互素]],且φ(10)=4。由欧拉定理知7^4Ξ1(mod 10)。所以7^{222}=(7^4)^55*(7^2)Ξ1^{55}*7^2Ξ49Ξ9 (mod 10)。
后话:欧拉定理其实是费马小定理的推广
先看费马小定理: 假如p是质数,且(a,p)=1,那么 a^(p-1)
p是质数时,φ(p)=p-1,那么a^φ(p)≡1(mod p)
乘法逆元
(a/b) mod p=(a*b^(p-2)) mod p
条件:p是素数,gcd(b,p)=1,a%b=0
定义: 满足a*k≡1 (mod p)的k值就是a关于p的乘法逆元。
(PS:p一定是个素数才能对a有乘法逆元(除1),特别注意:当p是1时,对于任意a,k都为1)
为什么要有乘法逆元呢?
当我们要求(a/b) mod p的值(a/b一定是个整数),且a很大,无法直接求得a/b的值时,我们就要用到乘法逆元。
我们可以通过求b关于p的乘法逆元k,将a乘上k再模p,即(a*k) mod p。
其结果与(a/b) mod p等价。
怎样求乘法逆元?
目前只会欧拉定理,留个坑,待填
根据欧拉定理: 假如p是质数,且(b,p)=1,则φ(p)=(p-1),那么 b^(p-1) ≡1(mod p) 。
b*b^(p-2) ≡1(mod p),所以b^(p-2)就是b的逆元,即k=b^(p-2)
所以(a/b) mod p=(a*b^(p-2)) mod p
这里是博主瞎比写的,正版的在下面↓↓↓
欧拉定理 (证明+在求逆元上的应用)
欧拉定理(又称费马-欧拉定理):已知a和n为正整数,并且a和p互素,则a^phi(n) ≡ 1(mod n)。
证明:
设集合Z = {X1, X2, X3, .... , Xphi(n)},其中Xi (i = 1, 2, .. phi(n))表示第i个不大于n与n互质的数。
考虑集合S = {a*X1(mod n), a*X2(mod n), ... ,a*Xphi(n) (mod n) },则集合Z = S;
1) 因为a和n互质,Xi和n也互质,所以a*Xi 也与n互质。所以对任意一个Xi,a*Xi (mod n)一定是Z里面的元素;
2)对于任意Xi, Xj, 如果Xi != Xj,则a*Xi(mod n) != a*Xj(mod n);
所以S = Z;
那么 (a*X1*a*X2*...*a*Xphi(n))(mod n) ---------------------------------------------------- (1)
= (a*X1(mod n)* a*X2(mod n)* ... *a*Xphi(n) (mod n)) (mod n)
= (X1* X2* X3* .... * Xphi(n)) (mod n) ------------------------------------------------------ (2)
式(1)整理得 [a^phi(x) * (X1* X2* X3* .... * Xphi(n))] (mod n)
与(2)式一同消去 (X1* X2* X3* .... * Xphi(n)),即得 a^phi(x) ≡ 1 (mod n);
逆元 :(b/a) (mod n) = (b * x) (mod n)。 x表示a的逆元。并且 a*x ≡ 1 (mod n)
因为a^phi(x) ≡ 1 (mod n),所以x可以表示为a^(phi(n) - 1)。
当n是素数时 phi(n)=n-1, x表示为a^(n-2)。
Lucas定理
A、B是非负整数,p是质数。AB写成p进制:A=a[n]a[n-1]...a[0],B=b[n]b[n-1]...b[0]。
则组合数C(A,B)与C(a[n],b[n])*C(a[n-1],b[n-1])*...*C(a[0],b[0]) modp同余
即:Lucas(n,m,p)=c(n%p,m%p)*Lucas(n/p,m/p,p)
For non-negative integers m and n and a prime p, the following congruence relationholds:
![\binom{m}{n}\equiv\prod_{i=0}^k\binom{m_i}{n_i}\pmod p,]() 表示的是同余,表示两个数对p取余,余数相同。
表示的是同余,表示两个数对p取余,余数相同。
 表示的是同余,表示两个数对p取余,余数相同。
表示的是同余,表示两个数对p取余,余数相同。where
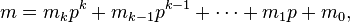
and
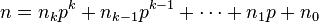
are the base p expansions of m and n respectively.
将m划分成m0个1,m1个p,m2个p^2,……
将n划分成n0个1,n1个p,n2个p^2……
C(m,n)的总共的取法就是( 在m0个里面取n0个的方案数 * m1个里面取n1个的方案数 * m2个里面取n2个的方案数 ……)
fzu2020

直接用Lucas


#include<cstdio> #include<iostream> using namespace std; #define ll long long ll n,m,p; ll pow_m(ll a,ll k,ll p) { ll ans=1; ll tmp=a%p; while(k) { if(k&1)ans=ans*tmp%p; tmp=tmp*tmp%p; k>>=1; } return ans; } ll C(ll n,ll m,ll p) { if(m>n)return 0; ll a=1,b=1; for(int i=1;i<=m;i++) { a=a*(n+i-m)%p; b=b*i%p; } return a*pow_m(b,p-2,p)%p; } ll Lucas(ll n,ll m,ll p) { ll ans=1; while(n&&m) { ans=ans*C(n%p,m%p,p)%p; n/=p; m/=p; } return ans; } int main() { int T; scanf("%d",&T); while(T--) { scanf("%d%d%d",&n,&m,&p); printf("%lld\n",Lucas(n,m,p)); } return 0; }
hdu3037

