07.Flask之数据库(1)
ORM
ORM全拼Object-Relation Mapping.- 中文意为
对象-关系映射. -
主要实现模型对象到关系数据库数据的映射.
-
比如:把数据库表中每条记录映射为一个模型对象
-

ORM图解

优点 :
- 只需要面向对象编程, 不需要面向数据库编写代码.
- 对数据库的操作都转化成对类属性和方法的操作.
- 不用编写各种数据库的
sql语句.
- 实现了数据模型与数据库的解耦, 屏蔽了不同数据库操作上的差异.
- 不在关注用的是
mysql、oracle...等. - 通过简单的配置就可以轻松更换数据库, 而不需要修改代码.
- 不在关注用的是
缺点 :
- 相比较直接使用SQL语句操作数据库,有性能损失.
- 根据对象的操作转换成SQL语句,根据查询的结果转化成对象, 在映射过程中有性能损失.
Flask-SQLAlchemy安装及设置
- SQLALchemy 实际上是对数据库的抽象,让开发者不用直接和 SQL 语句打交道,而是通过 Python 对象来操作数据库,在舍弃一些性能开销的同时,换来的是开发效率的较大提升
- SQLAlchemy是一个关系型数据库框架,它提供了高层的 ORM 和底层的原生数据库的操作。flask-sqlalchemy 是一个简化了 SQLAlchemy 操作的flask扩展。
- 文档地址:http://docs.jinkan.org/docs/flask-sqlalchemy
安装
- 安装 flask-sqlalchemy
pip install flask-sqlalchemy -i https://pypi.tuna.tsinghua.edu.cn/simple
- 如果连接的是 mysql 数据库,需要安装 mysqldb
pip install flask-mysqldb -i https://pypi.tuna.tsinghua.edu.cn/simple
但是,当我们满心欢喜的下载mysqldb的时候,就会出现下面恐怖的错误:
![]()
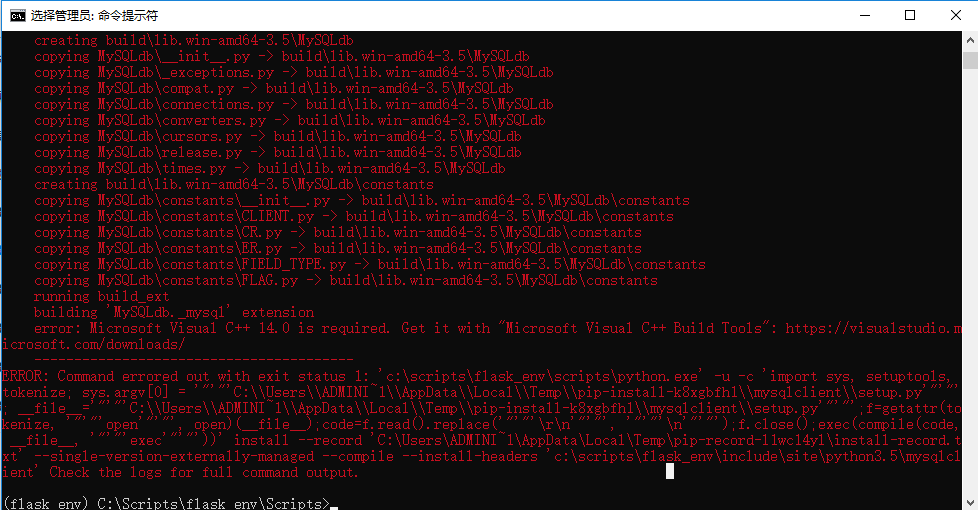
不要慌张,到下面的小网站,下点小东东就可以了。
https://www.lfd.uci.edu/~gohlke/pythonlibs/
我们在这个网站中找到下面内容
![]()
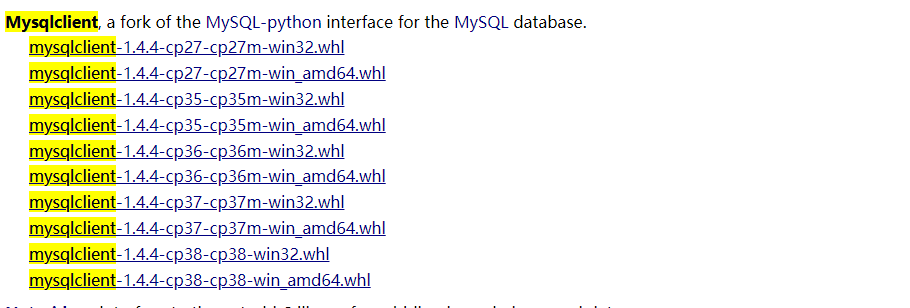
下载的版本:
我的系统是WIN10 64位操作系统的,Python版本是3.5所以我选择的是
mysqlclient-1.4.4-cp35-cp35m-win_amd64.whl
下载之后,找到该文件,右击-》属性-》安全,再将下面地址复制一下
![]()
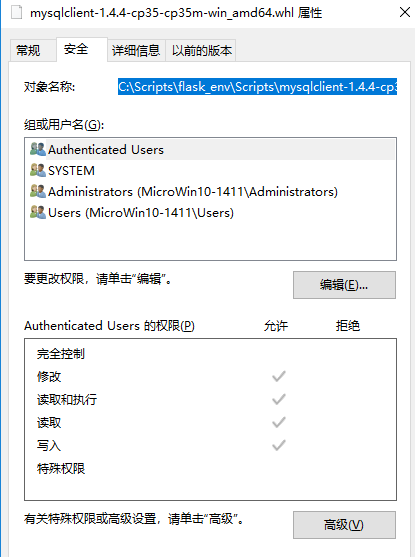
然后来到我们的环境下,进行安装

