

字符串-str
字符串-str
1.1 特点
-
需要加上引号,单引号与双引号都可以,包含了多行内容的时候还可以用三引号
-
name = rock #报错,没有引号识别为变量名,
name = "rock" print(name) name = 'kyle' print(name) name = """rock #多行内容时使用三引号,区分三引号的注释 kyle """ print(name) """ #这样是注释 """>>> print(520 + 1314) 1834 >>> print("520" + "1314") 5201314 >>>
1.2 字符串的索引和切片
- 对字符串的某个字串或区间的检索称为切片
- 切片的语法为:
字符串或字符串变量[N:M]
含义:从字符串索引为N开始到M结束。不包含M
示例:
s='helloworld'
print(s[0],s[-10]) #序号0和-10表示的是同一个字符
print('北京欢迎您'[4]) #获取字符串索引为4的字符
print("北京欢迎你"[-1])
print("----------------------")
print(s[2:7]) #从2开始到7结束不包含7 正向递增
print(s[-8:-3]) #反向递增
print(s[:5]) #默认N从0开始
print(s[5:]) #M默认是切到字符串的结尾
结果:
h h
您
你
----------------------
llowo
llowo
hello
world
1.3 常用的字符串操作
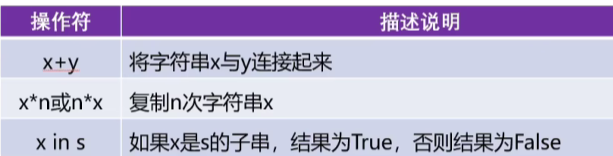
示例:
x='2025'
s='北京欢迎你'
print(s+x)
print(s*5)
print(5*s)
print('北京' in s) #True
print('上海' in s) #False
--------------------------------
结果:
北京欢迎你2025
北京欢迎你北京欢迎你北京欢迎你北京欢迎你北京欢迎你
北京欢迎你北京欢迎你北京欢迎你北京欢迎你北京欢迎你
True
False
1.4 字符串的常用操作
- 不可变字符序列


# 大小写转换
s = "HelloWorld"
print(s.upper()) #转大写 HELLOWORLD
print(s.lower()) #转小写 helloworld
# count()方法
o_count = s.count('o')
print(o_count) # 2
# 检索操作
# find()方法
o_find = s.find('o')
print(o_find) # 4
p_find = s.find('p')
print(p_find) # -1 #意为找不到
#index()方法
o_index = s.index('o')
print(o_index) # 4
# p_index = s.index('p')
# print(p_index) #ValueError: substring not found 找不到
# 字符串的分割 - 列表方式呈现
e_mail = 'nihao@py.com'
lst = e_mail.split("@")
print(lst)
print("邮箱名:"+lst[0],"邮箱域名:"+lst[1])
# 判断前缀与后缀
s = 'hello'
print('demo.py'.endswith('.py')) # True
print('test.txt'.endswith('.py')) # False
print(s.startswith('p')) #False
print(s.startswith('h')) #True
s = " helloworld "
#replace()方法 替换
print(s.replace('h','H')) # Helloworld
#center()方法 居中
print(s.center(50,'*'))
#去掉字符串左右空格
s1 = ' kyle rock '
print(s1.strip()) #去掉左右空格 kyle rock
print(s1.lstrip()) #去掉左空格 `kyle rock `
print(s1.rstrip()) #去掉右空格 ` kyle rock`
#去掉指定字符
s2 = 'ld_helloworld'
print(s2.strip('dl')) # _hellowor 与顺序无关
print(s2.strip('ld')) # _hellowor
print(s2.lstrip('dl')) # _helloworld
print(s2.rstrip('dl')) # ld_hellowor
name = " kyle "
name1 = "kyle"
print(name1.capitalize()) # 将首字母大写
print(name.capitalize()) # 将首字母大写
print(name.count("e")) # 统计"e"这个字母在name变量中的字符串出现的次数
print(name.center(50, "=")) # 打印50个字符,如果name这个变量中的字符串总个数不足50个,少出来的位置用“=”来填补,将name这个变量居中。
print(name.ljust(50, "*")) # 打印50个字符,如果name这个变量中的字符串总个数不足50个,少出来的位置用“=”来填补,但并不是将name这个字符串居中,而是打印整个字符串,不够50个字符串的用“*"号填补。
print(name.rjust(50, "*")) # 这个和上面的相反,将整个字符串的占位打在右边,左边不足50个字符的用"*"填补.
print(name.endswith("rock")) # 判断一个变量是否以“rock”这个字符串结尾,如果是就返回Ture.
print(name.find("e")) # 在name这个字符串中查找含有name字样的索引,从左往右开始查找,将查找的第一个返回出来,也就是最靠左边的那个.
print(name.rfind("e")) # 从左往右开始查找,将查找到的最靠右的匹配结果的索引取出来.
print(name[name.find("n"):]) # 字符串和列表都有相同的功能,都可以支持切片,比如这个例子就是取“n”这个字符后面的所有字符.
