
布隆过滤器
布隆过滤器用于字符串去重复,比如网络爬虫抓取时URL去重、邮件提供商反垃圾黑名单Email地址去重。等等。用哈希表也可以用于元素去重,但是占用空间比较大,而且空间使用率只有50%。
布隆过滤器只占哈希表的1/8或1/4的空间复杂度,就能解决同样的问题,但是有一定的误判,而且不能删除已有元素。元素越多,误报率越大,但是不会漏报。对于还需要删除的布隆过滤器,还有Counter Bloom Filter,这个是布隆过滤器的变体,可以删除元素。
布隆过滤器的原理
布隆过滤器需要的是一个位数组(和位图类似)和K个映射函数(和Hash表类似),在初始状态时,对于长度为m的位数组array,它的所有位被置0。

对于有n个元素的集合S={S1,S2...Sn},通过k个映射函数{f1,f2,......fk},将集合S中的每个元素Sj(1<=j<=n)映射为K个值{g1,g2...gk},然后再将位数组array中相对应的array[g1],array[g2]......array[gk]置为1:

如果要查找某个元素item是否在S中,则通过映射函数{f1,f2,...fk}得到k个值{g1,g2...gk},然后再判断array[g1],array[g2]...array[gk]是否都为1,若全为1,则item在S中,否则item不在S中。这个就是布隆过滤器的实现原理。
前面说到过,布隆过滤器会造成一定的误判,因为集合中的若干个元素通过映射之后得到的数值恰巧包括g1,g2,...gk,在这种情况下可能会造成误判,但是概率很小。
总结一下,感觉布隆过滤器的实现原理并不是太复杂,但是映射函数这个东西说的还是比较虚无。对于布隆过滤器的数学证明,数学公式之类的,我还是觉得我研究不了那么深入了。毕竟现阶段水平还不到有时间去研究这么底层的,甚至于底层到和数学打交道的东西,就现阶段来说,只要知道有这样一个东西可用,会用,我就很满足了。
本来此处留空是准备自己写个简易版的布隆过滤器的,但是实在不懂,看来数据结构还远远有待补充。
原理
Hash (哈希,或者散列)函数在计算机领域,尤其是数据快速查找领域,加密领域用的极广。
其作用是将一个大的数据集映射到一个小的数据集上面(这些小的数据集叫做哈希值,或者散列值)。
一个应用是Hash table(散列表,也叫哈希表),是根据哈希值 (Key value) 而直接进行访问的数据结构。也就是说,它通过把哈希值映射到表中一个位置来访问记录,以加快查找的速度。下面是一个典型的 hash 函数 / 表示意图:
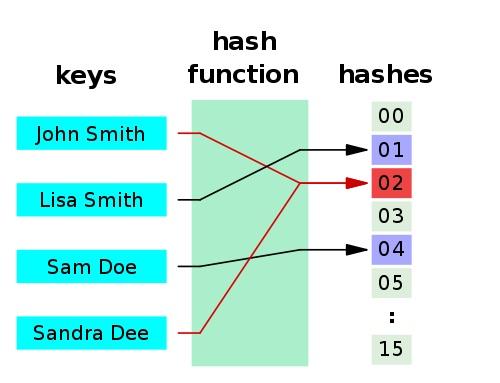
哈希函数有以下两个特点:
- 如果两个散列值是不相同的(根据同一函数),那么这两个散列值的原始输入也是不相同的。
- 散列函数的输入和输出不是唯一对应关系的,如果两个散列值相同,两个输入值很可能是相同的。但也可能不同,这种情况称为 “散列碰撞”(或者 “散列冲突”)。
缺点: 引用吴军博士的《数学之美》中所言,哈希表的空间效率还是不够高。如果用哈希表存储一亿个垃圾邮件地址,每个email地址 对应 8bytes, 而哈希表的存储效率一般只有50%,因此一个email地址需要占用16bytes. 因此一亿个email地址占用1.6GB,如果存储几十亿个email address则需要上百GB的内存。除非是超级计算机,一般的服务器是无法存储的。
所以要引入下面的 Bloom Filter。
布隆过滤器 Bloom Filter
原理
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢。
Bloom Filter 是一种空间效率很高的随机数据结构,Bloom filter 可以看做是对 bit-map 的扩展, 它的原理是:
当一个元素被加入集合时,通过 K 个 Hash 函数将这个元素映射成一个位阵列(Bit array)中的 K 个点,把它们置为1。检索时,我们只要看看这些点是不是都是 1 就(大约)知道集合中有没有它了:
- 如果这些点有任何一个 0,则被检索元素一定不在;
