【Stanford - Speech and Language Processing 读书笔记 】2、Regular Expression,Text Normalization,Edit distance
1、Introduction
正则表达式(regular expression):模式匹配,用于从文本中抽取特殊的词句。
文本规范化(text normalization) :将文本转化为更为方便、规范的格式,其中包括词标记化(word tokenization)、词形还原(lemmatization)、词干化(stemming)、语句分割(sentence segmenting)。
编辑距离(edit distance):度量两个词语相似程度的一种衡量指标,根据一个词语对字母的删除、插入、替换操作的次数来计算编辑距离。
2、Regular Expression
基本规则:
1、大小写敏感(case sensitive)
2、字符析取(disjunction of characters)

3、范围(range)

4、否定(negation): ^直接位于方括号 [ 之后

5、问号(question mark): ? 表示前面的字符或什么都没有

6、重复
* : 前面的字符重复0次或若干次
+ :前面的字符重复1次或若干次
例如 / [ 0 - 9 ] [ 0 - 9] * / 和 / [ 0 - 9 ] + / 均表示一个自然数
7、通配符(wildcard): 代替任何单个字符(除了回车)

8、锚定表达式(anchors)

例如 / ^ The dog\. $ / 表示一个句子 The dog.
9、析取(disjunction): disjunction operator / pipe symbol - |
例如 / cat | dog / 匹配 cat 或 dog
10、分组(grouping):括号()具有最高优先级
例如 / guppy | ies / 匹配 guppy 或 ies ; / gupp ( y | ies ) / 匹配 guppy 或 guppies
11、优先级(precedence)

12、更多



13、替换,捕获组(Substitution, Capture Groups)
替换操作符如 s/regexp1/pattern/ 可以让一个正则表达式被另一个表达式替换,常常在python或Unix命令(vim或sed)中使用
数字符号 \1 可以 参考之前括号内的,如 s/([0-9]+)/<\1>/ 可以在数字外面加上括号, /the (.*)er they were, the \1er they will be/ 等等
捕获组: 如 /the (.*)er they (.*), the \1er we \2/ ; \1 对应第一个括号内的,\2对应第二个括号内的。它可以匹配the faster they ran, the faster we ran,但不能匹配faster they ran, the faster we ate。 \3, \4...同理
如果某个模式不希望被捕获,可以使用 / ? : pattern / ,它称为non-capturing group。 例如/(?:some|a few) (people|cats) like some \1/ 可以匹配some cats like some cats 而非 some cats like some a few
14、先行断言(lookahead assertions)
利用(?运算符—— 如果模式出现,运算符 (?= pattern) 为真,但宽度为零,即匹配指针不前进;运算符(?!模式)仅在模式不匹配时返回 true,但同样为零宽度,并且匹配指针不前进。
负前瞻通常用于以下情况,正在解析一些复杂的模式,但想排除特殊情况。例如 假设我们想在一行的开头匹配任何不以“Volcano”开头的单词:
/ ˆ (?!Volcano) [A-Za-z]+ /
3、Word and Copora
词的定义? 是否算上标点,是否算上停顿、结巴导致的语气词,词与词根? —— 根据不同的任务而定
几个术语: lemma : 具有相同词干、相同的主要词性和相同的词义的一组词, 如cat和cats
wordform : 单词的完整变形或派生形式
word tokens : 文本中单词的个数(相同的单词也重复计入),数量用N表示
word types : 文本中不同的单词个数(每一种单词仅记一次),数量用|V| 表示

Herdan’s Law (Herdan, 1960) or Heaps’ Law (Heaps, 1978):
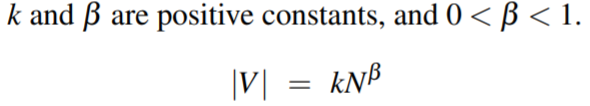
一般地,\beta在0.67-0.75之间
语料库(Copera): 具有多样性(语言、体裁、作者、时代……)
语言是随情境而改变的,当在一个语料库中创建模型时,需要考虑语料库的某些细节,如语言、目的、出处等。
所以,建议语料库的创建者制作一个数据表,包括例如:
动机、情境、语言、演讲者的描述与统计、收集过程、注解过程、版权和产权 等等
4、Text Normalization
4.1 词标记化(word tokenization): 将文本标记为一个个单词
简陋的方法——Unix工具,包括命令tr(单词转换,例如大小写),sort(按首字母排序),uniq(合并相同的单词并计数)
例如对莎士比亚的一片文章执行如下命令:

更为精细的方法,应该要做到:
1、对标点的处理——逗号、句号常常是分段的标志,但也有可能在单词内(如 Mr.)
2、扩写缩写单词,如 we' re -> we are
3、命名实体识别,如 New York
一些语言如汉语、日语、泰语,使用的文字而非单词, 常常使用神经序列模型(neural sequence model)
字节对编码(byte-pair encoding for tokenization)
对于未知单词问题,引入子词(subword)——比标记词还要短小
字节对编码算法:
1、检测语料库
2、选择相邻次数最多的两个元素
3、合并这两个元素,并将其替代原来的元素
4、返回1,持续检测、计数、合并,直到合并k(参数)次产生k个新元素
如下例子:
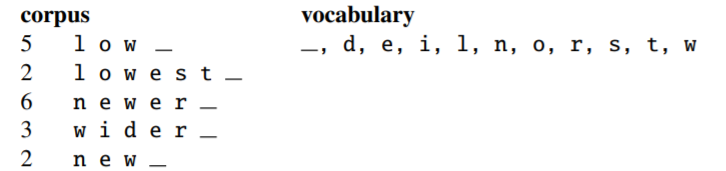