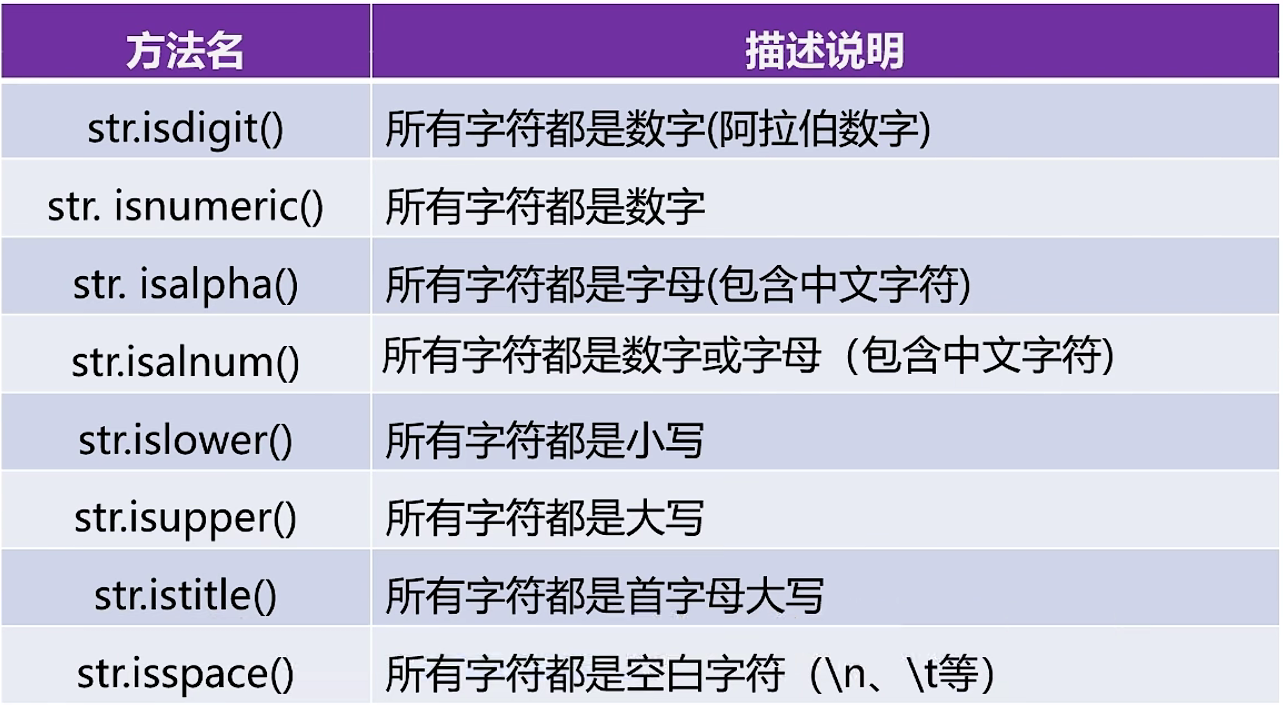
print(name.isalnum()) # 判断字符串是否仅仅包含[a-z][A-Z][0-9]
print(name.isalpha()) # 判断字符串仅仅包含[a-z][A-Z]
print(name.isdecimal()) # 判断字符串是否是十六进制的数字
print(name.isdigit()) # 判断该字符串是否是一个整数
print(name.isidentifier()) # 判断是不是一个合法的标识符
print(name.islower()) # 判断前面的字符串是否都是小写
print(name.isupper()) # 判断前面的字符串是否都是大写
print(name.isnumeric()) # 判断该变量是否是一个十进制的数字
print(name.isspace()) # 判断前面的字符串是否是一个空格
print(name.istitle()) # 判断这个字符串的每个字母是否大写
print(name.isprintable()) # 判断前面的字符串是否支持打印功能,一般字符串都是可以打印的。在linux中一切都是文件,一些tty,drive等终端文件是不能打印的,就可以用这个来判断,用途比较少
print(name.lower()) # 将大写变成小写
print(name.upper()) # 将小写变成大写
print(name.lstrip()) # 只去掉左边的换行符或者空格
print(name.rstrip()) # 只去掉左边和右边的换行符或者空格
print(name.strip()) # 去掉字符串左右两边的空格和换行符.