- 如果都是 1,则被检索元素很可能在。
优点
It tells us that the element either definitely is not in the set or may be in the set.
它的优点是空间效率和查询时间都远远超过一般的算法,布隆过滤器存储空间和插入 / 查询时间都是常数O(k)。另外, 散列函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
(误判补救方法是:再建立一个小的白名单,存储那些可能被误判的信息。)
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位数组变成整数数组,每插入一个元素相应的计数器加 1, 这样删除元素时将计数器减掉就可以了。然而要保证安全地删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
Example
可以快速且空间效率高的判断一个元素是否属于一个集合;用来实现数据字典,或者集合求交集。
如: Google chrome 浏览器使用bloom filter识别恶意链接(能够用较少的存储空间表示较大的数据集合,简单的想就是把每一个URL都可以映射成为一个bit)
得多,并且误判率在万分之一以下。
又如: 检测垃圾邮件
假定我们存储一亿个电子邮件地址,我们先建立一个十六亿二进制(比特),即两亿字节的向量,然后将这十六亿个二进制全部设置为零。对于每一个电子邮件地址 X,我们用八个不同的随机数产生器(F1,F2, ...,F8) 产生八个信息指纹(f1, f2, ..., f8)。再用一个随机数产生器 G 把这八个信息指纹映射到 1 到十六亿中的八个自然数 g1, g2, ...,g8。现在我们把这八个位置的二进制全部设置为一。当我们对这一亿个 email 地址都进行这样的处理后。一个针对这些 email 地址的布隆过滤器就建成了。
A,B 两个文件,各存放 50 亿条 URL,每条 URL 占用 64 字节,内存限制是 4G,让你找出 A,B 文件共同的 URL。如果是三个乃至 n 个文件呢?
分析 :如果允许有一定的错误率,可以使用 Bloom filter,4G 内存大概可以表示 340 亿 bit。将其中一个文件中的 url 使用 Bloom filter 映射为这 340 亿 bit,然后挨个读取另外一个文件的 url,检查是否与 Bloom filter,如果是,那么该 url 应该是共同的 url(注意会有一定的错误率)。”
java中的参数传递——值传递、引用传递
参数是按值而不是按引用传递的说明 Java 应用程序有且仅有的一种参数传递机制,即按值传递。
在 Java 应用程序中永远不会传递对象,而只传递对象引用。因此是按引用传递对象。Java 应用程序按引用传递对象这一事实并不意味着 Java 应用程序按引用传递参数。参数可以是对象引用,而 Java 应用程序是按值传递对象引用的。
Java 应用程序中的变量可以为以下两种类型之一:引用类型或基本类型。当作为参数传递给一个方法时,处理这两种类型的方式是相同的。两种类型都是按值传递的;没有一种按引用传递。
按值传递和按引用传递。按值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本。因此,如果函数修改了该参数,仅改变副本,而原始值保持不变。按引用传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本。因此,如果函数修改了该参数,调用代码中的原始值也随之改变。
1、对象是按引用传递的
2、Java 应用程序有且仅有的一种参数传递机制,即按值传递
3、按值传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的一个副本
4、按引用传递意味着当将一个参数传递给一个函数时,函数接收的是原始值的内存地址,而不是值的副本

 浙公网安备 33010602011771号
浙公网安备 33010602011771号