4.2 词标准化(word normalization)
将词语转化为标准形式, 为具有多个形式的词选择单一的形式。
应用:信息恢复(information retrieval), 信息抽取(information extraction)
字符折叠(case folding)
大写字母转小写
广泛应用于信息恢复、语音识别(speech recognition)
也不总是适用,如情感分析(sentiment analysis)、文本分类(text classification)等
词形还原(Lemmatiziation)
觉得具有相同词根的两个单词,如 be/am/is/are、dinners/dinner
方法:形态解析(morphological parsing) 对语素(morpheme)的研究 —— 1、词干(stem) 2、词缀(affixes)
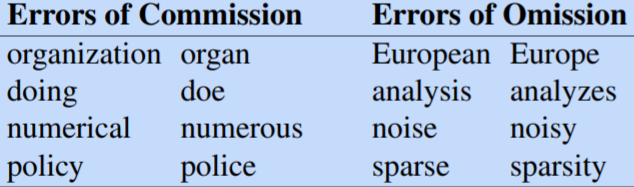
一种比较粗糙的算法——The Porter Stemming
该算法基于串联运行的一系列重写规则,作为级联,其中每次传递的输出作为输入提供给下一次传递,规则的例子如下:

算法应用于如下的段落:

算法可能出现过泛化或欠泛化的错误
4.3 句子分割
有力的工具——标点符号
但有时标点的作用是模糊的,例如Mr.
为解决这类问题,可以结合词标准化和句子分割; 也可以使用某些特殊的字典
5、Minimum Edit Distance
编辑距离(edit distance),用于衡量两个字符串的相似程度
策略:计算从一个字符串转变为另一个字符串所需要的最小操作(插入, 删除, 替换)次数。
这里插入, 删除, 替换可以赋不同的代价(距离),一般地插入, 删除, 替换的代价分别为1,1,1或1,1,2
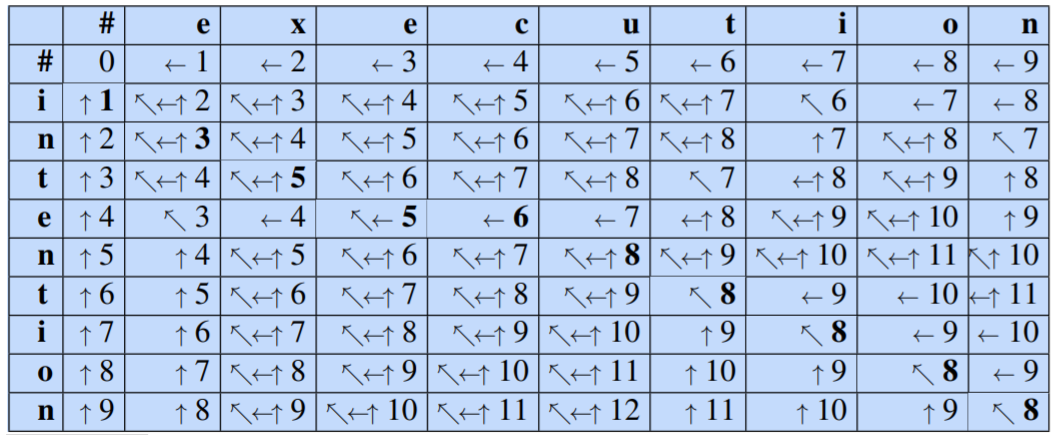
例如下图,用上述两种距离代价计算的编辑距离分别为5和8
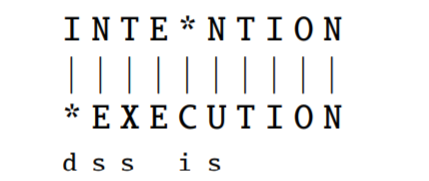
算法:动态规划
给定两个字符串,长度为 n 的源字符串 X 和长度为 m 的目标字符串 Y,我们将 D[i, j] 定义为 X[1..i] 和 Y[1.. j] 之间的编辑距离 , 即 X 的前 i 个字符和 Y 的前 j 个字符。因此 X 和 Y 之间的编辑距离为 D[n,m]。采用如下算法:
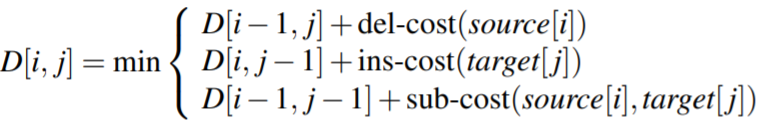
当插入、删除代价为1, 替换插入代价为2:
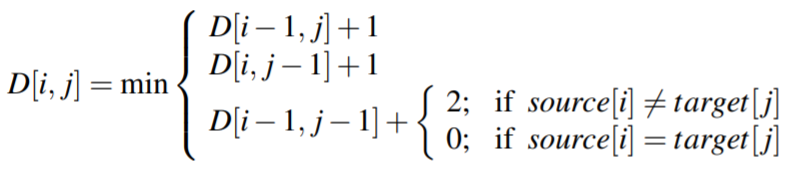
算法伪代码:

直观的例子:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号