正则表达式
(这篇博客是个人见解,不是很专业,想寻求更专业的解答,就需要去找更专业的答案,例子使用的是python的re模块,所有很多主要是针对python写的。不过关于正则的部分还是有一定的借鉴意义。)


匹配中文字符:/[\u4e00-\u9fa5]/gm 只能输入数字:/^\d+$/ 只能输入n个数字:/^\d{n}$/ 至少输入n个以上的数字:/^\d{n,}$/ 只能由英文字母组成:/^[a-z]+$/i 只能由大写英文字母组成:/^[A-Z]+$/ 只能由英文和数字组成:/^[a-z0-9]+$/i 只能由英文、数字、下划线组成:/^\w+$/ 匹配Email地址:/\w+([-+.]\w+)*@\w+([-.]\w+)*\.\w+([-.]\w+)*/ 匹配url地址:/^https?:\/\/(([a-zA-Z0-9_-])+(\.)?)*(:\d+)?(\/((\.)?(\?)?=?&?[a-zA-Z0-9_-](\?)?)*)*$/i 匹配手机号:/^(0|86|17951)?(13[0-9]|15[012356789]|166|17[3678]|18[0-9]|14[57])[0-9]{8}$/ 匹配身份证号:/^(^[1-9]\d{7}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])\d{3}$)|(^[1-9]\d{5}[1-9]\d{3}((0\d)|(1[0-2]))(([0|1|2]\d)|3[0-1])((\d{4})|\d{3}[Xx])$)$/ 匹配邮编号:/^[1-9]\d{5}(?!\d)$/ 匹配日期(yyyy-MM-dd):/^[1-2][0-9][0-9][0-9]-[0-1]{0,1}[0-9]-[0-3]{0,1}[0-9]$/
就字符匹配而言,无外乎两种情况:
- 普通字符,就是要啥查啥
-
>>> re.findall("lo", "Hello world") ['lo']
-
- 元字符,就是用一些特殊的字符来满足我们的查询,常见的元字符有:. ^ $ * + ? { } [ ] | ( ) \
-
>>> re.findall("l[od]", "Hello world") ['lo', 'ld']
-
元字符
- "."元字符:匹配匹配除换行符 \n 之外的任何单字符。
- "^"元字符:匹配输入字符串的开始位置,如果在方括号表达式中使用,此时它表示不接受该字符集合。
- "$"元字符:匹配输入字符串的结尾位置。
- "*"元字符:匹配前面的子表达式零次或多次。
- "+"元字符:匹配前面的子表达式一次或多次。
- "?"元字符:匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。
- "{}"元字符:限定符,用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。后面详细说明
- "[]"元字符:字符集合。匹配所包含的任意一个字符。后面详细说明
- "|"元字符:指明两项之间的一个选择。一般配合括号
-
>>> re.findall("ka|b", "aaaakaccb") ['ka', 'b']
-
- "()"元字符:分组,后面详细说明
- "\"元字符:转义,后面详细说明
下面会说些比较常用的正则知识,虽然后面会详细说明,但是这里还是先写一些,作为初步的了解。
- 匹配的贪婪
- *,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?号使其变成惰性匹配
-
*?:重复任意次,但尽可能减少的重复
+?:重复一次或者多次,但尽可能减少的重复
??:重复零次或者一次,但尽可能减少的重复
{m,n}?:重复m到n次,但尽可能减少的重复
{n,}?:重复n次以上,但尽可能减少的重复
{n}?:重复n次,但尽可能减少的重复
-
>>> re.findall("b+", "aabbbbccc") ['bbbb'] >>> re.findall("ab+?", "aabbbbccc") ['ab'] >>>
-
转义符"\"
-
反斜杠后面跟特殊字符去除特殊功能,比如"\."是匹配符号“.”
