

ElasticSearch安装与使用
1、安装ES和Kibana
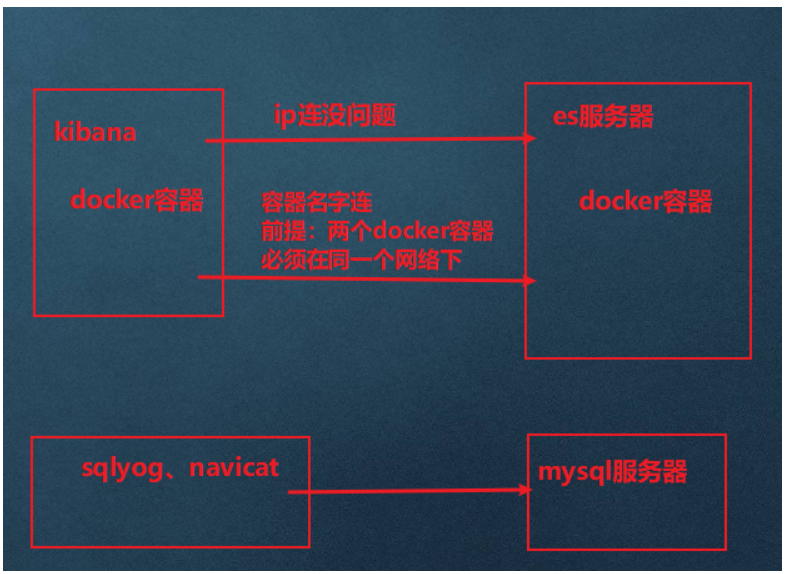
kibana和ES的关系
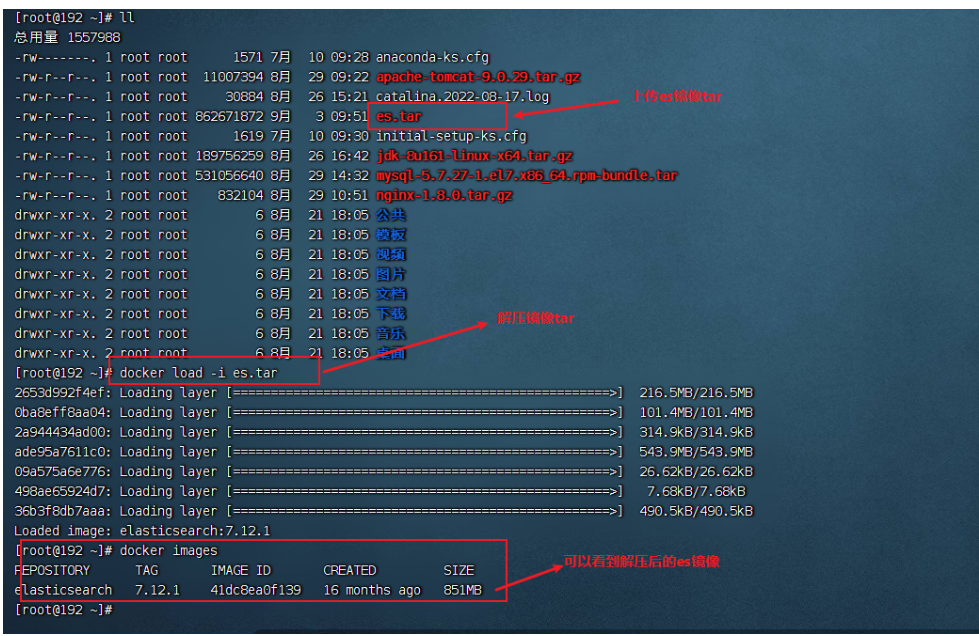
ES安装
可以自己使用docker pull拉取镜像,但是因为ES比较大,可能比较慢,这里建议大家用解压包的方式获得镜像
获取镜像
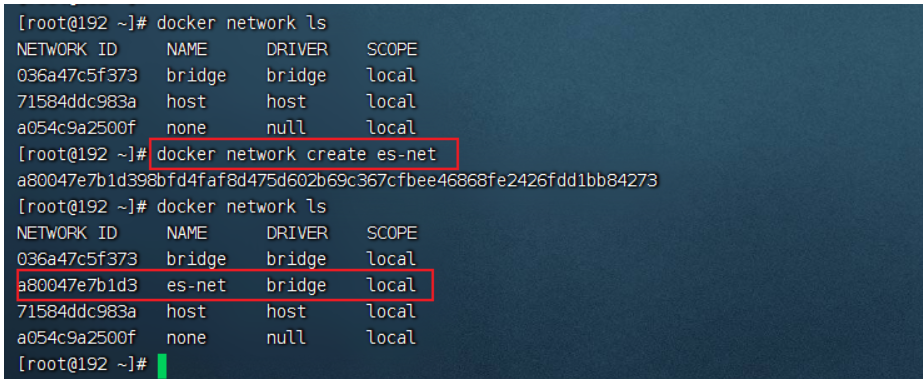
启动容器
- 创建网卡(方便kibana通过es容器名连接)
- 启动容器
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定es的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定es的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定es的插件目录--privileged:授予逻辑卷访问权--network es-net:加入一个名为es-net的网络中-p 9200:9200:端口映射配置

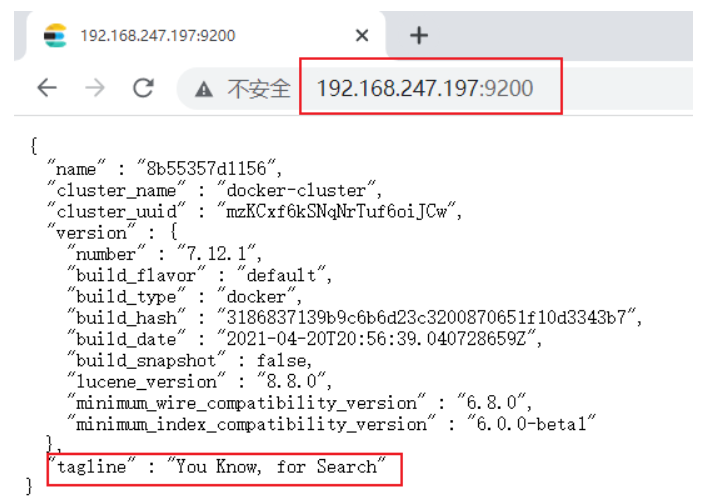
浏览器访问检测
启动会有点慢,需要耐心等待下。另外虚拟机的内存最少设置为2G,否则内存不够用
Kibana安装
获取镜像
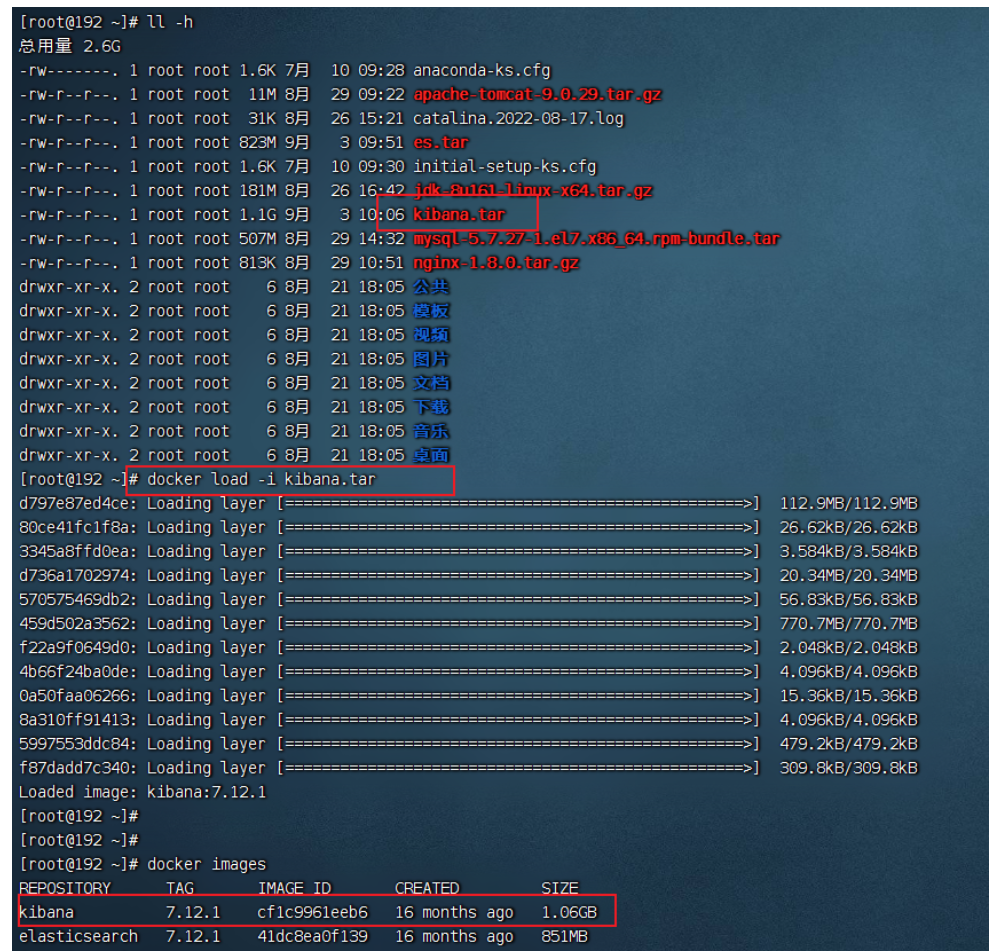
启动容器
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
命令解释
--network es-net:加入一个名为es-net的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://es:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch-p 5601:5601:端口映射配置
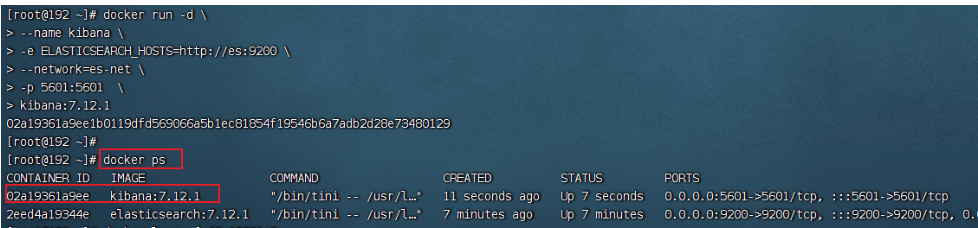
浏览器访问检测
ik分词器安装
查看es插件挂在的数据卷目录
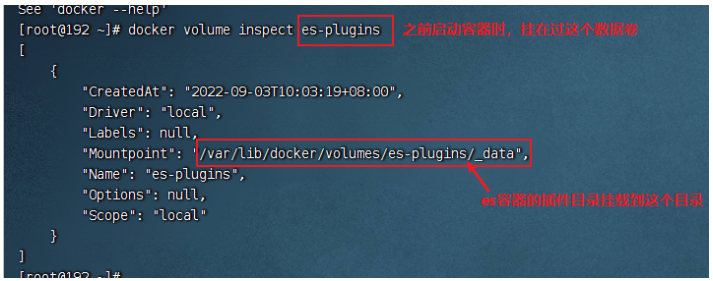
上传ik插件到挂在的目录
将资料中的ik压缩包解压后,上传
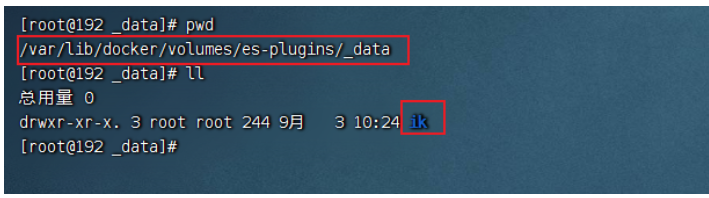
