【Stanford - Speech and Language Processing 读书笔记 】8、Sequence Labeling for Parts of Speech and Named Entities
0、Introduction
序列标注(sequence labeling)任务:对于输入序列的每个单词x_i, 为其分配一个标记y_i。 易见输出的标记序列和输入序列长度一致。
下面介绍两个序列标注任务——
1、词性标注(part-of-speech tagging):标注序列中每个单词的词性
2、命名实体识别(named entity recognition, NER):为单词或短语分配标记, 如人物、位置、组织等等
1、(Mostly) English Word Classes
词类分为两大类: 封闭类(closed class)和开放类(open class)。
封闭的类是那些成员相对固定的类,比如介词——很少创造新的介词。相比之下,名词和动词是开放类——像iPhone或传真这样的新名词和动词不断被创造或借用。
封闭类词通常是像of, it, and, or you这样的虚词,虚词通常很短,经常出现,在语法中经常有结构用法。

2、Part-of-Speech Tagging
词类标记是将词性分配给文本中每个单词的过程。输入是一个序列x1, x2,…,xn的(tokenized)单词和一个标签集,输出为y1, y2,…,yn标签序列,每个输出yi对应一个输入xi,
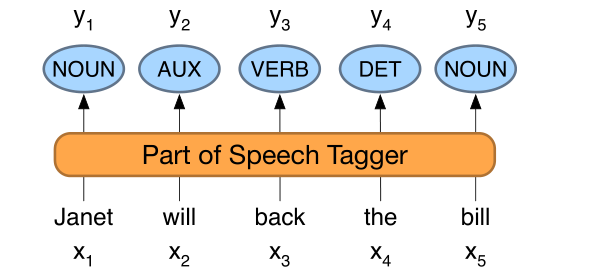
词性标注是一个去模糊化的过程, 单词的词性可能是多种的(如hand me the book和 book the flight),但是在词性标注中我们需要给文本中的每个单词标注唯一的词性。
大部分单词的词性是唯一的(85-86%),只有14-15%的单词有多种词性,但是这种单词在文本中是普遍存在的, 在一个文本中常常达到55-56%的比例,比如that,back,put等等。
这个想法提出了一个有用的基线算法: 给定一个词性模糊的单词,选择在训练语料库中最常见的标签。

这种基线算法精度达到了92%, 而目前词性标注算法(如HMMs, CRFs, BERT)的精确度达到了97%(SOTA),二者只差5%。
3、Named Entities and Named Entity Tagging
粗略地说,命名实体就是任何可以用命名实体固有名称引用的东西:一个人、一个地点、一个组织。
命名实体识别(NER)的任务是找到构成专有名称的文本范围,并标记命名实体识别的类型。
最常见的四个实体标签: PER(人)、LOC(地点)、ORG(组织)或GPE(地缘政治实体)。
然而,命名实体这个术语通常被扩展为包含本质上不是实体的东西,包括日期、时间和其他种类的时间表达式,甚至像价格这样的数字表达式。下面是一个NER tagger输出的例子:

在许多自然语言处理任务中,命名实体标记是有用的第一步。在情绪分析中,我们可能想知道消费者对某个特定实体的情绪。实体是回答问题或将文本链接到维基百科(Wikipedia)等结构化知识资源中的信息时非常有用的第一阶段。命名实体标签也是构建语义表示的核心任务,比如提取事件和参与者之间的关系。
与词性标注不同的是,命名实体识别的任务是查找和标注文本的范围,不存在切分问题,部分原因是切分的模糊性。需要决定什么是实体,什么不是,以及边界在哪里。事实上,文本中的大多数单词都不会被命名为实体。另一个困难是由类型歧义引起的。JFK可以指一个人、纽约的机场,也可以指美国各地的学校、桥梁和街道。
对于像NER这样的跨越识别问题,序列标记的标准方法是BIO标记, 还有IO标记和BIOES标记——
BIO标记:B标注我们感兴趣范围的起始单词, I标注范围内部的单词, O标注范围之外的单词
IO标记:I标注我们感兴趣范围中的单词, O为范围之外的单词
BIOES:增加E标注范围的最后一个单词, 如果范围内只有一个单词,那么它由S标注


4、HMM Part-of-Speech Tagging
HMM是一种概率序列模型:给定一个单位序列(单词、字母、语素、句子等),它计算可能的标签序列的概率分布,并选择最佳的标签序列。
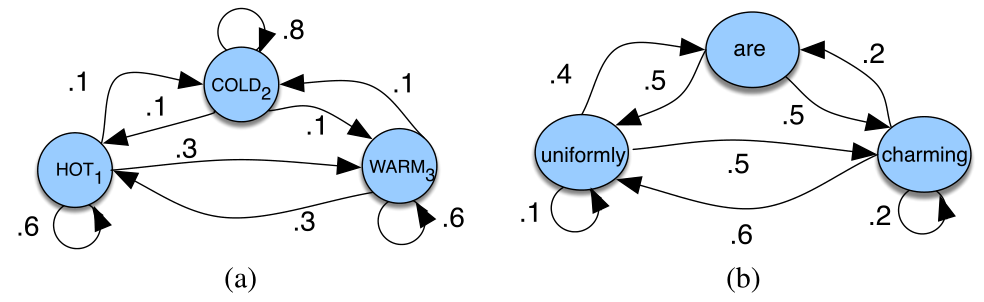
马尔科夫链(Markov chain):某个集合中随机的变量/标签/状态构成序列的概率。马尔科夫链做出一个比较强的假设:
![]()
马尔科夫链的组成:

隐马尔科夫模型(HMM):根据观测序列选择最有可能的状态序列, 状态序列的转换概率由状态转移矩阵决定,观测序列分配的概率由状态序列决定


对于任何包含隐藏变量的模型,如HMM,确定与观察序列相对应的隐藏变量序列的任务称为解码。更正式地:

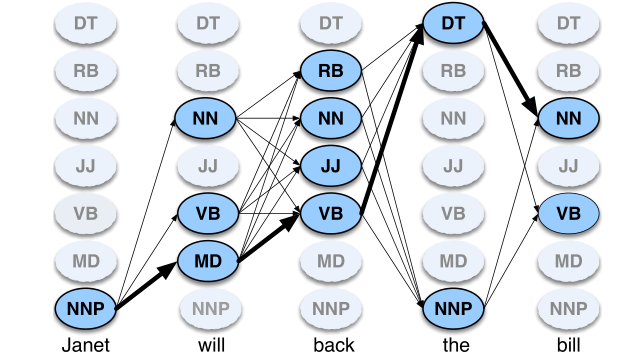
算法:维特比算法(详细见李航统计学习方法)

5、Conditional Random Fields (CRFs)
线性对数模型:CRF
与HMM不同,CRF利用线性对数模型直接计算隐藏变量序列关于观测序列的条件概率:
![]()
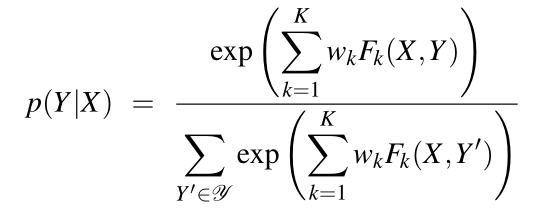
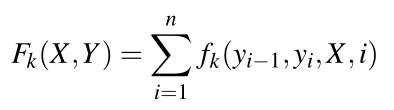

一些特征举例:
![]()
当l_i是“副词”并且第i个单词以“ly”结尾时,我们就让f1 = 1,其他情况f1为0。不难想到,f1特征函数的权重λ1应当是正的。而且λ1越大,表示我们越倾向于采用那些把以“ly”结尾的单词标注为“副词”的标注序列
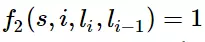
如果i=1,l_i=动词,并且句子s是以“?”结尾时,f2=1,其他情况f2=0。同样,λ2应当是正的,并且λ2越大,表示我们越倾向于采用那些把问句的第一个单词标注为“动词”的标注序列。
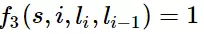
当l_i-1是介词,l_i是名词时,f3 = 1,其他情况f3=0。λ3也应当是正的,并且λ3越大,说明我们越认为介词后面应当跟一个名词。

如果l_i和l_i-1都是介词,那么f4等于1,其他情况f4=0。这里,我们应当可以想到λ4是负的,并且λ4的绝对值越大,表示我们越不认可介词后面还是介词的标注序列。
CRF推断:使用维特比算法
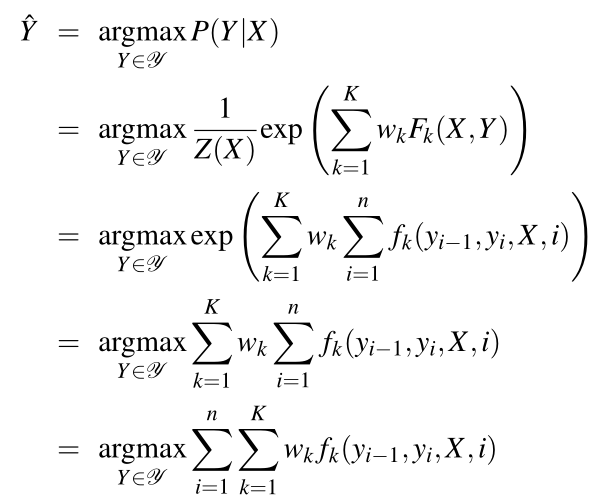

CRF的训练:
crf中的学习依赖于与逻辑回归相同的监督学习算法。给定一个观察序列、特征函数和相应的输出,我们使用随机梯度下降训练权值,以最大限度地提高训练语料库的对数似然。
逻辑回归一样,L1或L2正则化也很重要。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号