考虑加多一颗树,这样的话当加的树放了k(0<=k<=m)个beans时,原本的n颗树上放的beans数量之和就等于m-k(<=m),满足题目的要求 ,也降低了计算的难度。
则题目要求的是a1+a2+......an+an+1=m(0<=ai<=m,1<=i<=n+1) 式1
解有多少组。
考虑把问题转换成,求a1+a2+......an+an+1=m+n+1(1<=ai<=m+1,1<=i<=n+1) 式2
解有多少组。
因为式1的每组解,对于每个ai,都加上1的话,就是式2的一组解。
对于式2的求解:
考虑有m+n+1个Beans排成一列,则它们中恰好有m+n个间隔,在m+n个间隔中选择n个各插入一块木板,则把这些Beans分成n+1部分,每部分的值对应到每个ai,就是式2的一组解。而在m+n个间隔中选择n个,则是求组合数的问题了,p<=10^5且为质数,则可用Lucas定理求。
p<10^5,要进行阶乘预处理,用C2的方法来算组合数,否则会超时
#include<cstdio> #include<iostream> using namespace std; #define ll long long #define maxn 100010 ll n,m,p; ll fact[maxn]; ll pow_m(ll a,ll k,ll p) { ll ans=1; ll tmp=a%p; while(k) { if(k&1)ans=ans*tmp%p; tmp=tmp*tmp%p; k>>=1; } return ans; } ll C2(ll n,ll m,ll p)//p<10^5 { if(m>n)return 0; return fact[n]*pow_m(fact[m]*fact[n-m]%p,p-2,p); } ll Lucas(ll n,ll m,ll p) { ll ans=1; while(n&&m) { ans=ans*C2(n%p,m%p,p)%p; n/=p; m/=p; } return ans; } void init(ll p) { fact[0]=1; for(int i=1;i<=p;i++)fact[i]=fact[i-1]*i%p; } int main() { int T; scanf("%d",&T); while(T--) { scanf("%lld%lld%lld",&n,&m,&p); init(p); printf("%lld\n",Lucas(n+m,n,p)); } return 0; }
nefu625

题意:给出一个n*m大的花园,求出从左上角到右下角的路径数目(路径单调)。
先采取暴力分解,然后快速幂即可。分解的思想很巧妙。
非降路径数。从(a,b)到(m,n)共有C(m+n-a-b,m-a)种.
所以本题的解应该是C(m+n-2,m-1) (数学太差,窝也不知道它是怎么出来的,留坑
由于C(x,y)=x!/(y!*(x-y)!),这里我们可以将x!分解素因子,并保存记录下来,同样的方法记录后面两个,由于x!必然能够整除(y!*(x-y)!),所以后面两个数有的因子,x!比然有,只需要将他们的因子的指数相加减,就能得到最后结果的素因子分解的情况,然后最后使用快速幂取模,就能得到最后的结果。
注意:如何进行素因子分解?
首先要打表将所有的素因子求出来,这里有是将n!进行素因子分解,假设想要求出其中有多少个5,这里是有技巧的。
假设n=200,那么因子5的个数=200/5+40/5+8/5=49,怎么得到的呢?200中5的倍数有40个,这40个数中其中是25的倍数的有8个,所以还能分解出8个5,这8个数中还有一个是125的倍数,还能分解出一个5,就这样一直循环下去,就能求出指数的值。
#include<cstdio> #include<vector> #include<iostream> using namespace std; #define ll long long #define maxn 200010 ll n,m,p; vector<int>pri; bool prime[maxn]; void init() { pri.clear(); prime[0]=prime[1]=false; for(int i=2;i<maxn;i++) { if(!prime[i]) { pri.push_back(i); for(int j=i+i;j<maxn;j+=i) prime[j]=true; } } // printf("%d %d\n",pri.size(),pri[pri.size()-1]);//测试本题数据n<200000,则只需要17000个素数 } ll pow_m(ll a,ll k,ll p) { ll ans=1; ll tmp=a%p; while(k) { if(k&1)ans=ans*tmp%p; tmp=tmp*tmp%p; k>>=1; } return ans; } ll work(ll n,ll su) { ll ans=0; while(n) { ans+=n/su; n/=su; } return ans; } ll C3(ll n,ll m,ll p)// 0<n,m<10^6, 0<p<10^9 { if(m>n)return 0; ll ans=1; for(int i=0;pri[i]<=n;i++)//如果出现数组越界的错误,则说明素数不够用,init中再多开出一点素数来,或者换个姿势求素数 { ll x=work(n,pri[i]); ll y=work(n-m,pri[i]); ll z=work(m,pri[i]); ans=ans*pow_m(pri[i],x-(y+z),p)%p; } return ans; } int main() { init(); int T; scanf("%d",&T); while(T--) { scanf("%lld%lld%lld",&n,&m,&p); printf("%lld\n",C3(n+m-2,m-1,p)); } return 0; }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号