重启es容器
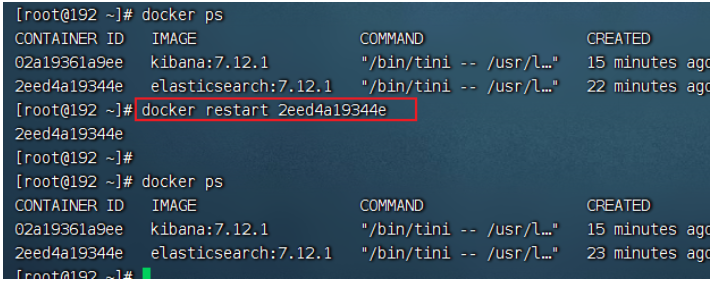
配置自己的扩展词&忽略词
- 修改配置,增加扩展词&忽略词配置
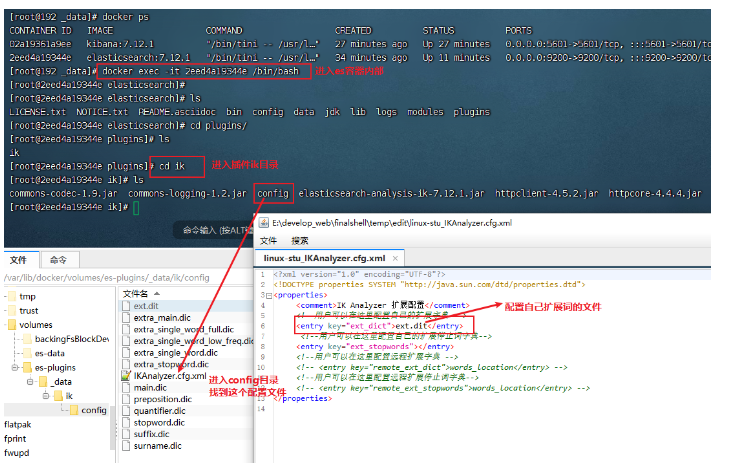
- 配置自己的扩展词
- 重启es容器,再次测试观察结果
5、索引库操作(DSL)
mapping映射属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- properties:该字段的子字段
例如下面的json文档:
{
"age": 21,
"weight": 52.1,
"isMarried": false,
"info": "营养师",
"email": "zy@1000phone.com",
"score": [99.1, 99.5, 98.9],
"name": {
"firstName": "云",
"lastName": "赵"
}
}
对应的每个字段映射(mapping):
- age:类型为 integer;参与搜索,因此需要index为true;无需分词器
- weight:类型为float;参与搜索,因此需要index为true;无需分词器
- isMarried:类型为boolean;参与搜索,因此需要index为true;无需分词器
- info:类型为字符串,需要分词,因此是text;参与搜索,因此需要index为true;分词器可以用ik_smart
- email:类型为字符串,但是不需要分词,因此是keyword;不参与搜索,因此需要index为false;无需分词器
- score:虽然是数组,但是我们只看元素的类型,类型为float;参与搜索,因此需要index为true;无需分词器
- name:类型为object,需要定义多个子属性
- name.firstName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
- name.lastName;类型为字符串,但是不需要分词,因此是keyword;参与搜索,因此需要index为true;无需分词器
创建索引(PUT)

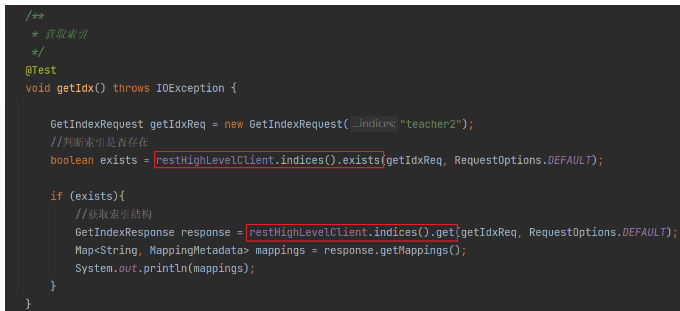
获取索引(GET)
修改索引(PUT)
注意,不能改变原来索引的映射,因为倒排索引构建非常消耗时间,所以不允许修改。
