

【Stanford - Speech and Language Processing 读书笔记 】6、Vector Semantics and Embeddings
1、Introduction
出现在相同语境下的词语往往具有相似的意思, 词语的分布和它们的相似程度的联系称为分布假设(distributional hypothesis)。
在本章中,我们介绍向量语义(vector semantics),它通过直接从它们在文本中的分布学习单词含义的表示(称为嵌入, embeddings)来实例化这种语言学假设。
2、vector semantics
向量语义的思想:通过邻近词语 (word neighbors,往往指相似的词语) 来用一个高维语义空间的点表示一个词语。
表示词语的向量称为嵌入(embeddings)。 一个例子如下:

3、Words and Vectors
向量或者分布模型一般基于共现矩阵(co-occurrence matrix)。以下介绍两种常用的矩阵——单词文本矩阵(term-document matrix)、单词单词矩阵(term-term matrix)。
3.1 term-document matrix
在单词-文本矩阵中,每一行代表词汇表中的一个词,每个列代表某个文档集合中的一个文档,矩阵中的每一格代表单词在文本中出现的次数。例如:

可以将每一列作为一个向量, 可以比较文本的相似程度,因为相似的文本往往出现相似的词语。常常用于信息检索(information retrival):


也可以将每一行作为一个向量, 可以用于比较单词的相似程度, 因为相似的单词往往出现在相似的文本中:

3.2 term-term matrix
每个单元格记录行(目标)词和列(上下文)词在某些训练语料库中的某些上下文中共同出现的次数。
上下文可以是文档,在这种情况下,单元格表示两个单词多少次在同一文档中出现。 然而,最常见的是使用较小的上下文,通常是单词周围的窗口(例如左边4个词到右边4个词)


4、Cosine for measuring similarity
利用余弦函数衡量两个向量的相似程度, 两个向量夹角越小, 说明越相似:

