
基于计算机视觉的车牌识别系统(一)
一, 车牌识别重要算法汇总
1.1 图像预处理
1.1.1 常规机动车车牌规格
如表1.1所示,是本次设计主要处理的三种车牌形式。
表1.1 常规机动车车牌规格
|
1.新能源汽车专号牌:绿底黑字黑框线,新能源汽车号牌为渐变绿色。 |
 |
|
2.大型汽车号牌:黄底黑字黑框线。载货汽车和专业作业车;半挂车;电车。 |
 |
|
3.小型汽车号牌:蓝底白字白框线。 |
 |
1.1.2 彩色图像的灰度图变换
将彩 色 图 像 进 行 灰 度 转 换 是 为 了 提 高 系 统总体算 法 的 处 理 速 度 和实现系统的稳定性考虑,并且在程序处理比较中,在灰度图像中处理比彩色图像中处理的计算量会减少很多,反映整体图像的局部和整体的色度,亮度的特征分布来看,灰度图和彩色图并没有什么区别[4]。
灰度转换是将含有R、B、G 三个通道组成的彩色照片进行转变为单通道的灰色图片。在此之前需要了解一下彩图是如何构成的,一张彩照主要R.G.B分为三个分量,而且每个分量组成是由255个中值构成,所以每一个彩色像素点是由三个分量合成的。其实灰度图就是RGB组成的彩色照片模型中的一种特殊照片,这种照片主要的优点就是在存储时用一个字节就够了,所以在处理时不会因为数据量太大,光线的强弱的变化受到影响。所以灰度化处理在图像处理中是十分关键步骤,也是为后续处理奠定基础。
1.1.3 图像的灰度修正
要了解灰度修正原理就要了解将彩照进行灰图转化的方法,这里面方法分为3种:
方法1:对每个像素点进行单独处理,将每个像素点的RGB的分量的权值和不同的权值进行加权处理,然后在将处理过的新像素点进行求平均值,这种方法十 分适合灰色图的处理环境[5]。
方法2:对每个像素点的分量的权值进行对比。并将最大值作为该像素点的灰度值。这种方法操作十分简单,但是处理过的照片十分容易失真[5]。
方法3:对每一像素点的分量中的权值进行平均值处理,这种方法可以将图片中的各个像素点变得平滑,便于后期的字符处理[5]。
根据我们对车牌识别系统的需要我们在这里对处理主要颜色特点进行简要的分析:
(1)当车牌是蓝色牌时在RGB分量分布中B的分量占大多部分,而且 B分量远大于另外两种分量的占比,另外两种分量占比相差无几;
(2)当车牌是黄色牌时在RGB分量分布中R、G的分量占大多部分,而且 R分量和G的占比对等,B分量的占比则含量最低;
(3)当车牌是绿色牌时在RGB分量分布中G的分量占大多部分,而且G分量远大于另外两种分量的占比,另外两种分量占比也是相差无几;
(4)车牌中的白色信息在RGB分量的分布中,RGB分量的各个值都是255;
(5)车牌中的黑色信息在RGB分量的分布中,RGB分量的各个值都是0;
在本次设计中处理时则是用平均值的方法,这样可以使含有车牌部分的图像通过灰度处理变得简易,有利于减少处理时间。假设g为灰度值: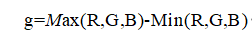
具体效果如图1.1所示:

图1.1 车牌灰度修正图
1.2 边缘检测
边缘检测就是把想要的部分进行提取边缘,可以使需要的部分边缘轮廓更加明显,如今对于这个技术的处理已经有很多成熟的算法,主要常用的算法有:Sobel、拉普拉斯,Canny等。在本次课题中用的是Canny来进行提取边缘,该算法是由约翰 F.Canny根据前人研究边缘检测算法的基础上进行改进,该算法是将边缘的提取结果进行封装成框[1],显示效果也更加明显,有利于车牌定位时的使用。
Canny算法详细原理计算环节如下[2]:
(1)高斯滤波器:用于平滑图像,滤除噪声。
下面用尺寸为3*3作为高斯卷积核进行举例,该举例的矩阵的求和结果必须为1(进行归一化)。
 式中
式中
H——归一化矩阵;
e——滤波的像素点,px;
A——图像中一个3x3的像素窗口,px;
sum——表示矩阵中所有元素相加求和。
其中*为卷积符号。处理之后的每个像素值等于其原像素点的中值和其相邻像素点进行加权求和。目前将图像进行卷积操作是十分重要且运用广泛的。对Canny影响最大的就是在选取高斯卷积核的时候,如果选择的像素尺寸过大,虽然去噪能力也会增强,但是照片整体来看会变得模糊。所以并不是尺寸选取越大、抗噪能力越强越好。所以为了能够在不影响定位精度的情况下,一般尺寸会选33或者55就可以了[6]。
(2)梯度强度和方向
通过灰度值的变化来作为边缘检测的标准,如果将边缘检测的灰度值作为一个二元函数。梯度就可以看做二元函数的导数,但是图像的数据是离散型的数据,所以图像的梯度就用差分值进行表示,在实际情况中就是两个像素的进行求差值。一个像素点的周围有8个相邻的像素点,分布在它的上下左右对角的四对算子,所以Canny需要用分布在四个位置的算子进行检测,主要通过图像的水平、垂直和对角的四对算子来计算梯度。这里选用sodel举例来计算水平方向和竖直方向的差分值,这里假设SX和Sy作为模板、A作为原图,最后SX和Sy分别与A进行卷积操作,最后通过x、y方向差分值的图进行计算该点的梯度G和方向 [7]。
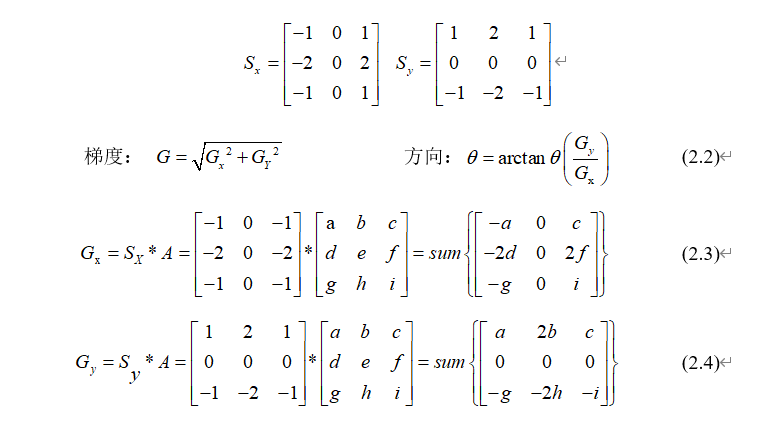

(3)非极大值抑制
非极大值抑制也是在边缘检测中的重要部分之一,其主要目的是沿着梯度和方向将前后梯度值进行逐一比较来进行查找目标像素区域中最大值。
假设图2.2中的相邻像素点分别为g1 、g2、 g3、g4,c为目标像素点,图2.2的左边部分中的c点是我们需要处理的像素点,c点梯度方向用蓝线表示。算出c点的梯度的幅值M,线段g1g2、线段g3g4与蓝色直线相交与交点dtmp1和交点dtmp2。这两个交点称之为c点的梯度幅值。由于交点dtmp1和交点dtmp2并不是完整的像素点,所以称之为亚像素点,其坐标则是浮点数表示的,这里要想算出交点的梯度幅值,就要利用线性插值法来[8]。首先对于g1、g2的幅值是已知的,也知道dtmp1在g1g2这条线段上,可以通过计算交点dtmp1与g1点和g2点的比值来得出dtmp1的梯度幅值,而对于dtmp1与g1点和g2点的比值可以用梯度的方向进行计算。故假设g1的幅值M(g1),g2的幅值M(g2),则dtmp1可以很容易得到。

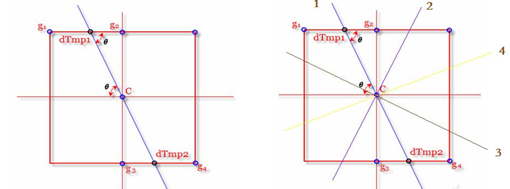
图1.2 线性插值图
(4)双阈值检测
双阈值检测的原理也是十分简单,主要就是范围的划分,图1.3中有两条直线,假设这两条直线就是两类边缘,当像素区域的梯度值高于maxVal,则说明此边缘为强边缘值。强的边缘可以很好地展示出更多的细节边缘,在图1.4右边部分可以看出,很多细节都能明显看见边缘部分。当像素区域的梯度值处于maxVal与minVal之间,则说明此边缘为弱边缘值,在图1.4中间部分可以看出,虽然可以看出基本轮廓,但是较多的细节却看不出来[9]。但也不是说弱的边缘没有利用价值,在复杂的环境下为了简化处理图像又不会影响输出结果时,是可以考虑使用的。双阈值检测最为主要的是确定阈值范围,通过阈值的范围的确定,可以提高容错率、增强算法的利用率,所以通过实际检测发现maxVal:minVal=2:1的比例效果比较好[6]。