但是可以在原来映射的基础上,新增字段。

删除索引(DELETE)
6、文档操作(DSL)
创建文档(POST)
POST /teacher/_doc/1
{
"age": 18,
"info": "营养师帮助人们健康饮食,很好",
"email": "zs@1000phone.com",
"name": {
"firstName": "张",
"lastName": "三"
}
}
POST /teacher/_doc/2 /*指定id创建*/
{
"age": 28,
"info": "营养师帮助人们健康饮食",
"email": "ww@1000phone.com",
"name": {
"firstName": "王",
"lastName": "五"
}
}
POST /teacher/_doc /*不指定id创建,会随机自动生成*/
{
"age": 38,
"info": "营养师帮助健康饮食",
"email": "ls@1000phone.com",
"name": {
"firstName": "李",
"lastName": "四"
}
}
删除文档(DELETE)
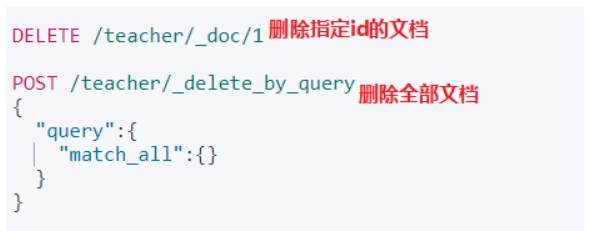
修改文档(POST)
/*修改--全量修改(当id对应的文档存在,删除原文档,新建现在的文档)*/
POST /teacher/_doc/2 /*_doc和新增文档语法一致, 如果该id存在,是更新操作,如果该id不存在,就是新增操作*/
{
"age": 28,
"info": "营养师帮助人们健康饮食",
"email": "ww@1000phone.com",
"name": {
"firstName": "王",
"lastName": "五"
}
}
/*修改--增量(部分)修改*/
POST /teacher/_update/2 /*_update,在原有文档记录的基础上个,新增新的内容*/
{
"doc":{
"email": "ww@1000phone.com"
}
}
查询文档(GET)
简单查询
全文检索-单字段匹配
/*全文检索 -单字段检索 饮食 --> 饮食,饮,食*/
GET /teacher/_search
{
"query":{
"match":{
"info":"饮食"
}
}
}
全文检索-多字段匹配
/*全文检索 -多字段检索
检索info或者name.lastname中包含的*/