-
反斜杠后面跟普通字符实现特殊功能,比如"\d" 是匹配数字
-
常用的实现特殊功能的普通字符
"\w":匹配字母数字下划线,等同于:[a-zA-Z0-9_] ''\W':匹配除了字母、数字、下划线之外的所有字符,等同于:[^\w] “\d”:匹配任何一个十进制数,等同于[0-9] ”\D“:匹配不是数字的所有字符,等同于:[^\d] “\s”:匹配任意空白符,;它相当于类 [ \t\n\r\f\v]。 "\S":匹配除空白符之外的任意字符,等同于:[^\s] "\b":匹配一个特殊字符边界,比如空格 ,&,#等 "\B":匹配不是单词边界的字符,等同于:[^\b] "\xnn":匹配十六进制数 "\f":匹配换页符,等同于:\x0c "\n":匹配换行符,等同于:\x0a "\r":匹配回车符,等同于:\x0d "\t":匹配水平制表符,等同于:\x09 "\v":匹配垂直制表符,等同于:\x0b "unnnn":匹配Unicode字符,如:\u00A0
-
元字符之{}
限定符,用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。在前面的的+,*,?也是限定符,它们是使用方便,{}是更灵活。
- {m}:表示精确匹配前面的正则表达式的m个拷贝;较少的匹配将导致整个表达式不能匹配。例如,a{6}将精确匹配6个'a'字符,5个将不能匹配。
- {m,n}:引起生成的正则表达式匹配前导正则表达式的m到n个重复,尝试匹配尽可能多的重复。例如,a{3,5}将匹配3到5个'a'字符。省略m表示下界为0
- {m,}:表示上界无限大。举个例子,a{4,}b将匹配aaaab或一千个'a'字符后跟随一个b,但不能匹配aaab。逗号不可以省略,否则该修改符将与前面的形式混淆。
- {m,n}?:例如,对于6个字符的字符串'aaaaaa',a{3,5}将匹配5个'a'字符,而a{3,5}?将只匹配3个字符。
元字符之[]
字符集合。匹配所包含的任意一个字符。
在"[]"中有效的符号有:^,-,\
- ^:非,表示不在[]范围内任意的字符。
- -:范围,比如[0-9]的意思就是0到9中任意一个。
- \:转义字符
ret=re.findall('[1-9]','45dha3') print(ret)#['4', '5', '3'] ret=re.findall('[^ab]','45bdha3') print(ret)#['4', '5', 'd', 'h', '3'] ret=re.findall('[\d]','45bdha3') print(ret)#['4', '5', '3']
元字符之()
这个元字符的主要作用就是用来分组的
- (exp)
- 用小圆括号进行分组,如日期中年月日的分组:/(\d{4})-(\d{1,2})-(\d{1,2})/
- (?:exp)
- 匹配exp正则,但不产生分组号.分组会占用一定的系统资源,尤其是正则表达式较长的时候会降低匹配速度。有时候仅仅是为了设置一个分组,并不需要引用,用这个比较好
- exp1(?=exp2)
- 前瞻断言,匹配exp1,但后面必须是exp2
- exp1(?!=exp2)
- 后瞻断言,匹配exp1,但后面不能是exp2
- (?P<name>exp)
- 给分组命名
-
>>> re.search('(?P<id>\d{2})/(?P<name>\w{3})','23/com').group("name") 'com'
一些例子:
import re print(re.findall("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>")) # ['h1'] print(re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>","<h1>hello</h1>").group()) # <h1>hello</h1> print(re.search(r"<(\w+)>\w+</\1>","<h1>hello</h1>").group()) # <h1>hello</h1> print(re.findall("(abc)+","abcabcabc")) # ['abc'] print(re.findall("(?:abc)+","abcabcabc")) # ['abcabcabc']
元字符之\
这个元字符主要有两个功能:
-
反斜杠后面跟特殊字符去除特殊功能,比如"\."是匹配符号“.”