例如:
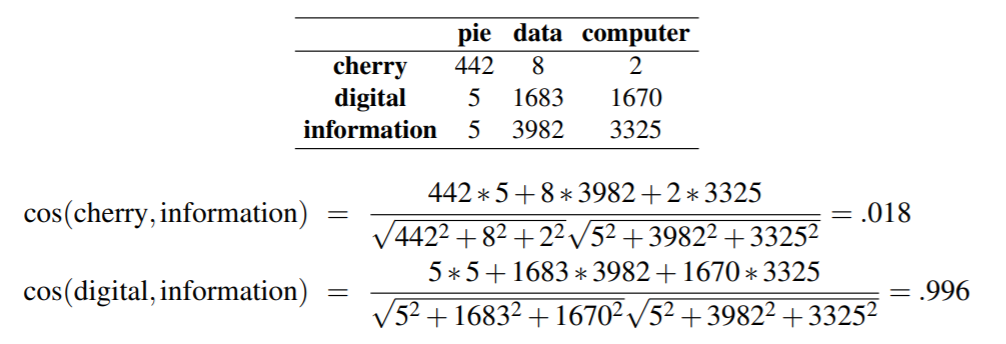

5、TF-IDF:Weighing terms in the vector
问题提出: 我们用词语出现的频率来衡量该词语的重要程度。 然而, 一个出现评率很高的单词未必重要, 比如the、by等等,几乎在每个文本中出现频率都很高。
如何平衡这个矛盾, 就是接下来要介绍的——tf-idf model和 PMI model。
tf-idf主要是针对单词-文本矩阵,主要思想是: 如果一个单词出现在较少的文本中, 且出现频率较高, 则可以认为它比较重要; 如果一个单词出现在很多文本中, 即使出现频率很高, 也把它看做不重要的单词。也就是综合给出现频率更高的单词赋予更高的权重和给出现在较少文本中的单词赋予更高的权重, 具体计算方法如下:
用term frequency 表示词语t在 文本d中的出现次数:
![]()
或者,更常见地:
![]()
用document frequency表示词语t出现在多少个文本中: df_t
再用inverse document frequency给出现在较少文本的词语以较高的权重, N表示所有文本的数量:
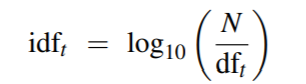
计算tf-idf weight value:
![]()
6、Pointwise Mutual Information (PMI)
逐点互信息(Pointwise Mutual Information (PMI))用于单词-单词矩阵, 其主要思想是:衡量两个词之间关联的方法是询问这两个词在我们的语料库中同时出现的次数比我们先验地预期它们偶然出现的次数多多少。具体计算方法如下:
目标词w(target word)和上下文词c(context word)的逐点互信息定义为:
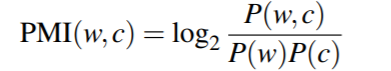
往往用正点互信息(PPMI)代替逐点互信息, 因为当PMI为负时, 除非语料库非常大, 否则往往不可信:
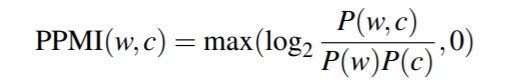
计算边缘概率和联合概率:
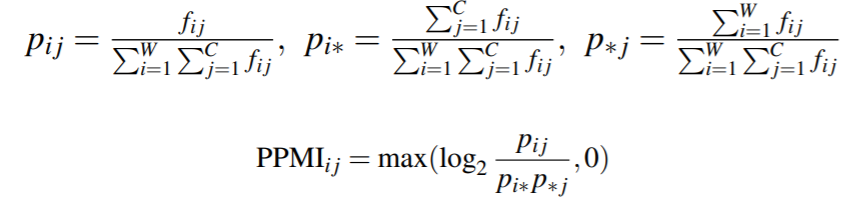
考虑到非常稀少的单词往往会有非常高的PPMI值, 可以做如下修改:
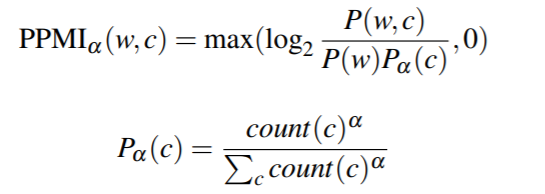
有研究表明, a = 0.75时往往能提升很多任务的性能。
7、Word2Vec
上述方法是将单词表示为长的稀疏的向量。 接下来介绍的embeddings, 是将单词表示短的、稠密的向量, 往往在任务中比表示成稀疏向量有更好的性能。
以下介绍跳格算法(skip-gram)用于计算embeddings, 其主要思想为:
1. 将目标词和相邻的上下文词视为正例。
2. 随机抽取词典中的其他词得到负样本。
3. 使用逻辑回归训练分类器来区分这两种情况。
4. 使用学习到的权重作为嵌入。
分类器
首先目标是训练一个分类器:给一个(w,c), w是目标词, c 是文本中合适的词, 我们需要训练出一个能给出c是w上下文词的概率的分类器:
![]()
考虑利用向量内积表示词语相似度, 而相似度高的单词容易接近在一起:
![]()
使用逻辑斯特回归将其表示为概率:
![]()