GET /teacher/_search
{
"query":{
"multi_match":{
"query":"饮食",
"fields":["info","name.lastname"]
}
}
}
精准查询-term
/*精准查询 -term查询
term查询中关键词是不会分词的,info中必须包含上述这个词的信息*/
GET /teacher/_search
{
"query":{
"term":{
"info":{
"value":"饮食"
}
}
}
}
精准查询-range
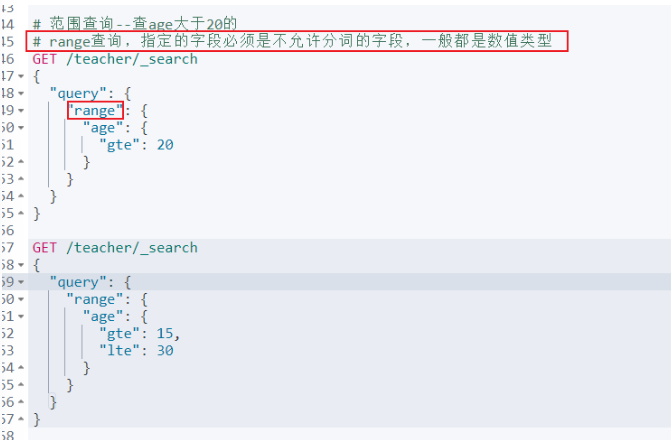
布尔查询-多条件查询
must
/*查询中info包含饮食,且年龄大于20
must必须的,多个条件之间是and关系*/
GET /teacher/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"info":"饮食"
}
},
{
"range":{
"age":{
"gte":20
}
}
}
]
}
}
}
shoud
/*查询中info包含饮食,且年龄大于20
must可选的,多个条件之间是or关系*/
GET /teacher/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"info":"饮食"
}
},
{
"range":{
"age":{
"gte":20
}
}
}
]
}
}
}
must_not
/*查询中info包含饮食,但fistname不可以是 李
must_not 不允许,对条件进行取反操作,一般用来过滤*/
GET /teacher/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"info":"饮食"
}
}
],
"must_not":[
{
"term":{
"name.firstname":{
"value":"李"
}
}
}
]
}
}
}
filter
/*查询中info包含饮食,且年龄大于20
filter过滤,在原本数据的基础上进行一些过滤,过滤条件是不参与算分的,所以在进行条件过滤时,使用filter效率会提高*/
GET /teacher/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"info":"饮食"
}
}
],