图1.3 双阈值检测图

图1.4 边缘检测图
1.3 形态学处理
1.3.1 图像的腐蚀和膨胀
形态学处理是在原有的基础之上对研究物体的现状进行改变,这里我们利用的是 Opencv模块进行操作,首先介绍的是图像的腐蚀和膨胀,是通过opencv中的erode函数和dilate函数来实现的,目的就是将通过二值化过得图片的白色部分进行放大和缩小的处理。接下来详细介绍腐蚀和膨胀。
腐蚀是将白色部分进行收缩得过程。图1.5就是腐蚀的原理图,原理就是利用3*3的像素核B,与进行过二值化处理的图片A中的每一个像素区域所取最小值的像素块进行“与”操作,当结果为1时,则图中该像素区视为1的,不然则认为该像素区的检验结果视为0,当结果为0时,就会使二值化的图像中的为0的像素区进行一个收缩的操作。
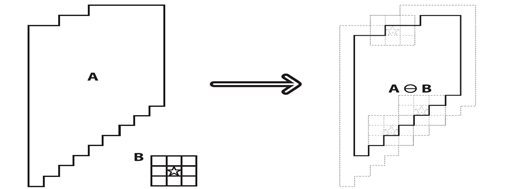
图1.5 图像腐蚀算法图
膨胀是与腐蚀的原理相反。图1.6就是膨胀的原理图,原理就是利用3*3的像素核B,与进行过二值化处理的图片A中的每一个像素区域所取最小值的像素块进行“与”操作,当结果为0时,则图中该像素区视为0的,不然则认为该像素区的检验结果视为1,当结果为1时,就会使二值化的图像中的为1的像素区进行一个扩大的操作。

图1.6 图像膨胀算法图
腐蚀和膨胀的主要程序操作如下:
import cv2 # opencv读取的格式是RGB
import numpy as np
img = cv2.imread('car01.jpg')
ker = np.ones((3,3), numpy.uint8)
ero= cv2.erode(img,ker,iterations = 1)
dil = cv2.dilate(img,ker,iterations = 1)
res = np.hstack((img,erosion,dilate))
cv_show('dige and erode and dilate',res)
cv2.imwrite('car_canny03.jpg',res)
erosion = cv2.erode()和dilate = cv2.dilate()迭代次数越多和 kernel越大效果越明显,具体效果如图1.7和图1.8所示。

图1.7 图像腐蚀后图

图1.8 图像膨胀后图
1.3.2 图像的开运算与闭运算
开运算与闭运算的原理就是先后执行腐蚀和膨胀的处理。如图1.10中的左半部分所示,开运算主要功能就是剔除掉背景噪声、对形状的边缘部分进行平滑处理、切断物体与物体之间的细小噪声[10]。如图1.10中的右半部分所示,闭运算的主要功能剔除图像中的小孔和小黑点。填充由噪声产生的小空洞、而且会与旁边的物体形状进行连接、修复断开的轮廓线,在不改变面积的前提下使物体形状的边缘部分变得平滑。不管是开运算还是闭运算选择卷积核大小都是十分重要的,太小了无法有效的剔除黑点。对于卷积核的形状也会有影响的。而且当选取为圆的卷积核时,对于物体形状的边缘不仅有平滑的作用,而且还可以去除有噪声产生的突刺[11]。这样可以将我们识别出来车牌的字符部分变得更加的明显和突出。用图2.9对比观察利用开运算和闭运算变换前后图像的变化[7]。

