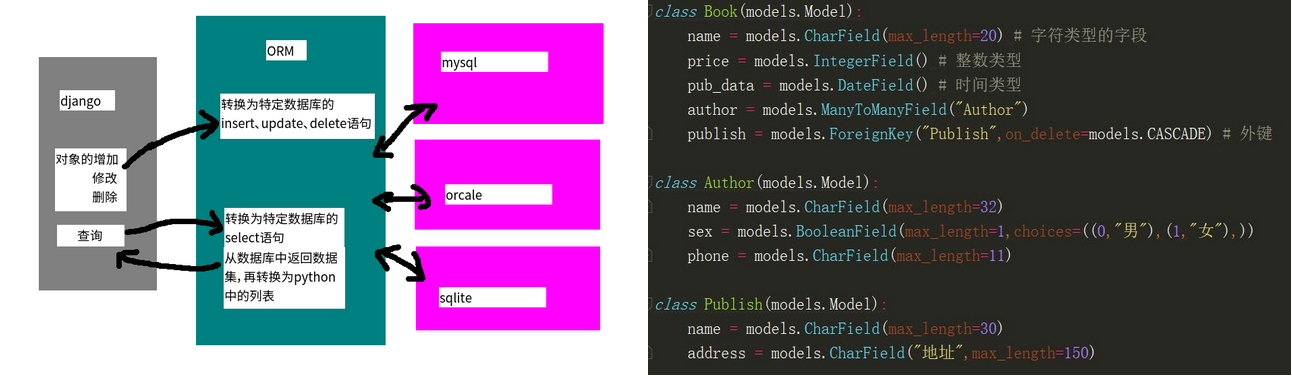
Django -- ORM
什么是orm?
MVC框架中重要的一部分就是ORM,实现了数据模型与数据库的解耦,即数据模型不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库。
ORM是对象关系映射的简称,主要任务是:
- 根据对象的类型生成表结构
- 将对象、列表操作,转换成SQL语句(或其他数据库的语句)
- 将SQL查询到的结果转换为对象、列表
- 类名对应 ------> 数据库中的表名
- 类属性对应 -----> 数据库里的字段
- 类实例对应 -------> 数据库表里的一行数
![]()
ORM的优势:
- ORM使得我们的通用数据库交互变得简单易行,而且完全不用考虑该死的SQL语句。快速开发,由此而来。
- 可以避免一些新手程序猿写sql语句带来的性能问题。
- 如果数据库迁移,只需要更换Django的数据库引擎即可。
ORM的缺点:
- 性能有所牺牲,不过现在的各种ORM框架都在尝试各种方法,比如缓存,延迟加载登来减轻这个问题。效果很显著。
- 对于个别复杂查询,ORM仍然力不从心,为了解决这个问题,ORM一般也支持写raw sql。
- 通过QuerySet的query属性查询对应操作的sql语句
数据库的配置
1.默认支持
Django默认支持sqlite,mysql, oracle,postgresql数据库。默认使用sqlite的数据库,默认自带sqlite的数据库驱动 , 引擎名称:django.db.backends.sqlite3。
2.mysql驱动程序
- MySQLdb(mysql python)【python2中的驱动】
- mysqlclient
- MySQL
- PyMySQL(纯python的mysql驱动程序)【python3中的驱动】
3.创建数据库
配置前必须先创建数据库
create database Django_books charset utf8; #创建支持中文的数据库
4.更改项目中settings.py的数据库设置
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'Django_Books', #你的数据库名称
'USER': 'root', #你的数据库用户名
'PASSWORD': '123456', #你的数据库密码
'HOST': 'localhost', #你的数据库主机,留空默认为localhost
'PORT': '3306', #你的数据库端口
}
}
5.配置驱动
Django默认导入的驱动是MySQLdb,MySQLdb对python3的支持有很大问题,所以要换成PyMySQL:在项目名文件夹下的__init__.py中:
import pymysql pymysql.install_as_MySQLdb() # 告诉Django使用pymysql驱动程序
扩展:查看ORM操作执行的原生sql语句,在settings.py中增加:
LOGGING = {
'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
表(模型)的创建
示例:作者、书籍和出版社之间的关系
from django.db import models
class Book(models.Model):
name = models.CharField(max_length=20)
price = models.IntegerField()
pub_data = models.DateField()
author = models.ManyToManyField("Author")
publish = models.ForeignKey("Publish",on_delete=models.CASCADE)
class Author(models.Model):
name = models.CharField(max_length=32)
sex = models.BooleanField(max_length=1,choices=((0,"男"),(1,"女"),))
phone = models.CharField(max_length=11)
class Publish(models.Model):
name = models.CharField(max_length=30)
address = models.CharField("地址",max_length=150)
1.每个数据模型(类)都是django.db.models.Model的子类,它的父类Model包含了所有必要的和数据库交互的方法。
2.每个类就相当于单个数据表,属性名就是字段名
字段类型介绍
AutoField 自增列 = int(11) 如果没有的话,默认会生成一个名称为 id 的列,如果要显示的自定义一个自增列,必须将给列设置为主键 primary_key=True。
CharField 字符串字段 必须有 max_length 参数
BooleanField 布尔类型=tinyint(1) 不能为空,Blank=True
ComaSeparatedIntegerField 用逗号分割的数字=varchar 继承CharField,所以必须 max_lenght 参数
DateField 日期类型 date 对于参数,auto_now = True 则每次更新都会更新这个时间;auto_now_add 则只是第一次创建添加,之后的更新不再改变。