"filter":[
{
"range":{
"age":{
"gte":20
}
}
}
]
}
}
}
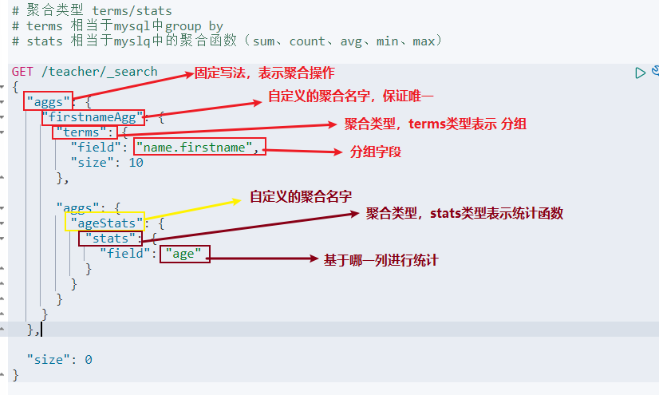
聚合查询
- 分组聚合
相当于: select avg(age),sum(age),... from teacher group by firstname;
查询语句
查询结果

- 不分组全文档聚合
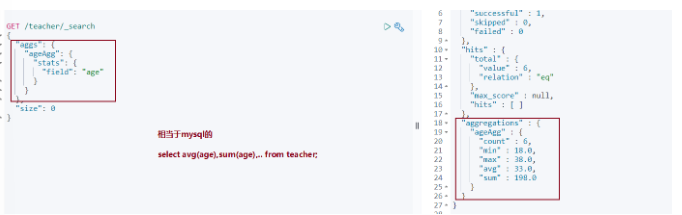
- 不分组带条件聚合
查询结果处理
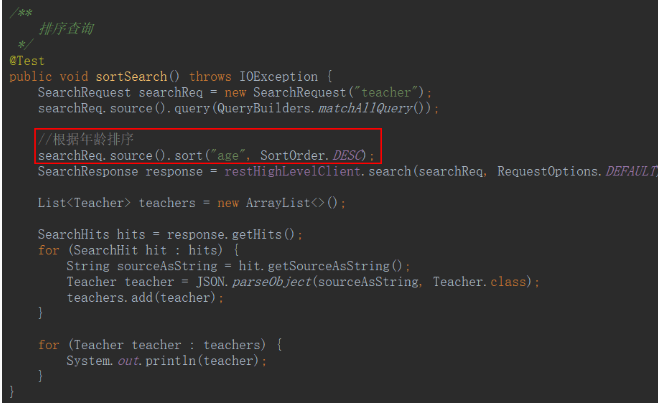
排序

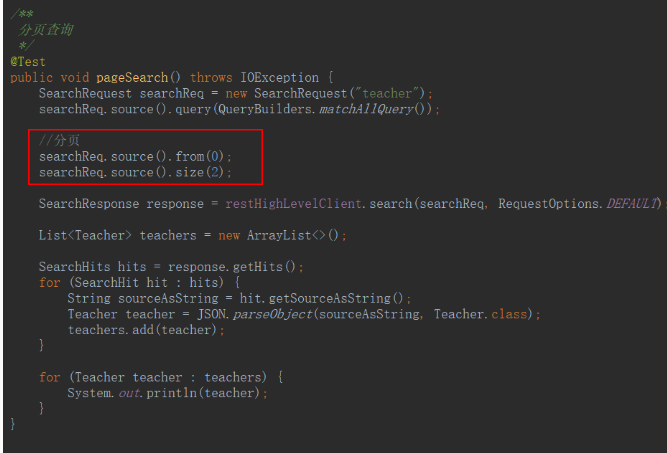
分页
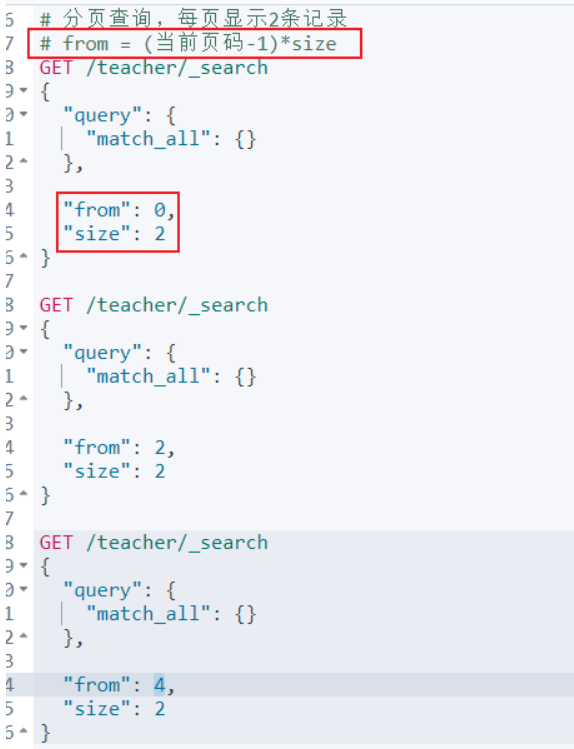
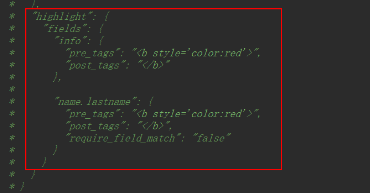
高亮

7、索引操作(JAVA)
集成es环境
- 引入依赖
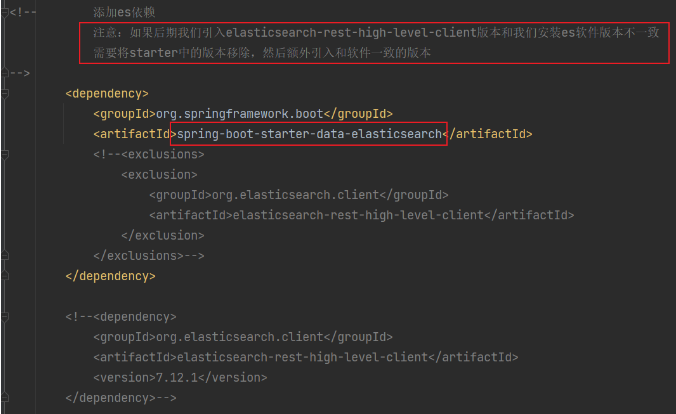
- 编写配置
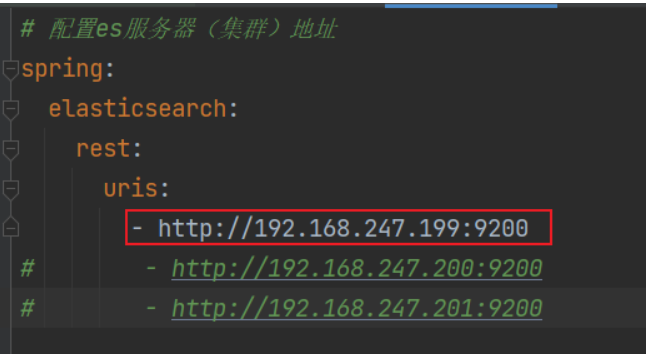
- 注入核心对象,执行操作
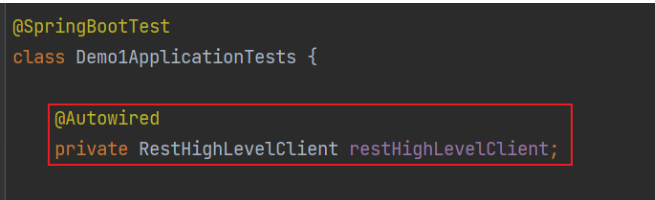
创建索引
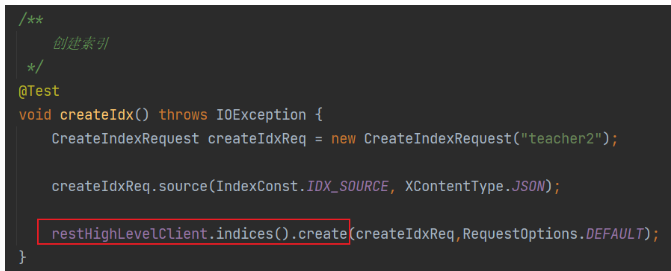
删除索引
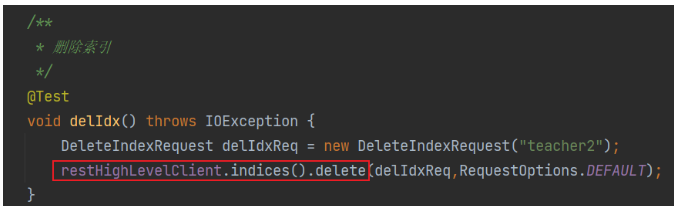
修改索引(没有)
查询索引
8、文档操作(JAVA)
创建文档
/*
新增文档
*/
@Test
void createDoc() throws IOException {
IndexRequest idxReq = new IndexRequest("teacher").id("11");
Teacher teacher = new Teacher();
teacher.setAge(48);
teacher.setInfo("营养师");
teacher.setEmail("yy@1000phone.com");
Name name = new Name();
name.setFirstname("陈");
name.setLastname("飞");
teacher.setName(name);
