

字符串的编码及解码
1. 字符串的编码及解码解释
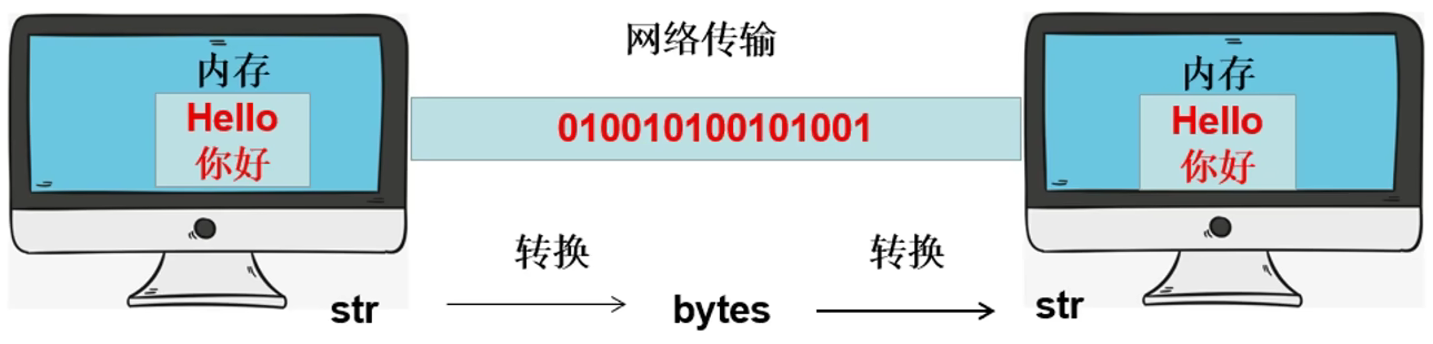
-
str类型转换为bytes类型为编码
-
bytes类型转换为str类型为解码
2. 字符串的编码
-
str类型转换为bytes类型使用字符串encode()方法
-
语法格式:
-
str.encode(encodeing= 'utf8',errors='strict/ignore/replace')
-
出错方式:strict:严格的;报错。 ignore:忽略;replace:替换为?
-
3. 字符串的解码
-
bytes类型转换为bytes类型使用字符串decode()方法
-
语法格式:
-
bytes.decode(encodeing= 'utf8',errors='strict/ignore/replace')
-
出错方式:strict:严格的;报错。 ignore:忽略;replace:替换
-
4. 应用
s = '伟大的中国梦'
# 编码 str->bytes
code_utf = s.encode(errors='replace') # 编码方式默认为utf-8,utf-8中文占3个字节 出错方式,replace替换
# b'\xe4\xbc\x9f\xe5\xa4\xa7\xe7\x9a\x84\xe4\xb8\xad\xe5\x9b\xbd\xe6\xa2\xa6' 18个
print(code_utf)
# 编码gbk
code_gbk = s.encode('gbk',errors='replace')
print(code_gbk) # 编码gbk 中文占2字节
# b'\xce\xb0\xb4\xf3\xb5\xc4\xd6\xd0\xb9\xfa\xc3\xce'
#解码 bytes->str
bcode = code_utf.decode(errors='replace')
print(bcode) # 伟大的中国梦
gbcode = code_gbk .decode('gbk',errors='replace')
print(gbcode) # 伟大的中国梦
------------------------------------------------------
# 编码中的出错问题
s2= '耶✌'
s0code_utf = s2.encode('gbk',errors='ignore')
print(s0code_utf) # b'\xd2\xae'
s1code_utf = s2.encode('gbk',errors='replace')
print(s1code_utf) # b'\xd2\xae?'
# s2code_utf = s2.encode('gbk',errors='strict')
# print(s2code_utf) # UnicodeEncodeError: 'gbk' codec can't encode character '\u270c'
# 解码
dcode= s0code_utf.decode('gbk',errors='replace')
print(dcode) # 耶
dcode= s1code_utf.decode('gbk',errors='replace')
print(dcode) # 耶?


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)