DateTimeField 日期类型 datetime 同DateField的参数
Decimal 十进制小数类型 = decimal 必须指定整数位max_digits和小数位decimal_places
EmailField 字符串类型(正则表达式邮箱) =varchar 对字符串进行正则表达式
FloatField 浮点类型 = double
IntegerField 整形
BigIntegerField 长整形
不同的整型类型integer_field_ranges = {
'SmallIntegerField': (-32768, 32767),
'IntegerField': (-2147483648, 2147483647),
'BigIntegerField': (-9223372036854775808, 9223372036854775807),
'PositiveSmallIntegerField': (0, 32767),
'PositiveIntegerField': (0, 2147483647),
}
IPAddressField 字符串类型(ip4正则表达式)(已弃用,用13、)
GenericIPAddressField 字符串类型(ip4和ip6是可选的)参数protocol可以是:both、ipv4、ipv6
验证时,会根据设置报错
NullBooleanField 允许为空的布尔类型
PositiveIntegerFiel 正Integer
PositiveSmallIntegerField 正smallInteger
SlugField 减号、下划线、字母、数字
TextField 字符串=longtext
TimeField 时间 HH:MM[:ss[.uuuuuu]]
URLField 字符串,地址正则表达式
BinaryField 二进制
ImageField 图片
FilePathField 文件
3.字段参数介绍
null 是否可以为空
default 默认值
primary_key 主键
choices: 一个用来选择值的2维元组。第一个值是实际存储的值,第二个用来方便进行选择。如:SEX_CHOICES= (( ‘F’,'Female’),(‘M’,'Male’),)
gender = models.CharField(max_length=2,choices = SEX_CHOICES)
db_column 列名
db_index 索引(db_index=True)
unique 唯一索引(unique=True)
unique_for_date 只对日期索引
unique_for_month 只对月份索引
unique_for_year 只对年做索引
blank django的 Admin 中添加数据时是否可允许空值
editable 如果为假,admin模式下将不能改写。缺省为真
verbose_name Admin中字段的显示名称
validator_list 有效性检查。非有效产生 django.core.validators.ValidationError 错误
4.模型之间的关系(表与表之间)
有三种关系:一对一,一对多,多对多
一对一:实质就是在主外键的关系基础上,给外键加了一个UNIQUE=True的属性;OneToOne("UserGroup")
一对多:就是主外键关系;ForeignKeyField("UserGroup",to_field="gid",default=1,on_delete=models.CASCADE)
多对多:ORM会为我们自动创建第三张表(当然我们也可以自己创建第三张表:两个foreign key);ManyToManyField("UserGroup")
参数:“UserGroup” 关联的另一张表的表名;
to_field="gid" 可省略。另外一张表的字段,默认是主键;
on_delete=models.CASCADE(
CASCADE:这就是默认的选项,级联删除,你无需显性指定它。
PROTECT: 保护模式,如果采用该选项,删除的时候,会抛出ProtectedError错误。
SET_NULL: 置空模式,删除的时候,外键字段被设置为空,前提就是blank=True, null=True,定义该字段的时候,允许为空。
SET_DEFAULT: 置默认值,删除的时候,外键字段设置为默认值,所以定义外键的时候注意加上一个默认值。)
5.建好表后,在命令行执行一下两条语句生成映射文件并提交数据库执行建表
python manage.py makemigrations 在应用文件夹内生成映射文件(000开头的py文件) python manage.py migrate 提交数据库执行建表
表的操作
一.增添
增添表记录
单表:
create()方法:
Book.objects.create(name="Python基础",price=100)
或
Book.objects.create(**{"name":"Python基础","price":"100"})
save()方法:
b = Book(name="Python基础",price=100) # 创建对象
b.save() # 将对象存数据库
或
b = Book()
b.name="Python基础"
b.price=100
b.save()
有外键时:
Book.objects.create(name="",price="",pub_date="",publish_id=2) # 外键关联表的id
或