idxReq.source(JSON.toJSONString(teacher),XContentType.JSON);
restHighLevelClient.index(idxReq,RequestOptions.DEFAULT);
}
删除文档
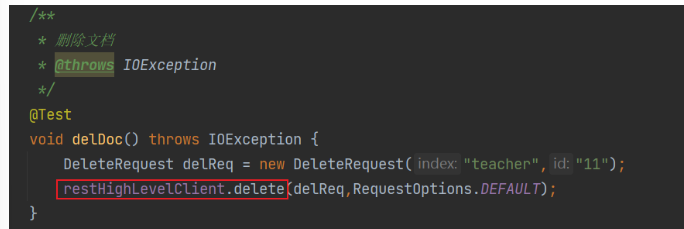
修改文档
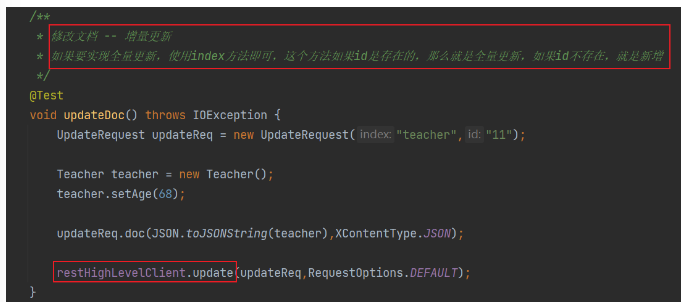
查询文档
简单查询
- 查询单个文档
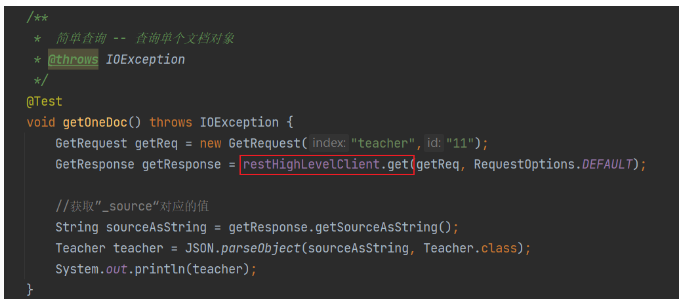
)
- 查询所有文档
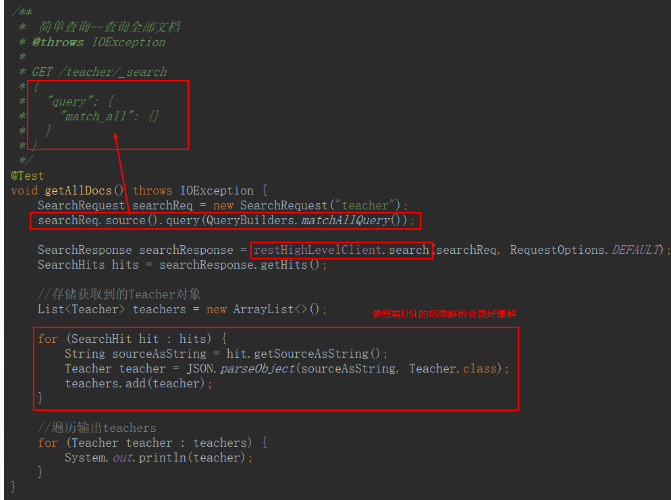
全文检索-单字段匹配
/*
全文检索 -单字段检索
GET /teacher/_search
*/
@Test
void matchSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
searchRequest.source().query(QueryBuilders.matchQuery("info","饮食"));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
全文检索-多字段匹配
/*
全文检索 -多字段匹配
GET /teacher/_search
*/
@Test
void multiMatchSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
searchRequest.source().query(QueryBuilders.multiMatchQuery("饮食","info","name.lastname"));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
精准查询-term
/*
-精确查询-term
GET /teacher/_search
*/
@Test
void termSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
searchRequest.source().query(QueryBuilders.termQuery("info","饮食"));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
