【实验】鸢尾花分类——简单的神经网络
import torch from torch import nn from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import numpy as np import matplotlib.pyplot as plt X = torch.tensor(load_iris().data, dtype=torch.float32) y = torch.tensor(load_iris().target, dtype=torch.long) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
导入鸢尾花数据集,这里注意数据和标签类型的设置:dtype=torch.float32,dtype=torch.long,否则会报错
net = nn.Sequential(nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 10),
nn.ReLU(),
nn.Linear(10, 3))
def init_weights(m): if type(m) == nn.Linear: nn.init.normal_(m.weights, std=0.01) loss = nn.CrossEntropyLoss(reduction="none") trainer = torch.optim.Adam(net.parameters(), lr=0.05) train_loss = [] test_loss = [] train_l = loss(net(X_train), y_train).mean().detach().numpy() test_l = loss(net(X_test), y_test).mean().detach().numpy() train_loss.append(train_l) test_loss.append(test_l) epochs = 1000 for i in range(epochs): trainer.zero_grad() l = loss(net(X_train), y_train).mean() l.backward() trainer.step() l = loss(net(X), y).mean() train_l = loss(net(X_train), y_train).mean().detach().numpy() test_l = loss(net(X_test), y_test).mean().detach().numpy() train_loss.append(train_l) test_loss.append(test_l) epoch_index = range(epochs + 1) plt.plot(epoch_index, train_loss, 'green', epoch_index, test_loss, 'blue') plt.show()
使用交叉熵损失函数时, 定义神经网络架构的时候不需要用Softmax ! nn.CrossEntropyLoss自带了Softmax (我一开始在神经网络最后一层加了nn.Softmax有报错)
关于交叉熵损失函数,nn.CrossEntropyLoss(),有一些需要注意的点
贴篇网上介绍的博客,后面看自己有没有时间总结下。https://blog.csdn.net/geter_CS/article/details/84857220
有些场合(例如用matplotlib绘图)需要用numpy的数组,使用能求梯度的tensor是会报错的!
这里用.detach().numpy()来完成,例子可以见上面的代码
使用交叉熵损失函数求出的是(1 * 样本数)的向量,绘图时需要求均值 (我一开始求的和, 导致训练集误差明显大于测试集误差)
实验结果:
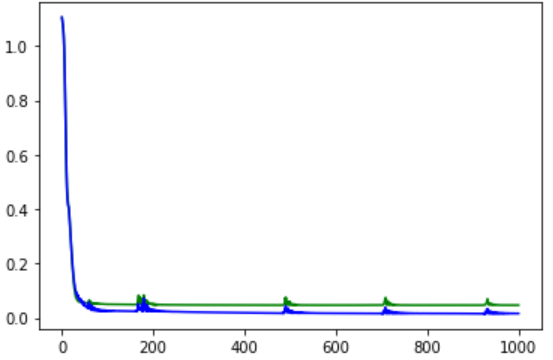
会发现一个反常情况:测试集误差小于训练集误差
这是因为鸢尾花数据记的数据太少了, 只有150个数据,导致测试数据太少,提高测试数据的数量会缓解这种问题。
事实上线性已经足够了。。。而且效果奇佳:
![]()
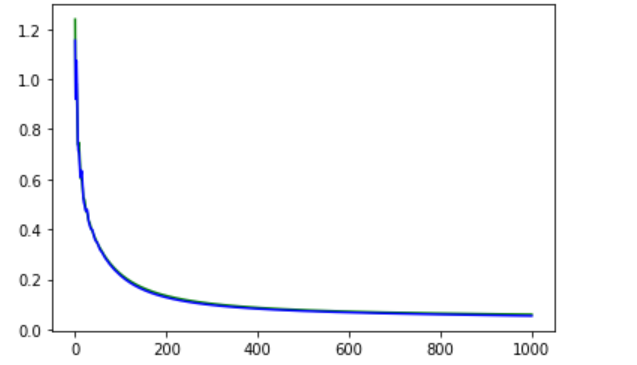
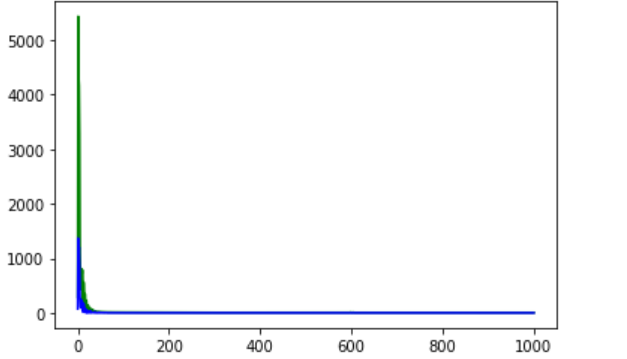
宽的浅层网络:

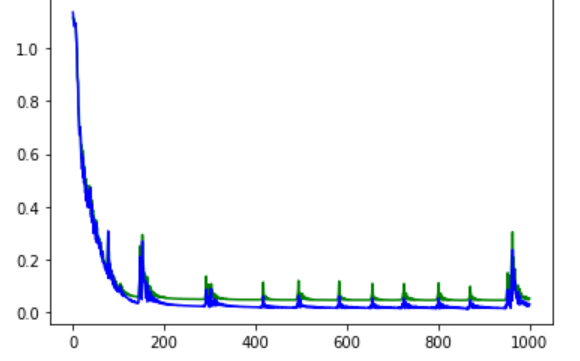
神经网络太深,迭代次数不够, 神经网络会练不动:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号