
Hadoop分布式集群配置
硬件环境:
安装一个Hadoop集群时,需要专门指定一个服务器作为主节点。
三台虚拟机搭建的集群:(搭建集群时主机名不能一样,主机名在/etc/hostname修改)
master机器:集群的主节点,驻留NameNode和JobTracker守护进程)
dbrg1 192.168.0.102
slaves机器:(集群的从节点,驻留DataNode和TaskTracker守护进程)
dbrg2 192.168.0.112
dbrg3 192.168.0.113
这三台机器都安装好了hadoop-0.20.2,JDK和ssh。
安装方法参考上一篇博文。
共有3台机器,均使用的linux系统,Java使用的是sun
jdk1.7.0。
1. 修改主机名和IP地址
vi /etc/hostname(分别给每一台主机指定主机名)
vi /etc/hosts(分别给每一台主机指定主机名到IP地址的映射)
这里有一点需要强调的就是,务必要确保每台机器的主机名和IP地址之间能正确解析。一个很简单的测试办法就是ping一下主机名,比如在dbrg1上pingdbrg2,如果能ping通就OK!若不能正确解析,可以修改/etc/hosts文件,如果该台机器作Namenode用,则需要在hosts文件中加上集群中所有机器的IP地址及其对应的主机名;如果该台机器作Datanode用,则只需要在hosts文件中加上本机IP地址和Namenode机器的IP地址。
1. 三台机器都要修改/etc/hosts。
在dbrg1中添加:
192.168.0.102 dbrg1 dbrg1
192.168.0.112 dbrg2 dbrg2
192.168.0.113 dbrg3 dbrg3
在dbrg2中添加:
192.168.0.102 dbrg1 dbrg1
192.168.0.112 dbrg2 dbrg2
在dbrg3中添加:
192.168.0.102 dbrg1 dbrg1
192.168.0.113 dbrg3 dbrg3
2.免密码SSH设置
(1) 在三台机器上安装ssh,启动ssh-server。
sudo apt-get install openssh-server
sudo /etc/init.d/ssh start
ps -e|grep ssh //这个是检验命令
(2)在dbrg1上生成密钥对。
ssh-keygen -t -rsa //然后一直enter,按照默认的选项生成的密钥对保存在.ssh/id_rsa文件中
进入.ssh目录,输入
cp id_rsa.pub authorized_keys
执行 ssh localhost 看看需不需要输入命令
(3)远程拷贝
生成好后,需要将该文件传到dbrg2和3上
在dbrg1中的.ssh目录中,输入
scp authorized_keys dbrg2:/home/dbrg/.ssh/
scp authorized_keys dbrg3:/home/dbrg/.ssh/
说明:如果提示在dbrg2和3上没有此目录,记得创建。此处是需要输入密码的。
(4)修改权限。在dbrg2和dbrg3上对该文件进行权限修改
打开.ssh,输入
chmod 644 authorized_keys
(5)配置修改
在三台服务器上对sshd服务进行配置,都需要修改。在sudo vi /etc/ssh/sshd_config中
修改:PasswordAuthentictation no
AuthorizedKeyFile /home/dbrg/.ssh/authorized_keys
(6)检验
在dbrg1上,ssh dbrg2,输入yes,这样以后访问都不需要输入密码了
同样ssh dbrg3,输入yes。
之后再检验下,看看需不需要输入密码
3.Hadoop环境配置
在dbrg1中,打开hadoop目录,ls下,发现了conf文件夹,这个里面全是配置,打开
(1)修改hadoop_env.sh,输入:
export HADOOP_HOME=/home/dbrg/HadoopInstall/hadoop
export JAVA_HOME=/usr/java/jdk1.7.0
说明:根据实际的安装路径来,这是我机子上的
(2) 修改masters
删除localhost,改为dbrg1
(3)修改slaves
删除,改为dbrg2、dbrg3
(4)修改core-site.html //N啊么node IP地址及端口
在configuration之间加入:
<property>
<name>fs.default.name</name>
<value>hdfs://dbrg1:9000</value>
<description>The name and URI of the default FS.</description>
</property>
(5)修改mapred-site.html //Jobtracker 调度并记录任务的执行情况
在configuration之间加入:
<property>
<name>mapred.job.tracker</name>
<value>dbrg1:9001</value>
<description>Map Reduce jobtracker</description>
</property>
(6)修改hdfs-site.html //block的文件副本数
在configuration之间加入:
<property>
<name>dfs.replication</name>
<value>2</value>
<description>Default block replication</description>
</property>
(7)环境配置的拷贝
利用scp命令将上面修改的文件,替代dbrg2和dbrg3中的相应文件
4.HDFS的运行
在dbrg1中初始化namenode,在hadoop目录下,输入
bin/hadoop namenode -format
然后再三台机器上都要bin/start-all.sh下,启动了
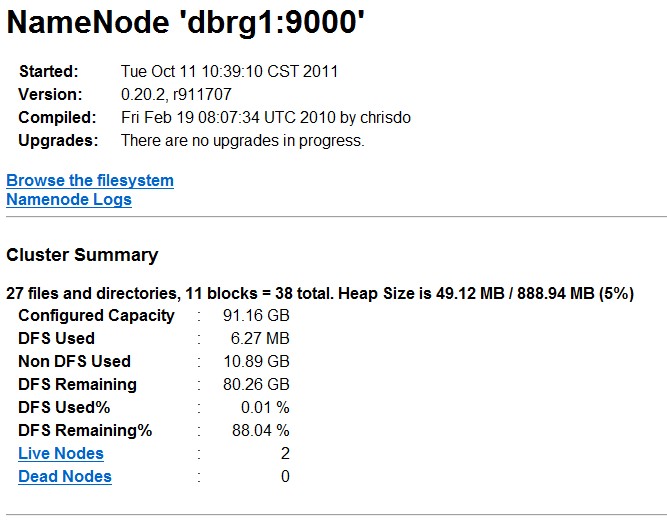
在dbrg1上可以查看,输入jps;或者可以通过http://dbrg1:50070查看

4. mapduce程序实例
参考网址:
http://blog.csdn.net/moodytong/article/details/6862020
http://www.cnblogs.com/welbeckxu/archive/2011/12/30/2306887.html
http://puxuanling.blog.163.com/blog/static/87476635201210704825265/
http://wenku.baidu.com/view/91e0240b52ea551811a68706.html
问题解决篇:
http://lwjlaser.iteye.com/blog/1443147

 浙公网安备 33010602011771号
浙公网安备 33010602011771号