【Stanford - Speech and Language Processing 读书笔记 】4、Naive Bayes and Sentiment Classification
1、Introduction
介绍朴素贝叶斯(naive bayes),并将其运用于文本分类(text categorization),聚焦情感分析(sentiment analysis),以及垃圾邮件检测(spam detection),作者署名(authorship attribution)。
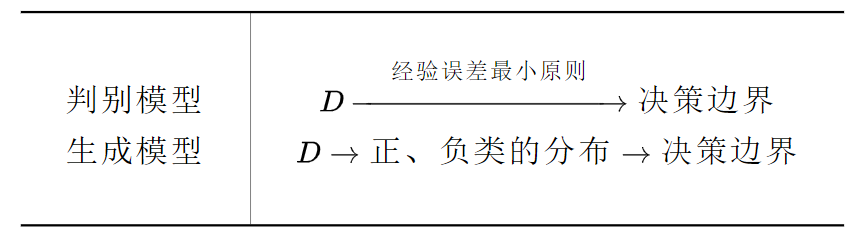
朴素贝叶斯是生成模型(Generative model),即学习数据的本质分布来进行分类;下章介绍的逻辑斯蒂回归是判别模型(Discriminative model),直接学习分类函数/分类界面。
2、Naive Bayes Classifiers
“朴素”——简化假设:不考虑文本中单词的顺序排列,只计算每个单词出现的次数,即把文本看成 " bag of words "。
朴素贝叶斯是一个概率分类器, 给一个文本d, 能返回d最有可能的类别c:
![]()
利用贝叶斯推断:
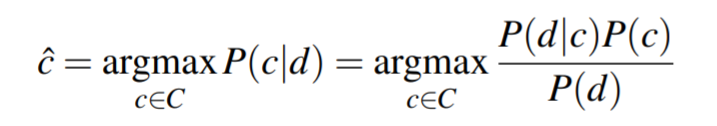
化简为:
![]()
P(c)称为先验概率(prior possibility),P(d|c)称为似然概率(likelihood possibility)。
当文本d表示为一个个特征f1、f2……:
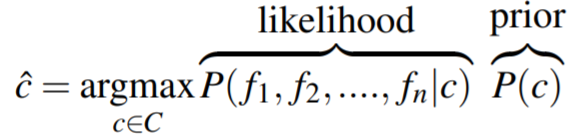
为简化计算, 再次做出“朴素”的假设——特征之间相互独立:
![]()
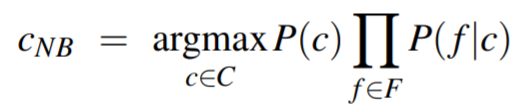
为了应用于文本分类任务,考虑每个单词的位置:

取对数来提升速度并防止溢出:
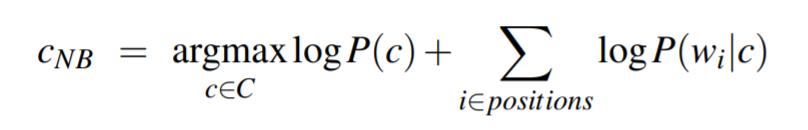
3、Training the Naive Bayes Classifier
计算先验和似然:
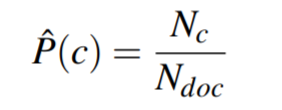
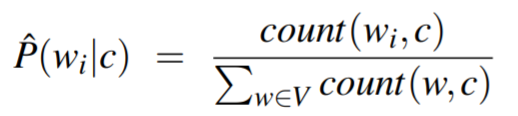
令Nc为类别为c的文本个数,Ndoc为文本总数, count(wi, c)为词wi出现在类别c的文本中的个数;用P(wi | c)表示P(fi | c)。
为了解决某个P(wi | c) = 0的情况,可以采用laplace平滑,以及unknow words问题, 都可以参照第二章。
学习算法如下:

以及一个简单的栗子:

4、Optimizing for Sentiment Analysis
(1)对于情感分类和许多其他文本分类任务,一个词是否出现似乎比它的频率更重要。 因此,将每个文档中的字数限制为 1 通常会提高性能。这种方法常常称为二元多项式朴素贝叶斯(binary multinomial naive bayes,binary NB)
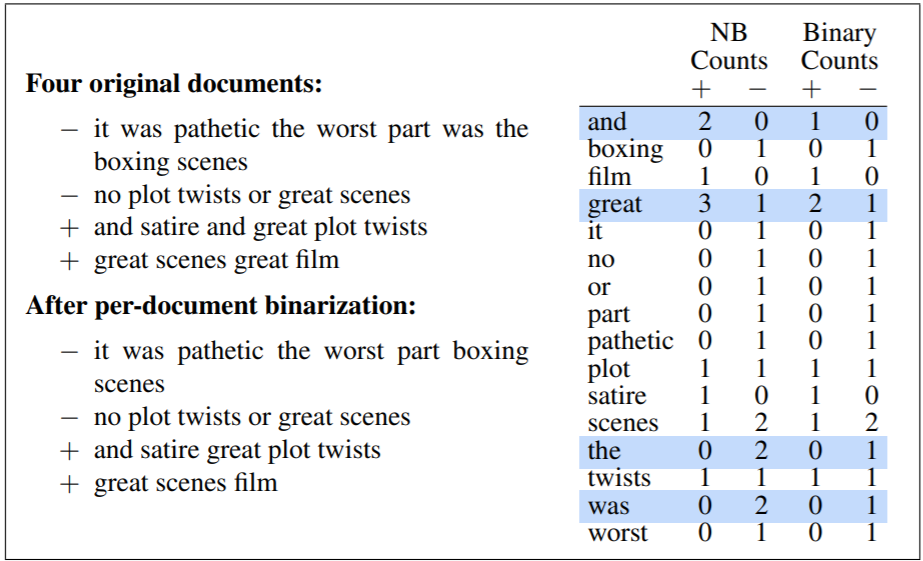
(2)在为情感进行文本分类时,第二个重要的补充是处理否定。考虑 I really like this movie (positive) 和 I didn’t like this movie (negative),否定并没有完全改变我们从谓词 like 中得出的推论。
一个简单的处理方法:在文本规范化期间,在逻辑否定标记(n't,not,no,never)之后的每个单词前面加上前缀 NOT,直到下一个标点符号。
例如didn’t like this movie , but I 改为 didn’t NOT_like NOT_this NOT_movie , but I
(3)最后,在某些情况下,我们可能没有足够的标记训练数据来使用训练集中的所有单词训练准确的朴素贝叶斯分类器来估计积极和消极的词,这时我们可以利用情感字典(sentiment lexicon),四个有名的情感词典:General Inquirer (Stone et al., 1966), LIWC (Pennebaker et al., 2007), the opinion lexicon of Hu and Liu (2004) and the MPQA Subjectivity Lexicon (Wilson et al., 2005).
例如MPQA中的:

5、Evaluation and Testing
此处略, 以后找个时间单独总结

 浙公网安备 33010602011771号
浙公网安备 33010602011771号