objcet = Publish.objects.get();
Book.objects.create(name="",price="",pub_date="",publish=object) # 外键=对象
增添多对多之间的关联关系
情景1:使用ManyToMany自动创建第三张表
add()方法:【调用add的主体必须是单个model对象】
例如:为已有的一本书增添作者
author_obj = Author.objects.filter(name="alex")
book_obj = Book.objects.get(id=2)
book_obj.author.add(*author_obj) 这里的author指的是Author表。添加一个列表* 添加一个字典**
或:
book_obj = Book.objects.filter(name="Python")
author_obj = Author.object.get(id=1)
author_obj.book_set.add(*book_obj) 这里的book指的是Book表。
注意两种方式 _set 的区别,源于models.py中建表的author字段
情景2:自己手动创建的第三张表BookToAuthor
models.BookToAuthor.objects.create(author_id=1,Book_id=2)
二.删除
删除表记录
Book.objects.filter(name="Python").delete() # 看上去删除了一条消息,实际上还删除了book_author表中的数据, 这是django默认的级联删除
删除多对多之间的关联关系
clear()和remove()方法 【调用这两种方法的主体必须是单个对象】
remove()方法: remove方法用来删除某个对象和某些对象的关联关系
为已有的一本书删除某个作者
author_obj = Author.objects.filter(name="alex")
book_obj = Book.objects.get(name="Python")
book_obj.author.remove(*author_obj) remove(3) 意思是删除id=3的作者与本书的关系
或:
book_obj = Book.objects.filter(name="Python")
author_obj = Author.object.get(name="Python")
author_obj.book_set.remove(*book_obj)
clear()方法: clear方法用来删除某个对象和所有对象的关联关系
book_obj.author.remove(*author_obj) 删除作者alex和Python书之间的关联
book_obj.author.clear() 删除Python和所有作者的关联
author_obj[0].book_set.clear() 删除作者alex和所有书的关联
注意:当clear()方法和remove()应用在ForeignKey上时,必需null=True才能用
三.修改
修改表数据
update()方法: Book.objects.filter(author="yuan").update(price=100) save()方法: b = Book.objects.get(author="oldboy") b.price = 200 b.save() 需要注意: 1.update()是QuerySet对象的方法,而save()是model对象的方法。即update可以一次性修改多条记录的数据,并返回一个整型数值,表示受影响的记录条数。而save一次只能修改一条记录 2.save() 方法会将所有属性重新设定一遍,效率低。而update只更改指定的属性,所以修改数据推荐用update
如果要修改多对多表之间的关系:
没有专门的方法,可以将remove()和add()组合使用
四.查询
1.查询API:
查询API:
filter(**kwargs) 它包含了与所给筛选条件相匹配的对象
all() 查询所有结果
get(**kwargs) 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。
下面的方法都是对查询的结果再进行处理:比如 objects.filter.values()
values(*field) 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列
values_list(*field) 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
exclude(**kwargs) 它包含了与所给筛选条件不匹配的对象
order_by(*field) 对查询结果排序,例如order_by("price")按照价格从小到大排序,order_by("-price")从大到小排序
reverse() 对查询结果反向排序
distinct() 从返回结果中剔除重复纪录
count() 返回数据库中匹配查询(QuerySet)的对象数量。
first() 返回第一条记录
last() 返回最后一条记录
exists() 如果QuerySet包含数据,就返回True,否则返回False。不会保存在缓存里。
扩展查询:有时候Django的查询API不能方便地设置查询条件,提供了另外的扩展查询方法extra()
extra(select=None, where=None, params=None, tables=None,order_by=None, select_params=None)