精准查询-range
/*
-精确查询-range
GET /teacher/_search
*/
@Test
void rangeSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
searchRequest.source().query(QueryBuilders.rangeQuery("age".gte(20)));
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
布尔查询-多条件查询
/*
布尔条件查询
GET /teacher/_search
*/
@Test
void matchSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("teacher");
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
List<QueryBuilder> should = boolQuery.should();
should.add(QueryBuilders.rangeQuery("age".gte(20)));
should.aad(QueryBuilders.termQuery("name.firstname","李"));
searchRequest.source().query(boolQuery);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest,RequestOptions.DEFAULT);
List<Teacher> teachers = new ArrayList<>();
SearchHits hits = response.getHits();
for(SearchHit hit : hits){
String sourceAsString = hit.getSourceAsString();
Teacher teacher = JSON.parseObject(sourceAsString,Teacher.class);
teachers.add(teacher);
}
teachers.forEach(System.out::println);
}
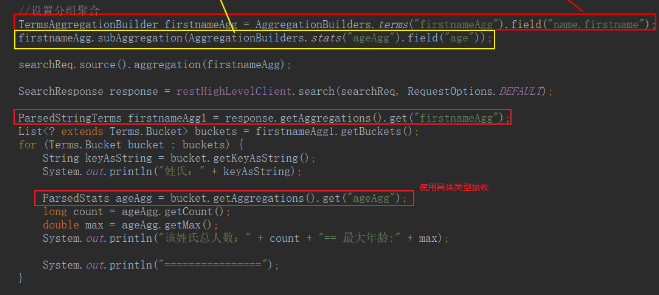
聚合查询
- 分组聚合统计
