

Python——数据类型
如果是C语言,Java使用一个变量之前需要声明,数字,字符,布尔等都有特定的声明方式,前端中常用的js中都要使用var,而python中直接用就行了
比如:
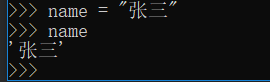
虽然是这样使用,但其实是当你给一个变量赋值,python会自动给这个变量定义类型。
变量类型分类:数值型,字符型,布尔型,列表,元组。
注:可以用type()来测试一个变量的类型
数值型
数值型又包含了整数和浮点数
整数
整数的类型用int来表示。python可以处理任意大小的整数,当然可以包括负整数。
比如:

字符串整数可以通过int()强转成整数类型。
比如:

也可以用int()将浮点数强转为整数,强转是不四舍五入的
比如:

如果要将字符型的浮点数强转成整数需要先用float()把这个字符串强转成浮点数,在用int()强转成整数
比如:

浮点数
浮点数也就是小数,类型用float来表示。
比如:

注:整数和浮点数在计算机内部的存储方式是不同的,整数的计算是永远精确的(包括除法),而浮点数运算则可能出现误差
比如:

可以看到浮动运算会有一定的误差,在使用的时候我们一般先将浮点数成10的N次方,将它变成整数,然后进行运算,再除以10的N次方,这样可以保证数据的准确性。
字符型
字符串常用单引号,双引号或者三引号括起来。类型用str来表示
比如:

如果字符串内有单引号或者双引号,可以用转义字符来标识,需要注意的是下面的例子中,最外层的引号不是变量中的内容,而只是一种表示的方式
比如:

补充一下常用的转义字符:\n表示换行,\t表示制表符,\\表示\
如果不想用转义字符,可以用r''这种方式来写,这样内部的内如就不需要转义了
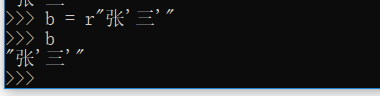
如果是要写多行的话可以用三引号,这样回车换行的话前面就变成三个点,最后用三引号结束就可以了
比如:
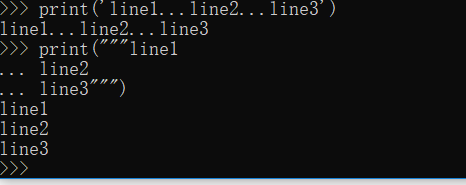
字符型还有一个特性,就是一旦创建就不可改变。
举个例子:当你创建了一个字符串变量a,然后给它赋值为ABC,python解释器就会创建一个a变量,然后再创建一个空间存储ABC,再让a变量指向这个空间的地址。当你改变一个字符串的时候,它就会再开辟一个空间来存储这些字符串内容,然后让a变量指向新的字符串空间地址
比如:
a = "地址一"
print(id(a)) # 2907158346448
a += "二"
print(a) # 地址一二
print(id(a)) # 2907157753504
注释内容是输出的结果
还有一点:字符串可以通过下标取值,但是不可以修改,否则会报错
字符的编码解码:
# ord() 获取字符的整数表示 # chr() 将编码转换成对应字符 print(ord("A")) # 65 print(chr(20013)) # 中
由于python的字符串类型是str,在内存中是用Unicode码表示的,一个字符对应若干个字节,如果要在网上传输或者保存到硬盘上,就需要将str变成以字节为单位的bytes,python对bytes类型的数据用带b的前缀的单引号,或者双引号表示。
可以通过:字符串.encode("编码格式")转换成对应的编码表示
可以通过:字符串.decode("编码格式")将编码转换为对应的字符串
比如:
a = "中文" print(a.encode("utf-8")) # b'\xe4\xb8\xad\xe6\x96\x87' b = b"ABC" print(b.decode("utf-8")) # ABC
# 在编码过程中,如果有无效字节,会报错,如果只有一部分的话,可以传入errors="ignore"忽略错误的字节
# 比如b'\xe4\xb8\xad\xe6\x96\x87'.decode("utf-8", errors="ignore")
字符串常用方法
下面例子中mystr,str假设是一个字符串
join
# mystr.join(str) mystr 中的字符迭代插入到str字符串中的每个元素后面,构造出一个新的字符串 a = "@" print(a.join("Hello")) # H@e@l@l@o
split
# mystr.split(str=" ", 2) 注:以 str 为分隔符切片 mystr,如果 maxsplit有指定值,则仅分隔 maxsplit 个子字符串,列表显示,有个弊端就是分割的那个字符不包括 a = "H@e@l@l@o" print(a.split("@", 2)) # ['H', 'e', 'l@l@o']
find
# mystr.find(str, start=0, end=len(mystr)) 没找到返回-1,只返回第一个匹配的字符下标 a = "Hello" print(a.find("l")) # 2
strip
# mystr.strip() 删除 mystr 两边的空白字符和\n换行符,括号里可以放入指定要删除的字符或者字符串,如果是字符串的话会将字符串中与参数中的字符串的最长的那个进行匹配然后删除 a = " Hello \n" print(a.strip()) # Hello print(len(a.strip())) # 5
replace
# mystr.replace(str1, str2, mystr.count(str1)) 把 mystr 中的 str1 替换成 str2,如果 count 指定,则替换不超过 count 次. a = "111211121112222" print(a.replace("2", "中", 2)) # 111中111中1112222
print(a) # 111211121112222
# 需要注意的是replace并不改变原来的字符。实际上replace这个函数只是创建了一个新的字符并返回。如果用变量接收的话,就容易理解了
其他字符串方法