-
反斜杠后面跟普通字符实现特殊功能,比如"\d" 是匹配数字
"\w":匹配字母数字下划线,等同于:[a-zA-Z0-9_] ''\W':匹配除了字母、数字、下划线之外的所有字符,等同于:[^\w] “\d”:匹配任何一个十进制数,等同于[0-9] ”\D“:匹配不是数字的所有字符,等同于:[^\d] “\s”:匹配任意空白符,;它相当于类 [ \t\n\r\f\v]。 "\S":匹配除空白符之外的任意字符,等同于:[^\s] "\b":匹配一个特殊字符边界,比如空格 ,&,#等 "\B":匹配不是单词边界的字符,等同于:[^\b] "\xnn":匹配十六进制数 "\f":匹配换页符,等同于:\x0c "\n":匹配换行符,等同于:\x0a "\r":匹配回车符,等同于:\x0d "\t":匹配水平制表符,等同于:\x09 "\v":匹配垂直制表符,等同于:\x0b "unnnn":匹配Unicode字符,如:\u00A0
反斜杠的困惑
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
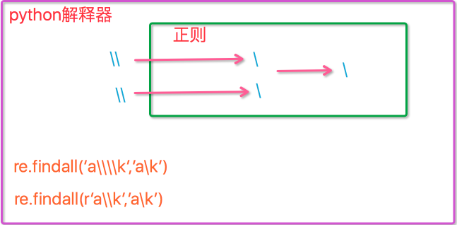
再举一个例子
import re # 普通元字符的转义 _string = ''' !@#$%^& ''' # 不转义 print(re.findall('$', _string)) # ['', ''] # 双反斜杠转义 print(re.findall('\\$', _string)) # ['$'] # 单反斜杠转义 print(re.findall('\$', _string)) # ['$']
看上面的例子大家可能会发现,使用一个反斜杠 \ 也可以达到转义的效果,那为什么还要写两个呢?这得先搞清楚python的字符串转义(不是正则表达式转义),这里只讲结果,具体原因看:https://www.cnblogs.com/kuxingseng95/p/9462294.html
接下来我们分析一下
一个字符串被正则表
达式引擎解析的过程,一共有4步:
- 首先正则表达式是一个python的字符串
- 字符串本身会先进行转义处理
- 正则表达式引擎得到处理之后的字符串后再对字符串进行正则表达式引擎自己的处理
- 开始匹配
# 字符串 # '\\\\' # 经过python处理之后 # '\\' # 正则表达式引擎接收到的 # '\\' # 正则表达式引擎进行转义处理后 可以匹配到 \ # '\'
而使用原生字符串的时候就变成了3步
# 原生 # '\\' # 不再处理 # '\\' # 正则表达式引擎接收到的 # '\\' # 正则表达式引擎进行转义处理 # '\'
接下来就是真正揭秘原因了
当使用一个 \ 转义的时候,python会识别不了转义序列,于是它就不做任何处理,直接传给了
正则表达式引擎。这就解释了为什么一个 \也可以转义。这个不算bug,虽然方便了使用,但会让人很迷惑,有利有弊吧。
# 原生 # '\$' # 识别不了 不进行处理 # '\$' # 正则表达式引擎接收到的 # '\$' # 正则表达式引擎进行转义处理 # '$'
下面举几个例子
import re # 匹配 \d+ _string = 'i am \d+' print(re.findall('\\\\d\\+', _string)[0]) # \d+ print(re.findall(r'\\d\+', _string)[0]) # \d+ # 匹配 [] _string = 'i am []' print(re.findall('\\[\\]', _string)[0]) # [] print(re.findall('\[\]', _string)[0]) # [] print(re.findall(r'\[\]', _string)[0]) # []
修饰符

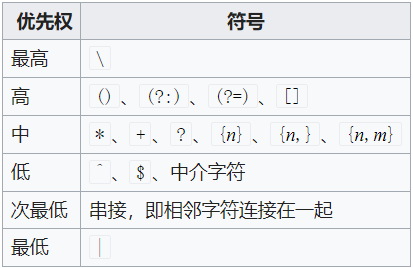
优先权