
有关hbase的面试题
背景
有一个超级大的文件,里面存放的全都是url,样本数据(url.txt)如下:
www.baidu.com
www.jd.com
www.taobao.com
......
需求
现在需要实时地判断出某个url是否包含在这个文件中,如何实现?
思路分析
1. 要实现查询速度快,肯定是要将所有的url存放在数组。
2. 既然要存放在在数组,那么该怎么存?数组的数据类型如何确定?数组的大小如何确定?
首先说该怎么存?
我们知道通过下标访问数组是比较快的,比如:arr[0],代表访问第一个元素。那么应该怎么存呢?
将url当做数组下标,通过下标访问数组,如果该位置中有内容,证明该url存在。
问题又来了,url是string类型,而数组的下标是int类型,怎么当做下标?将url取hash值。
其次,数组的数据类型怎么设定?
接下来,数组中存放什么内容呢?我们只需要判断当前url的hash值对应的数组下标中的数据是否有值就可以了,因此可以用0或者1来表示,1表示该url存在,0表示该url不存在。这样一来,数组的数据类型也可以确定了,使用bit作为数组的数据类型。
还有问题,我们知道没有一种完美的hash算法,能让不同的数据对应的hash值是完全不一致的。这就会导致一个问题,就是,可能有多个url的hash值都相同,这样在判断的时候就会存在误判。比如:假设www.lagou.com和www.baidu.com,的hash值都是5,而url.txt文件中只存放了www.baidu.com。现在,要判断www.lagou.com是否在url.txt文件中,通过对www.lagou.com取hash值,然后通过hash值对应的下标去查询数据,发现返回的值是1,判断为存在该url。而实际上url.txt文件中根本就没有www.lagou.com这个url,这就发生了误判。该怎么解决呢?
可以对一个url使用多种不同的hash算法求hash值,这样一来,每个url就会有多个不同hash值,在数组中的表现形式就是多个下标中的数据都是1。如下图所示:
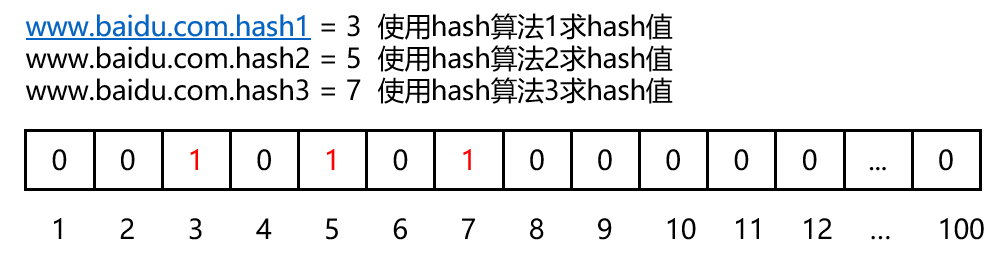
当需要判断该url是否存在时,就需要判断每个hash值对应的数组下标中的值是否为1,全为1则表示存在,只要有一个不为1,则表示不存在。
最后,数组的大小如何确定?
当然,通过以上的方法还是会存在误判。这就和hash算法的个数、数据的大小以及数组的长度有关了,也就是我们的最终问题,如何确定他们三个的关系?
布隆过滤器:将hash算法的个数、数据的大小和数组的长度通过一个公式集合起来,那么误判的几率将减小到最小。
k = 0.7 * m / n
k 表示hash算法的个数
m 表示数组的大小
n 表示数据的条数