mystr.isidentifier() # 查看是不是系统标识符 mystr.expandtabs(20) # 表示一个字符串中20个一组,遇到\t就将后面的放入下一组,这一组中不够20的位置补空格,用于格式话显示 mystr.rfind(str, start=0,end=len(mystr) ) # 从右开始find mystr.index(str, start=0, end=len(mystr)) # 跟find()方法一样,只不过如果str不在 mystr中会报一个异常. mystr.rindex( str, start=0,end=len(mystr)) # 从右开始index mystr.count(str, start=0, end=len(mystr)) # 返回 str在start和end之间,在 mystr里面出现的次数 mystr.capitalize() # 把字符串的第一个字符大写 a.title() # 把字符串的每个单词首字母大写 mystr.startswith("hello") # 检查字符串是否是以 hello 开头, 是则返回 True,否则返回 False mystr.endswith(obj) # 检查结尾的 mystr.lower() # 英文全部转小写 mystr.upper() # 英文全部转大写 mystr.ljust(width) # 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 mystr.rjust(width) # 同上,是右对齐 mystr.center(width) # 一个参数表示字符串总长度,内容放中间,其他空格补充,第二个参数放一个字符,表示用这个字符填充 mystr.lstrip() # 删除 mystr 左边的空白字符和\n换行符,括号里可以放入指定要删除的字符或者字符串,如果是字符串的话会将字符串中与参数中的字符串的最长的那个进行匹配然后删除 mystr.rstrip() # 同上,删除的是右边的 mystr.partition(str) # 从左边的第一个str,把mystr以str分割成三部分,str前,str和str后,返回的是一个元组 mystr.rpartition(str) # 同上,从右边 mystr.splitlines() # 按照行分隔,返回一个包含各行作为元素的列表 mystr.isalpha() # 如果 mystr 所有字符都是字母 则返回 True,否则返回 False mystr.isdigit() # 如果 mystr 只包含数字则返回 True 否则返回 False. mystr.isalnum() # 如果 mystr 所有字符都是字母或数字则返回 True,否则返回 False mystr.ispace() # 如果 mystr 中只包含空格,则返回 True,否则返回 False.
还有一个需要注意的就是:
在python3中,len()字符串,无论英文还是汉字,显示的是字符的个数
在python2中,len()字符串,显示的是字符串的所占·字节数,英文是一个字节,中文要根据你使用的字符编码来看所使用的字节数。
上面说的这个编码不懂的看我另一个随笔:python基本使用时常见的错误的字符编码
布尔型
布尔值的类型用bool来表示
比如:

布尔的值只有两个:Ture和False
注:
所以数据都自带布尔值
None,0,空(空字符串,空列表,空字典等)这三个情况下的布尔值都为False
其他为真。
列表
列表是一种用中括号([])包裹起来的有序集合,用list来表示,它可以存储任意的类型的数据,
列表在内存中的表现是链表形式存储,即每个元素存储的地方可以能连续,每个元素的后面都会存放一个内存地址来找到下一个元素的位置。
所以列表元素是可以被修改的,可以通过下标来获取元素,取最后一个可以用-1。越界会报错。
比如:

最后一种是字典,后面会介绍
列表方法
# append() 将参数作为元素添加到列表中去 a = [1, 2] a.append([3, 4]) print(a) # [1, 2, [3, 4]]
# extend() 将参数列表逐个添加到列表中去 a = [1, 2] a.extend([3, 4]) print(a) # [1, 2, 3, 4]
# insert(index, object) 在指定位置index前插入元素object a = [1, 2, 3, 4] a.insert(1, [3, 4]) print(a) # [1, [3, 4], 2, 3, 4]
# 修改元素有两个方法,一个是通过下标,一个是通过切片(切片是左闭右开区间) a = [1, 2, 3, 4] # 方式一:下标修改 a[1] = "中" print(a) # [1, '中', 3, 4] # 方式二:切片修改,也可以实现删除 a[2:3] = ["天", "下", "大", "同"] # [1, '中', '天', '下', '大', '同', 4] print(a) a[2:3] = [] print(a) # [1, '中', '下', '大', '同', 4]
# a.index(x,begin,.end) # 在a中的begin和end之间,查找字符x的下标,没有会报错 a = [1, 2, 3] print(a.index(2)) # 1
列表.count(x, begin, end) # 查询x在列表中的个数 del 列表[下标值] # 根据下标进行删除 列表.pop() # 删除最后一个元素,也可以针对指定的下标删除,会返回删除的内容 列表.remove(元素) # 将指定的元素从列表中删除 列表.sort(reverse=True) # sort方法是将列表按特定顺序重新排列,默认为由小到大,参数reverse=True可改为倒序,由大到小。 列表.reverse() # reverse方法是将list逆置。
元组
元组和列表类似,也是一种有序的,可以存储任意类型数据的容器,它使用括号(())包裹,用tuple来表示,

需要注意的是:元组一旦初始化就不可以修改。或者说它的第一层不可以改变,但它的元素中如果包括容器,那个容器里面的内容就可以修改。
比如:
a = (1, 2, 3, [4, 5]) a[3][1] = 9 print(a) # (1, 2, 3, [4, 9])
注:元组在使用的时候,很容易和方法混淆,所以在最后一个元素的后面一般加一个逗号,这样也不报错,建议加上,
查的方式和列表一样,只是记住不可以删除
集合
要具体说集合首先要补充两个知识点:
类型
可变类型:列表,字典
不可变类型,字符串,数字,元组
访问顺序
直接访问:数字
顺序访问:字符串,列表,元组
映射:字典,集合
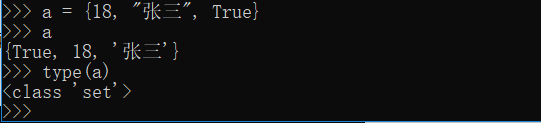
集合表示为set,很类似list列表,但它是不同元素(必须是不可变类型)组成的,无序的容器,它使用花括号({})包裹,set和字典类似,也是一组key的集合,但是不存储value,由于key不能重复,所以,在集合中没有重复的key。
比如:
集合常用方法
# 集合名.pop() 会随机删除 # 集合名.add(元素) 添加元素 # 集合名.remove(元素) 如果删除的没有,会报错 # 集合名.discard(元素) 删除的没有不会报错 a = {1, "2", (3, 4), "4", 2} a.add("22") print(a) # {1, 2, '2', '22', '4', (3, 4)} a.pop() print(a) # {2, '2', '22', '4', (3, 4)} a.remove(2) print(a) # {'2', '22', '4', (3, 4)} a.discard("9") print(a) # {'2', '22', '4', (3, 4)}
两个集合求交集:集合1 .intersection(集合2)或者集合1 & 集合2 两个集合求并集:集合1 union(集合2)或者集合1 | 集合2 两个集合求差集:集合1.difference(集合2)或者集合1 - 集合2 #集合1中的那个成员不在集合2中的返回 两个集合交叉补集:集合1 ^集合2 #并集减去交集
字典
字典表示为dict,使用键值对的形式来存储数据的,使用的时候用花括号({})来对这些键值对进行封装,而且内部也是无序存储的。相对于list来说,字典的查询速度快,不会随着key的增加而变慢,但是需要大量的内存。这个通过key计算位置的算法被称为哈希算法。
如下:

注:键可以使用:元组,数字,字符串,如果是布尔值,会忽略,如果是字典或者列表,会直接报错。
如果键重复,只保留最后一个
字典常用方法
# 取字典值可以用键来取,如果写的是字典中没有的键,会报错,一般用get来取值,没有对应的键会返回None,get的第二个参数可以设置返回的值 a = {"name": "张三", "age": 18, "sex": "男"} print(a["name"]) # 张三 print(a.get("name")) # 张三 print(a.get("nam")) # None print(a.get("nam", "找不到")) # 找不到 print(a["nam"]) # 报错
# 添加一个键值对,直接用:字典名["键名"] = 值 a = {"name": "张三", "age": 18, "sex": "男"} a["address"] = "北京" print(a)
# 字典名.keys() 返回字典所有key,并放在一个类似列表的dict_keys类中 # 字典名.values() 返回字典所有value,并放在一个类似列表的dict_values类中 # 字典名.items() 返回所有key和values,所有的键值对分别构成一个元组,并放在一个类似列表的dict_values类中 a = {"name": "张三", "age": 18, "sex": "男"} print(a.keys()) print(type(a.keys())) print(a.values()) print(type(a.values())) print(a.items()) print(type(a.items())) # 注:可以在for循环中用拆包的方式分别获取key和value值
# 删除一个键值对可以用:del 字典名["键名"] # 删除字典则是:del 字典名 # pop也可以删除一个键值对:字典名.pop(键名,参数二),如果没有对应的键,返回第二个参数,不写的话会直接报错 # 随机删除一个键值对:字典名.popitem() # clear是清空字典 a = {"name": "张三", "age": 18, "sex": "男"} del a["name"] print(a) # {'age': 18, 'sex': '男'} print(a.pop("hobby", "没有")) a.popitem() # {'sex': '男'} print(a) a.clear() print(a) # {} del a print(a) # a被删除,not defined
其他:
di.setdefault("k111","123") # 设置值,如果键存在,则返回原有值,如果不存在,则将第一个参数作为键,第二个参数作为值插入到字典中,并返回值 di.update({"k1":"111","k2":"324"}) # 设置值,如果已经存在则覆盖,不存在则填入,参数中也可以用k1=23,k2="daf"这种格式 根据序列创建字典,di.fromkeys({"k1","k2","k3"],123) # 参数中,第一个列表是所有的key,第二个是指定统一的value,不写位None
关于数据类型常用方法的补充
in方法
可以通过in和not in 判断一个元素是否在容器中
比如:
a = {"name": "张三", "age": 18, "sex": "男"}
print("name" in a) # True
切片
字符串,列表,元组可以通过切片来取值
比如:
a = "中华人民共和国" print(a[1:2]) # 华
注:切片是左闭右开区间
其他
我写的只是常用的,并不是全部,可以在pycharm中用Ctrl加鼠标左键点击类型的名称进入源码中查看完整的,比如进入字符串的用str,字典的用dict
对数据类型常用的操作
常用内置函数
len(item) #计算容器中元素个数
max(item) #在比较容器内元素大小,字典中取key较大者,列表中,数值型和字符型无法比较
min(item) #基本同上,比较小的
del(item) #删除元素
遍历
除了数值型,其他类型基本都可以用for进行遍历,需要注意的一点,可以用for遍历的都是可迭代对象,后面会专门讲到。
强转
数据类型很多可以通过强转来实现类型转换,之前就提到了float()和int(),其他的也是一样,类型名()实现类型强转
字符串,列表,元组都是可迭代对象,可以互相转换
需要注意的是:如果将字符串转换成一个字符串,会将列表整体加引号变成字符串。如何不想要这样的话,只能用自己用for循环写一个,也可以用join来实现,但是,列表中必须都是字符串,要不会报错。
在字符强转中,如果参数是字符串,str()相当于没有改变,用repr()和str的作用相同,只不过如果里面参数是字符串,它会把引号也当作字符转换。
比如:
print(repr("中国")) # '中国' print(str("中国")) # 中国 print("中") # 中
