
Spring Data JPA 介绍
Spring-data-jpa的基本介绍:JPA诞生的缘由是为了整合第三方ORM框架,建立一种标准的方式,百度百科说是JDK为了实现ORM的天下归一,目前也是在按照这个方向发展,但是还没能完全实现。在ORM框架中,Hibernate是一支很大的部队,使用很广泛,也很方便,能力也很强,同时Hibernate也是和JPA整合的比较良好,我们可以认为JPA是标准,事实上也是,JPA几乎都是接口,实现都是Hibernate在做,宏观上面看,在JPA的统一之下Hibernate很良好的运行。
那么Spring-data-jpa又是个什么东西呢?这地方需要稍微解释一下,我们做Java开发的都知道Spring的强大,到目前为止,企业级应用Spring几乎是无所不能,无所不在,已经是事实上的标准了,企业级应用不使用Spring的几乎没有,这样说没错吧。而Spring整合第三方框架的能力又很强,他要做的不仅仅是个最早的IOC容器这么简单一回事,现在Spring涉及的方面太广,主要是体现在和第三方工具的整合上。而在与第三方整合这方面,Spring做了持久化这一块的工作,我个人的感觉是Spring希望把持久化这块内容也拿下。于是就有了Spring-data-**这一系列包。包括,Spring-data-jpa,Spring-data-template,Spring-data-mongodb,Spring-data-redis,还有个民间产品,mybatis-spring,和前面类似,这是和mybatis整合的第三方包,这些都是干的持久化工具干的事儿。
在使用持久化工具的时候,一般都有一个对象来操作数据库,在原生的Hibernate中叫做Session,在JPA中叫做EntityManager,在MyBatis中叫做SqlSession,通过这个对象来操作数据库。我们一般按照三层结构来看的话,Service层做业务逻辑处理,Dao层和数据库打交道,在Dao中,就存在着上面的对象。那么ORM框架本身提供的功能有什么呢?答案是基本的CRUD,所有的基础CRUD框架都提供,我们使用起来感觉很方便,很给力,业务逻辑层面的处理ORM是没有提供的,如果使用原生的框架,业务逻辑代码我们一般会自定义,会自己去写SQL语句,然后执行。在这个时候,Spring-data-jpa的威力就体现出来了,ORM提供的能力他都提供,ORM框架没有提供的业务逻辑功能Spring-data-jpa也提供,全方位的解决用户的需求。使用Spring-data-jpa进行开发的过程中,常用的功能,我们几乎不需要写一条sql语句,至少在我看来,企业级应用基本上可以不用写任何一条sql,当然spring-data-jpa也提供自己写sql的方式
Spring Data是SpringSource基金会下的一个用于简化数据库访问,并支持云服务的开源框架。其主要目标是使得数据库的访问变得方便快捷,并支持map-reduce框架和云计算数据服务。对于拥有海量数据的项目,可以用Spring Data来简化项目的开发。
然而针对不同的数据储存访问使用相对的类库来操作访问。Spring Data中已经为我们提供了很多业务中常用的一些接口和实现类来帮我们快速构建项目,比如分页、排序、DAO一些常用的操作。
核心模块
为什么说Spring Data能帮助我们快速构建项目呢,因为Spring Data已经在数据库访问层上帮我们实现了公用功能了,而我们只需写一个接口去继承Spring Data提供给我们接口,便可实现对数据库的访问及操作。
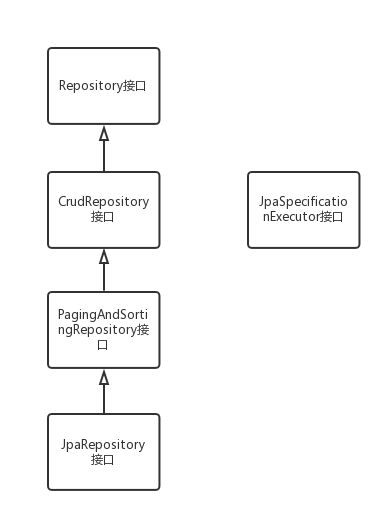
1 核心接口Repository:
public interface Repository<T, ID extends Serializable> { }
这个接口只是一个空的接口,目的是为了统一所有Repository的类型,其接口类型使用了泛型,泛型参数中T代表实体类型,ID则是实体中id的类型。
2 直接子接口CrudRepository:提供增删改查方法
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> { <S extends T> S save(S entity); <S extends T> Iterable<S> save(Iterable<S> entities); T findOne(ID id); boolean exists(ID id); Iterable<T> findAll(); Iterable<T> findAll(Iterable<ID> ids); long count(); void delete(ID id); void delete(T entity); void delete(Iterable<? extends T> entities); void deleteAll(); }
3 分页排序接口PagingAndSortingRepository: 排序和分页方法
public interface PagingAndSortingRepository<T, ID extends Serializable> extends CrudRepository<T, ID> { Iterable<T> findAll(Sort sort); Page<T> findAll(Pageable pageable); }
4 JpaRepository接口:
public interface JpaRepository<T, ID extends Serializable> extends PagingAndSortingRepository<T, ID> { List<T> findAll(); List<T> findAll(Sort sort); <S extends T> List<S> save(Iterable<S> entities); void flush(); T saveAndFlush(T entity); void deleteInBatch(Iterable<T> entities); void deleteAllInBatch(); }
5 复杂的接口JpaSpecificationExecutor:并没有继承上面的接口,是单独一个接口
public interface JpaSpecificationExecutor<T> { T findOne(Specification<T> spec); List<T> findAll(Specification<T> spec); Page<T> findAll(Specification<T> spec, Pageable pageable); List<T> findAll(Specification<T> spec, Sort sort); long count(Specification<T> spec); }
Spring Data JPA为什么只需定义接口就可以使用,其实这也不难发现,查看源码,可以找到针对JpaRepository和JpaSpecificationExecutor有一个实现类,SimpleJpaRepository.class,这个类实现了刚才所提的两个接口。而Spring在给我们注入实现类的时候,就正是这个SimpleJpaRepository.class
参考网址:
http://www.cnblogs.com/simazilin/p/5645947.html
http://www.cnblogs.com/simazilin/p/5645943.html
https://www.cnblogs.com/cmfwm/p/8109433.html