extra可以指定一个或多个参数,都不是必需的,但要至少使用一个。
参数详解:
1.select和select_params
select这个参数内可以直接写SQL查询语句或者函数,select_params用来给select中的语句传值
例:
v = models.Publish.objects.all().extra(select={
'n':"select count(1) from app01_book WHERE id=%s or id=%s",
'm':"select count(1) from app01_author WHERE id=%s or id=%s",
},select_params=(1,2,3,4))
这里取到了所有Publish表中的数据,同时还取到了以下两个SQL语句中的东西。
for i in v:
print(i.n,i.m,i.id)
2.where和params
where用来直接写查询条件,parems给where中传值
例:
models.Book.objects.extra(where=['parice=%s'], params=['99'])
models.Book.objects.extra(where=["'parice=100' OR name='Python'","id=1" ])
3.tables用来查询整张表
例:
models.Author.objects.extra(tables=["app01_book"])
<=> select * from app01_book,app01_author
models.Book.objects.extra(tables=["app01_author"],where=["app01_book.id = app01_author.id"]) <=> select * from app01_book,app01_author where app01_book.id = app01_author.id
4.order_by用来排序
综合示例1:
models.Author.objects.extra(
select={"newid":"select count(1) from app01_book where id>%s"},
select_params=[1,],
where=["args>%s"],
params=[18,],
order_by=["-ages"],
)
<=>
select
app01_author.id,
(select count(1) from app01_book where id>1) as newid
from app01_author,app01_book
where
app01_author.age > 18
order by
app01_author.age desc
综合示例2:
models.Article.objects.all().filter(user=current_user).extra(select={"filter_create_date":"strftime(‘%%Y/%%m‘,create_time)"}).values_list("filter_create_date")
#查出当前用户的所有文章的create_time,并且只取出年份和月份
单表模糊查询:(双下划线)
万能的 __双下划线
__gt 大于
__gte 大于等于
__lt 小于
__lte 小于等于
__icontains="p" 含有p且不区分大小写
__contains="p" 含有p且区分大小写
__exat="aaa" 相当于 like "aaa"
__iexat="aaa" 相当于忽略大小写 like "aaa"
_in=[10,20,33,50] 获取id等于10,20,33,50的数据
__exclude(id_in=[]) 不等于10 20 33 50的
__range=[1,2] 在范围内的
__startswith 以...开头
__istartswith 不以...开头
__endswith 以...结尾
__iendswith 不以...结尾
__year 日期字段的年份
__month 日期字段的月份
__day 日期字段的日
__isnull=True/False
filter(price__gt=100) 筛选价格大于100的
filter(id__gt=1,id__lt=10) id大于1小于10
2.多表关联查询:(多对多和一对多没有区别)
1.查多条记录(__ 双下划线)
找到Python这本书的出版社名称
Book.objects.filter(name="Python").values("publish__name") 通过外键[publish是Book表的外键]
Publish.objects.filter(book__name="Python").values("name") 通过对象[book是Publish关联的表名]
2.(只能查单条记录,不常用)
正向查询(通过书查出版社)
Book.objects.get(name="").publish --> 出版社对象
print(publish.属性)
反向查询(通过出版社找书)
Publish.objects.get(name="").book_set.all() -->所有的书籍对象
注意:book_set 是模型对象中反向查询的语法,book是表名,全部小写
调用 _set 的主体必须是单个对象!!