图1.9 黑白多态原图
开运算和闭运算的区别程序如下:
def morphologyExTest(imgObj,imgTitle=''):
if isinstance(imgObj, str):
img = cv2.imread(imgObj)
if img is None:
img = cv2.imdecode(np.fromfile(imgObj, dtype=np.uint8), -1)
imgTitle = imgTitle+imgObj+': '
else:
imgTitle = imgTitle + ': '
kernal = cv2.getStructuringElement(cv2.MORPH_RECT ,(3,3))
imgOpen = preparePreviewImg(imgTitle+'开运算,矩形核大小3*3',cv2.morphologyEx(img, cv2.MORPH_OPEN,kernal))
imgClose = preparePreviewImg(imgTitle+'闭运算,矩形核大小3*3',cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernal))
kernal = cv2.getStructuringElement(cv2.MORPH_RECT, (5, 5))
imgOpen = preparePreviewImg(imgTitle + '开运算,矩形核大小5*5', cv2.morphologyEx(img, cv2.MORPH_OPEN, kernal))
imgClose = preparePreviewImg(imgTitle + '闭运算,矩形核大小5*5', cv2.morphologyEx(img, cv2.MORPH_CLOSE, kernal))
preparePreviewImg()
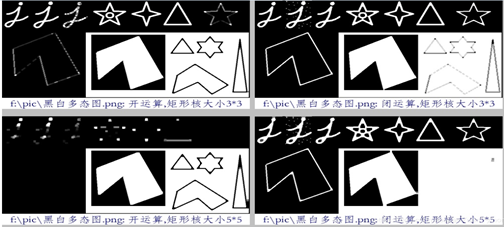
图1.10 开运算和闭运算效果图
运行结果从图1.10可以看出,核越大,开运算被侵蚀的前景色越多,闭运算则背景色被填充越多。但是不难看出3*3开运算和闭运算都能更加看清楚边界细节,有利于我们处理字符的边界时,可以更加的清晰看出字体的轮廓[12]。
2.4 卷积神经网络
这里之说CNN(Convolutional Neural Networks,)如何进行识别,根据图1.11可知,起初浅显确定一个“X”图样,计算机认识这个“X”方法是计算机内部存储一张规范的“X”图片样板,在将需要辨认的不明图样和规范"X"图样作比较,假如两者相同,就认为不明图样是一个"X"图样。况且即使不明图样大概有一点平移或轻微变形,仍然可以判断出它是一个X图样。这样,CNN是把不明图样和规范X图样一个部分一个部分的作比较[13]。
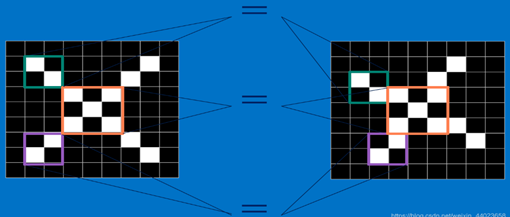
图1.11 CNN识别原理图
卷积操作如图1.12所示,不明图样的部分和规范X图样的部分一个一个区分时的计算流程,。计算结果是1的卷积计算示意匹配,否则示意不匹配[14]。整体来讲,为了判断一幅图样是含有"X"还是"O",等同于我们须要断定它有无"X"或许"O",并且如果必须二选一,要么是"X"要么是"O"[8]。
图1.12 CNN识别原理分析图
图1.13 CNN识别理想结果图
最理想的结果是:如图1.13所示,规范的"X"和"O",在图像的正中间显示,而且比例适当,没有变形,但是就计算机而言,图像哪怕只有轻微的有变化,就不规范。因此采用CNN来解决是种好方法。CNN的具体方法就是一块一块地来对比。用来对比的“小块”叫Features(特征图块)。在两幅图中大概一样的地方取一点粗糙的特征对比,CNN可以更明显比较出两幅图的类似性[11]。
图1.14上方的小图就是特征图块,特征图块就像是一个带有识别功能小图(这里理解是一个比较小的有值的二维数组)。不同的特征图块分别匹配图像中不同的特征。就像识别"X"的举例中一样,通过对角线和交叉线组成的特征图块几乎能够识别出大多数任何"X"图样[12],进而到达识别的目的。
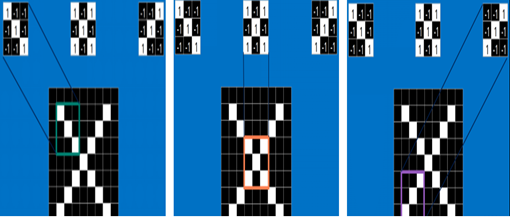
图1.14 CNN提取特征图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号