【知识图谱】类别推断SDType
参考论文:

1、Introduction
类型信息在知识库中起着重要的作用。说明实例是某种类型的公理是知识库的原子构建块之一,例如,Thomas Glavinic是Writer类型的实例。
对知识库的许多有用查询都使用类型信息,例如,查找所有来自维也纳的作家,《夜班工作》是小说还是短篇小说等等。
由于手动为大型知识库中的所有实例分配类型通常是不可行的,因此需要自动支持创建类型信息。
此外,由于开放的众包(crowded source)知识库经常包含嘈杂的数据,基于逻辑的推理方法很可能会增加错误。
在本文中,我们展示了如何通过利用知识库中的其他公理启发式地生成类型信息,特别是实例之间的链接。与经典的推理方法不同,采用了考虑多个环节的加权投票方法,从而避免了单个错误公理的错误传播。
2、Problems with Type Inference on Real-world Datasets
语义Web中推断类型信息的标准方法是使用推理。
传统的逻辑推理方法为什么会出现错误?一个推理者只需要一个错误的陈述就能得出一个错误的结论。换句话说:即使知识库的准确率达到99.9%,RDFS推理机也不会提供有意义的结果。
所需要的是一种能够容忍错误和噪声数据的归纳类型的方法。
3、Approach
SDType方法利用实例之间的链接,使用加权投票来推断它们的类型。
假设某些关系只发生在特定的类型上,我们可以启发式地假设,如果一个实例通过某些关系连接到其他实例,那么它应该具有某些类型。例如,从像:x dbpedia-owl:location:y这样的语句中,我们可以很有把握地得出结论:y是一个地方。
3.1 Link-based Type Inference
SDType使用资源之间的链接作为类型的指标,即提出了一种基于链接的对象分类方法。
其基本思想是使用来自实例和到实例的每个链接作为资源类型的指示符。对于每个链接,在属性的主题和对象位置使用类型的统计分布(stastical distribution,因此命名为SDType)来预测实例的类型。对于数据集中的每个属性,主题和对象都有类型的特征分布。
例如,属性DBpedia -owl: location在DBpedia中的247,601个三元组中被使用。图表显示了该属性基于这个示例的发行版摘录分布,当观察一个类似于:x dbpedia-owl:location:y的三元组时,我们可以将具有概率的类型赋给:x和:y。根据表1中的分布,我们可以分配P (?x a dbpedia-owl:Place) = 0.698, P (?y a dbpedia-owl:Place) = 0.876

SDType的基本构建块是条件属性,在给定具有特定属性p的资源时,这些属性度量类型T的可能性:
![]()
每个属性都被分配了一个特定的权重w_p,它反映了其预测类型的能力(见下文)。有了这些元素,我们可以计算类型为t的资源r的置信度:
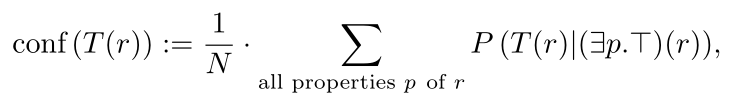
其中N是连接一个资源到另一个资源的属性数。通过使用每种类型的平均概率,我们解决了错误链接的问题,因为它们对总体概率的贡献不大。
当数据集严重倾斜时,它可能会引发新的问题,例如,某些类的扩展比其他类大几个数量级。对于一般用途的属性,例如rdfs:label或owl:sameAs,这是一个特别的问题,它们在整个知识库中分布相当均匀。如果这个知识库严重倾斜(例如,一个关于城市和国家的数据库平均包含每个国家1万个城市),并且它包含许多这样的一般用途属性,就有可能高估更常见的类型。因此,我们为每个属性定义了一个权重wp(注意,p和p^−1是独立处理的,并为每个属性分配了单独的权重),它衡量该属性与所有类型的先验分布的偏差:
可以将上面的定义细化为: 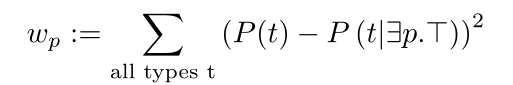


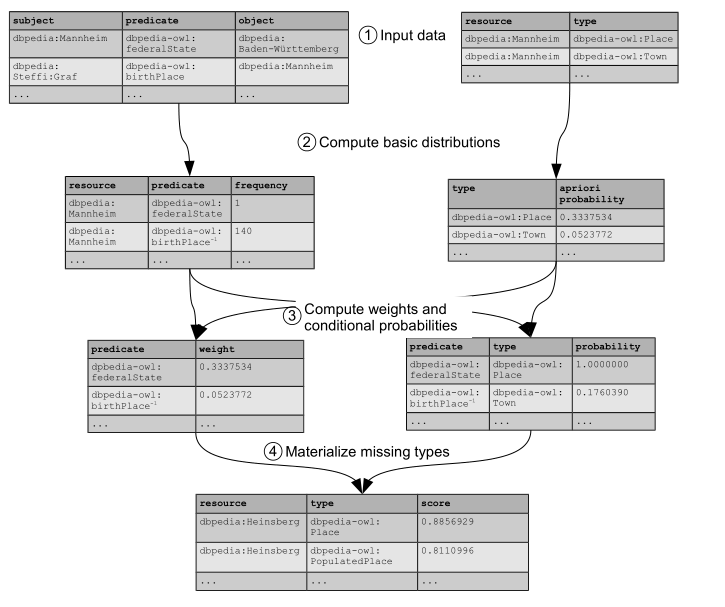
4、Implemention
SDType基于关系数据库实现,如图所示。输入数据由两个表组成,一个包含实例之间的所有直接属性断言,另一个包含所有直接类型断言。从这些输入文件中,可以计算出基本的统计和聚合:所有资源的每种类型关系的数量,以及所有类型的先验概率,即属于该类型的实例的百分比。这些表中的每一个都可以通过对输入表或它们的联接进行一次传递来计算。基本统计表作为计算上述公式中权重和条件概率的中间结果。同样,这些权重和条件概率可以通过一次传递中间表或它们的联接来计算。在最后一步,可以具体化新的类型,包括信心分数。这可以对所有实例执行,也可以作为服务实现,后者按需键入一个实例。由于每个步骤都需要遍历数据库,因此知识库中语句的数量与总体复杂度呈线性关系。