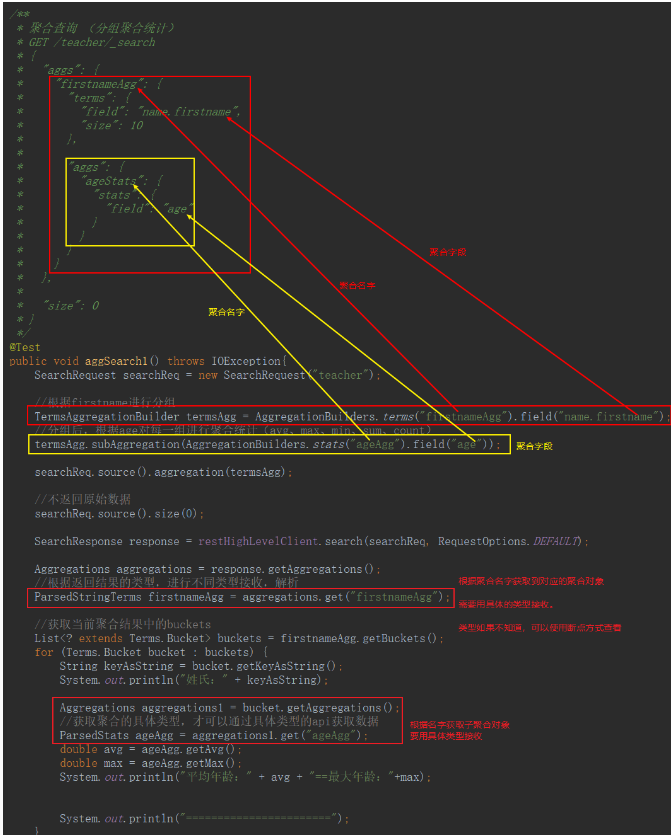
- 全索引聚合统计
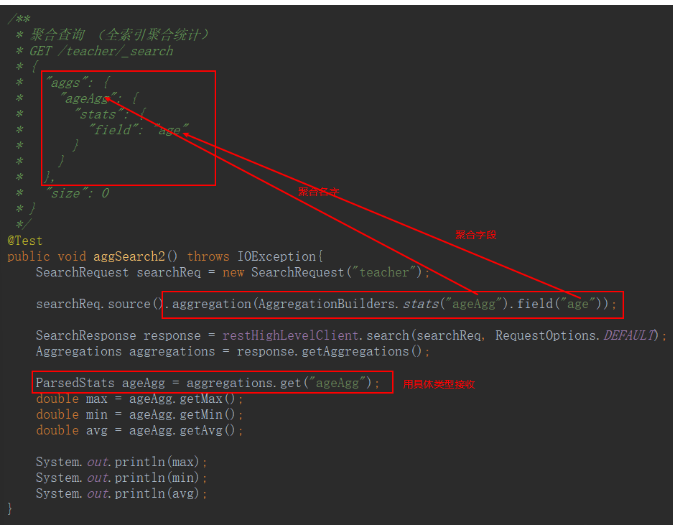
- 条件筛选后聚合统计
/*
聚合查询 条件过滤后聚合统计
GET /teacher/_search
*/
@Test
void aggSearch3() throws IOException {
SearchRequest searchReq = new SearchRequest("teacher");
//设置查询条件
searchReq.source().query(QueryBuilders.matchQuery("info","饮食"));
查询结果处理
排序
分页
高亮
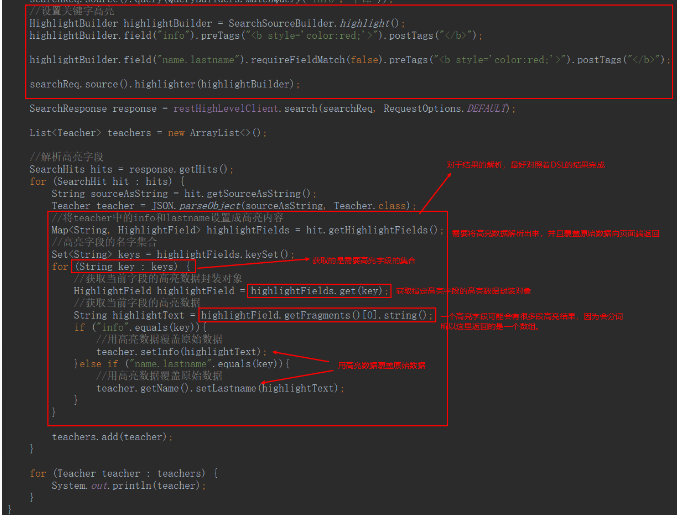
节点类型
Master节点:管理索引:索引创建、索引删除;DataNode节点中分片管理:分片信息记录、分片划分;不负责数据的写入和检索。这类节点内存可以小一些,但是服务器要稳定
DataNode节点:负责数据的写入和检索,所有DataNode节点没有主从节点的关系。但是节点上会存在主从分片。这类节点要求内存大
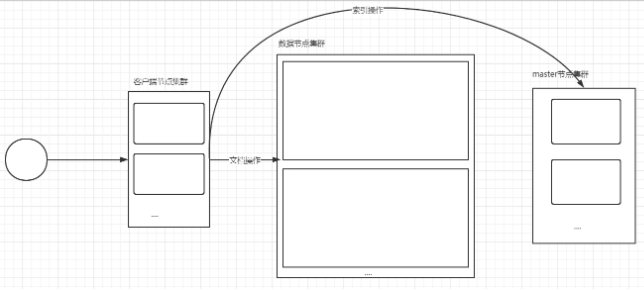
客户端节点:不负责任何数据存储操作,这类节点主要用来接收客户端的请求,实现负载均衡
在实际部署es集群时,上述三类节点都需要部署,而且这三类节点要求分开部署
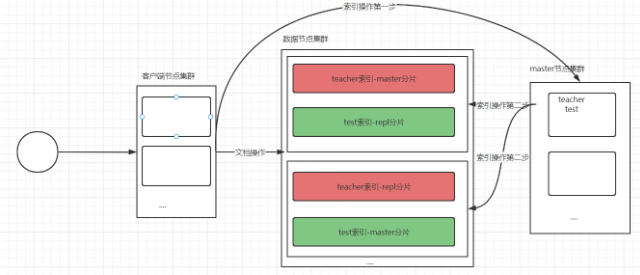
集群中写一条数据的过程
- 数据节点分片含义
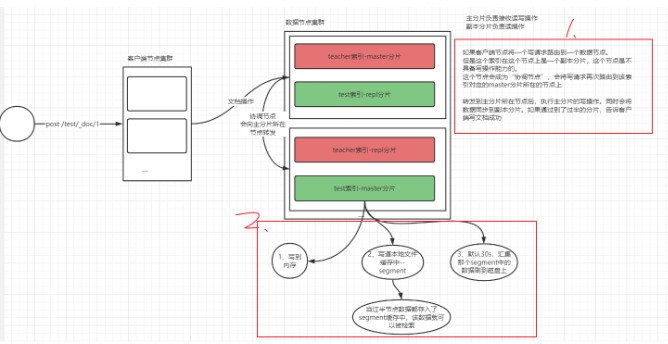
- 写一条文档数据
es删除文档机制
es中文档是不可以修改不可删除。当我们在删除文档时,文档数据并不是真的从es中被删掉。有一个惰性删除效果。
在每个segment文件中会维护一个.del文件,当我们删除文档时,会在.del文件中记录这个被删除文档的id。当我们检索数据时,这个被记录的id文档是不会被检索出来的。
当segment大小达到一定程度,为了提升读取数据效率,会对segment进行合并。在合并成新的segment文件时,原本被记录在.del中的数据是不参与合并。此时这个文档数据才会被真正删除。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号