#运行对应结果:
Kyle
kyle
1
================== kyle ==================
kyle ************************************
************************************ kyle
False
8
8
False
False
False
False
False
True
False
False
False
False
True
kyle
KYLE
kyle
kyle
kyle
-------------------------------
print('kylerockeee'.replace('e', 'E', 2)) # 将字符串中的某个字符换成另外的一个字母或者数字(字符),后面可以匹配相应的次数,依次从左往右开始匹配。
print('kyle rock Qc'.split()) # 将字符串按照空格分成一个列表
print('1+2+3+4+5'.split('+')) # 用“+”作为分隔符,将其变成一个列表,如果不指定的话是以默认以空格分隔符的,例子如上
print('KyleRockQc'.swapcase()) # 将字符串中的大小写互换
print('kylerockqc'.title()) # 将以空格为分隔符的所有的小写字母变大写
print('kylerockqc'.zfill(50)) # 总共需要打印50个字符,如果字符串不够的话前面用0占位
#运行对应结果:
kylErockEee
['kyle', 'rock', 'Qc']
['1', '2', '3', '4', '5']
kYLErOCKqC
Kylerockqc
0000000000000000000000000000000000000000kylerockqc
1.5 数据的验证
- 数据的验证是指程序对用户输入的数据进行“合法”性的验证
print('123'.isdigit()) #True
print('112一Ⅰ壹贰叁'.isnumeric()) #True
print('saf,'.isalpha()) #False
print('nih你,12'.isalnum()) #False
print('nih12'.isalnum()) #True
print('hellO'.islower()) #False
print('hellO'.isupper()) #False
print('Hello'.istitle()) #True
print(' '.isspace()) #True
1.6 数据的处理
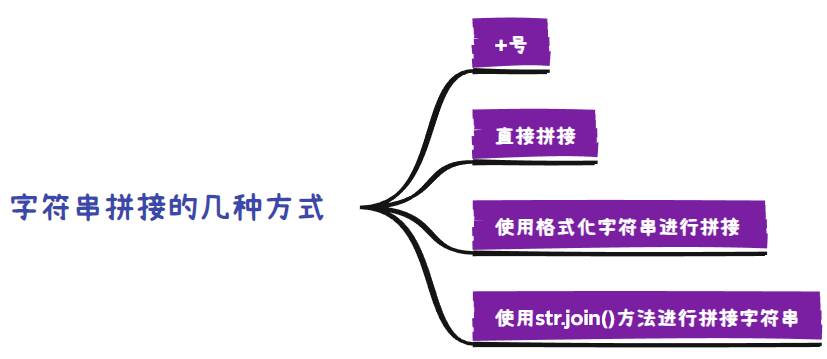
- 拼接
s1 = 'hello'
s2 = 'world'
#(1)使用+号拼接
print(s1+s2)
------------------------------------------
#(2)使用字符串join()方法拼接
print(''.join([s1,s2])) #拼接在一起不需要什么间隔,使用空字符串拼接
print('_'.join([s1,s2])) #_间隔
------------------------------------------
#(3)直接拼接
print('hello''world')
------------------------------------------
#(4)使用格式化字符串拼接
print('%s%s' %(s1,s2))
print(f'{s1}{s2}')
print(f'{s1},{s2}')
print(f'{s1}_{s2}')
print('{0}{1}'.format(s1,s2))
print('{0}_{1}'.format(s1,s2))
- 去重
s= "helloworldhelloworldfool"
#(1)字符串拼接 + not in
new_str=''
for item in s:
if item not in new_str:
new_str += item #拼接操作
print(new_str) # helowrdf
#(2)索引 + not in
new_str2=''
for i in range(len(s)):
if s[i] not in new_str2:
new_str2 += s[i] #拼接操作
print(new_str2) # helowrdf
#(3)集合去重 + 列表排序
new_str2 = set(s) # 集合无序
print(new_str2) #{'e', 'd', 'f', 'h', 'o', 'r', 'l', 'w'}
lst=list(new_str2) # 列表排序
lst.sort(key=s.index)
print(lst) #['h', 'e', 'l', 'o', 'w', 'r', 'd', 'f']
for item in lst:
print(item,end='') #helowrdf
print()
print(''.join(lst)) #helowrdf
练习
-
判断车牌归属地
- 需求:使用列表存储N个车牌号码,通过遍历列表及字符串的切片操
作判断车牌的归属于地
点击查看代码
lst = ['京A0000','津B1111','冀C8888'] for i in lst: area=i[0:1] print(area) - 需求:使用列表存储N个车牌号码,通过遍历列表及字符串的切片操
-
统计字符串中出现指定字符的次数
- 需求:声明一个字符串,内容为”HelloPython,Hellojava,hellophp'
用户从键盘录入要查询的字符(不区分大小写),要求统计出要查找
的字符在字符串中出现的次数
点击查看代码
#不区分大小写:先转成大写或小写 s='HelloPython,Hellojava,hellophp' word = input('请输入要查找的字符:') print(word+'出现的次数是:',s.lower().count(word)) - 需求:声明一个字符串,内容为”HelloPython,Hellojava,hellophp'
-
格式化输出商品的名称和单价
- 需求:使用列表存储一些商品数据,使用循环遍历输出商品信息,要
求对商品的编号进行格式化为6位,单价保留2位小数,并在前面添加
人民币符号输出
点击查看代码
lst = [ ['01','电风扇','美的',500], ['02','洗衣机','TCL',1000], ['03','微波炉','老板',400] ] # 格式化操作 for i in lst: i[0] = '0000' + i[0] i[3] = '¥{0:.2f}'.format(i[3]) print(' 编号\t\t 名称\t\t品牌\t\t 价格') for i in lst: for j in i: print(j,end='\t\t') print() # 结果 编号 名称 品牌 价格 000001 电风扇 美的 ¥500.00 000002 洗衣机 TCL ¥1000.00 000003 微波炉 老板 ¥400.00 - 需求:使用列表存储一些商品数据,使用循环遍历输出商品信息,要
总结




【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)