3.Queryset的惰性机制
所谓惰性机制,models查询语句只是返回了一个Queryset对象,并不会马上执行SQL,而是使用查询结果的时候才执行。
例如:person_set = Person.objects.filter(first_name="Dave")这句话并没有运行数据库查询,当遍历Queryset、if queryset或者在模板渲染的时候使用的时候才会执行数据库查询操作
Qureyset的特点:可迭代、可切片、有缓存。
※ Queryset是有缓存的
当遍历Queryset时,匹配的记录会从数据库获取,然后转换成Django的model。这些model会保存在Queryset内置的缓存中,如果再次遍历或者使用这个Queryset时,不需要重复的查询。
而如果处理成千上万的记录时,一次性装入内存是非常浪费的。要避免产生Queryset缓存,可以使用iterator()方法来获取数据,处理完数据就将其丢弃。
objs = Book.objects.all().iterator()
for obj in objs:
print(obj.name)
迭代器不能重复遍历,意味着可能会造成额外的重复查询。而缓存是用于减少对数据库的查询。所以使用时要考虑需求。
4.聚合查询的分组查询
from django.db.models import Avg,Min,Sum,Max,Count
聚合查询:aggregate(*args,**kwargs):
aggregate()是Queryset的一个终止子句,通过对Queryset进行计算,返回一个聚合值的字典。从整个查询集上生成聚合值。
aggregate()子句的参数描述了我们想要计算的聚合值,如平均Avg,求和Sum等
例如:
Book.objects.all().aggregate(Avg('price')) # 计算所有在售书的平均价钱
{'price__avg': 34.35}
Book.objects.aggregate(average_price=Avg('price')) # 自定义标识符(键)
{'average_price': 34.35}
Book.objects.aggregate(Avg('price'), Max('price'), Min('price')) # 同时输出多个聚合值
{'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')}
分组查询: annotate(*args,**kwargs):
分组查询常常和聚合查询一起。它可以为查询集的每一项生成聚合。
# 查询每个作者出书的总价格,按照作者分组
Book.objects.all().values("authors__name").annotate(Sum("price"))
[{'authors__name':'alex','price_sum':'140'},{'authors__name':'alvin','price_sum':'160'}]
# 查询各个出版社最便宜的书的价格
Book.objects.all().values("pulisher__name").annotate(Min("price"))
[{'publisher__name':'清华大学出版社','price_min':'70'},{'publisher__name':'中国机械出版社','price_min':'90'}]
5.F查询和Q查询
from django.db.models import F,Q
F查询:就是用来更新获取原来值的功能
models.Author.objects.all().update(age=F("age")+1) # 将Author表里所有人的年龄+1
models.Book.objects.all().update(price=F("price")+10) # 将所有书的价格涨10元
Q查询:用于构造复杂的查询条件,如 与、或、非。
查询条件我们可以使用filter()方法,在filter()里面的两个条件之间是and的关系,如果是或的关系,则只能使用Q查询
Book.objects.filter(Q(id=1)) # 查询条件为id=1 Book.objects.filter(Q(price=99) | ~Q(name="Python")) # 查询价格=99 或 名称不等于Python的书 Book.objects.filter(Q(name="Go"),price=99) # Q查询可以和关键字查询组合使用,但必须要将Q放到前面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号