假设上下文词都是独立的, 可以计算一个窗口的概率:
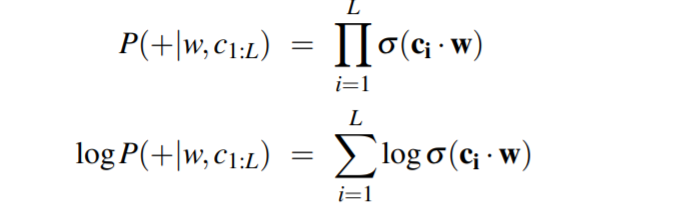
总之,skip-gram 训练一个概率分类器,给定一个测试目标词 w 和它的 L 个词 c1:L 的上下文窗口,根据这个上下文窗口与目标词的相似程度分配一个概率。 概率基于将逻辑(sigmoid)函数应用于目标词与每个上下文词的嵌入的点积。 为了计算这个概率,我们只需要对词汇表中的每个目标词和上下文词进行嵌入。 下图显示了我们需要的参数的直观性。 Skip-gram 实际上为每个词存储了两个嵌入,一个用于作为目标的词,另一个用于被视为上下文的词。 因此,我们需要学习的参数是两个矩阵 W 和 C,每个矩阵都包含对 |V| 中的每一个的嵌入。
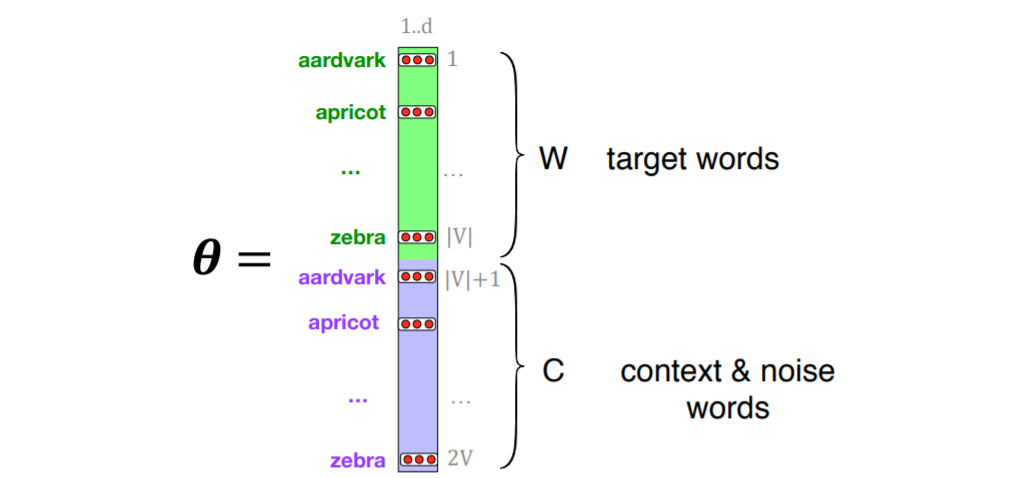
训练跳格算法得到嵌入向量
skip-gram 嵌入的学习算法将文本语料库和选定的词汇量 N 作为输入。它首先为 N 个词汇中的每一个词分配一个随机嵌入向量,然后迭代地移动每个词的嵌入向量 w ,使其更像是附近出现的词的嵌入,而不是附近不出现的词的嵌入。
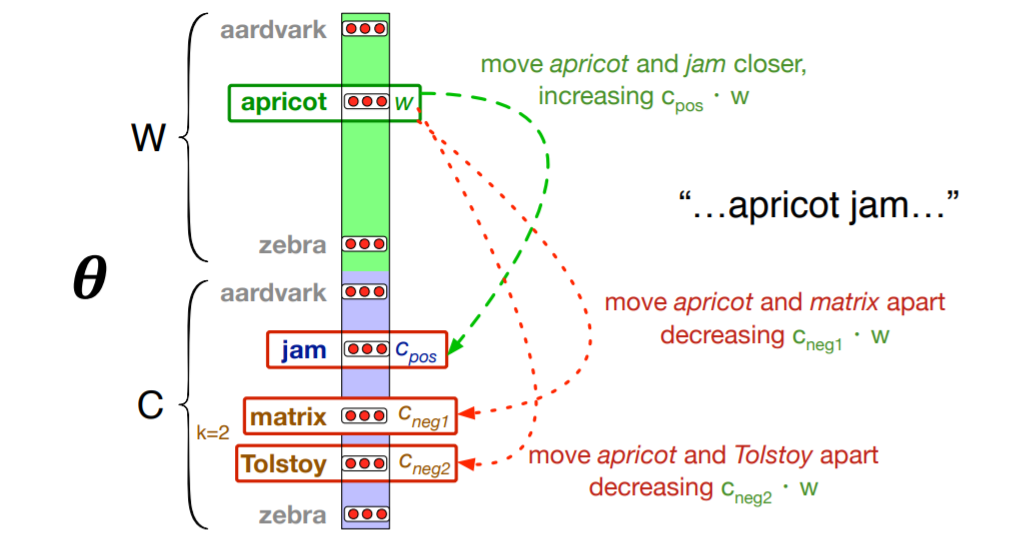
对于每个目标词w及L=+-d的窗口, 得到2d个正例, 再为每个正例随机分配k个负例(k是参数),即“noise word”。
noise word的选择根据每个词的加权出现频率:

举个例子:

学习算法的目标是调节嵌入向量使其:
• 最大化从正例中提取的目标词、上下文词对(w,cpos)的相似度
• 最小化负例词对(w, cneg) 的相似性。
一个正例及其k个负例的损失函数(假设相互独立):
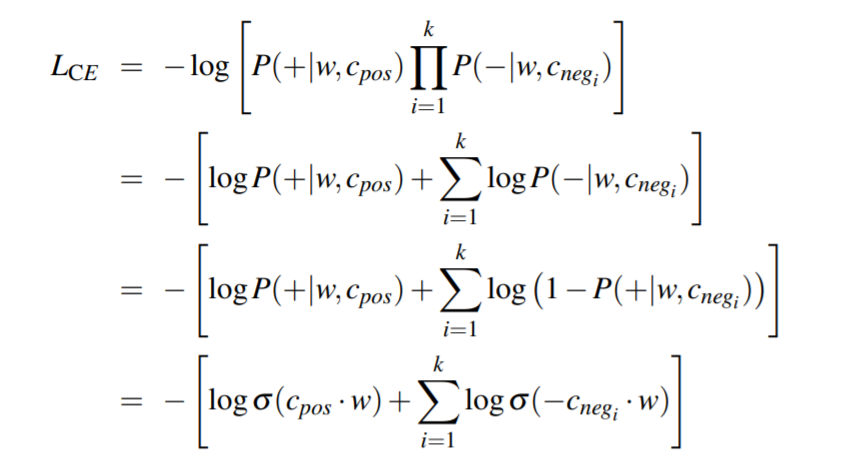
用随机梯度下降进行训练:
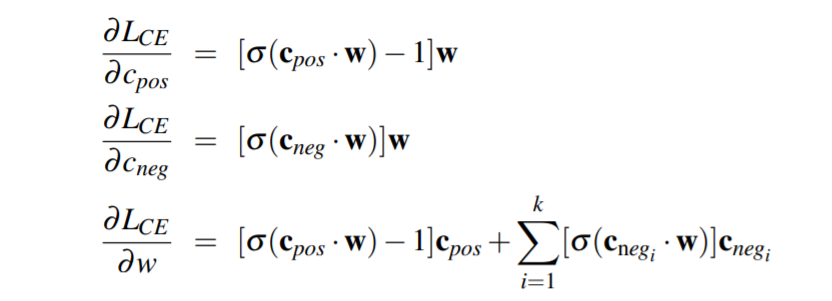
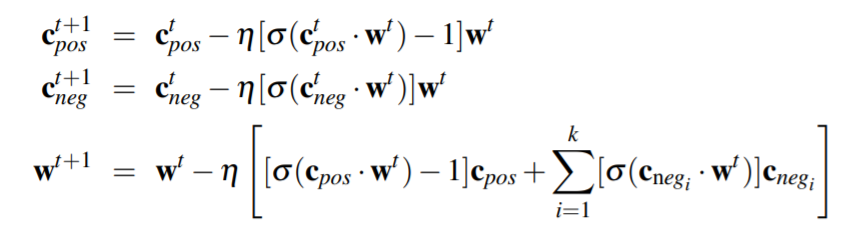
获得W矩阵和C矩阵,最后的嵌入矩阵可以为W, 也可以选择W与C的平均