显示成功之后,我们就可以下载flask-mysqldb了。

不容易,兄弟,干杯!
数据库连接设置
第一步
初始化SQLAlchemy对象
from flask import Flask from flask_sqlalchemy import SQLAlchemy app = Flask(__name__) # 初始化SQLAlchemy对象 db = SQLAlchemy(app) @app.route('/') def hello_world(): return 'Hello World!' if __name__ == '__main__': app.run(debug=True)
初始化之后,当我们运行这部分代码后,会发现报了一堆错误,而错误原因是我们没有设置数据库连接。
第二步
设置数据库连接
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:mysql@127.0.0.1:3306/test'
其实,连接的内容很类似URL地址,里面的root代表用户名,mysql则是密码;127.0.0.1代表着主机名,3306则是mysql的默认端口号,test是要连接的数据库。
注意:设置数据库连接的代码一定要放在初始化SQLAlchemy对象,因为初始化的时候需要读取这些配置信息。
好了,当我们连接好数据库,再次测试的时候,会发现下一个错误。
第三步
设置是否追踪数据库的修改
# 动态追踪修改设置,如未设置只会提示警告 app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
因为会有额外开销,所以直接写False就可以了。
到现在为止,我们运行代码就不会报错了。
第四步
这里还是创建相关数据库
create database test character set utf8;
拓展内容
其他配置
| 名字 | 备注 |
|---|---|
| SQLALCHEMY_DATABASE_URI | 用于连接的数据库 URI 。例如:sqlite:////tmp/test.dbmysql://username:password@server/db |
| SQLALCHEMY_BINDS | 一个映射 binds 到连接 URI 的字典。更多 binds 的信息见用 Binds 操作多个数据库。 |
| SQLALCHEMY_ECHO | 如果设置为Ture, SQLAlchemy 会记录所有 发给 stderr 的语句,这对调试有用。(打印sql语句) |
| SQLALCHEMY_RECORD_QUERIES | 可以用于显式地禁用或启用查询记录。查询记录 在调试或测试模式自动启用。更多信息见get_debug_queries()。 |
| SQLALCHEMY_NATIVE_UNICODE | 可以用于显式禁用原生 unicode 支持。当使用 不合适的指定无编码的数据库默认值时,这对于 一些数据库适配器是必须的(比如 Ubuntu 上 某些版本的 PostgreSQL )。 |
| SQLALCHEMY_POOL_SIZE | 数据库连接池的大小。默认是引擎默认值(通常 是 5 ) |
| SQLALCHEMY_POOL_TIMEOUT | 设定连接池的连接超时时间。默认是 10 。 |
| SQLALCHEMY_POOL_RECYCLE | 多少秒后自动回收连接。这对 MySQL 是必要的, 它默认移除闲置多于 8 小时的连接。注意如果 使用了 MySQL , Flask-SQLALchemy 自动设定 这个值为 2 小时。 |
常用的SQLAlchemy字段类型
| 类型名 | python中类型 | 说明 |
|---|---|---|
| Integer | int | 普通整数,一般是32位 |
| SmallInteger | int | 取值范围小的整数,一般是16位 |
| BigInteger | int或long | 不限制精度的整数 |
| Float | float | 浮点数 |
| Numeric | decimal.Decimal | 普通整数,一般是32位 |
| String | str | 变长字符串 |
| Text | str | 变长字符串,对较长或不限长度的字符串做了优化 |
| Unicode | unicode | 变长Unicode字符串 |
| UnicodeText | unicode | 变长Unicode字符串,对较长或不限长度的字符串做了优化 |
| Boolean | bool | 布尔值 |
| Date | datetime.date | 时间 |
| Time | datetime.datetime | 日期和时间 |
| LargeBinary | str | 二进制文件 |
常用的SQLAlchemy列选项
| 选项名 | 说明 |
|---|---|
| primary_key | 如果为True,代表表的主键 |
| unique | 如果为True,代表这列不允许出现重复的值 |
| index | 如果为True,为这列创建索引,提高查询效率 |
| nullable | 如果为True,允许有空值,如果为False,不允许有空值 |
| default | 为这列定义默认值 |
常用的SQLAlchemy关系选项
| 选项名 | 说明 |
|---|---|
| backref | 在关系的另一模型中添加反向引用 |
| primary join | 明确指定两个模型之间使用的联结条件 |
| uselist | 如果为False,不使用列表,而使用标量值 |
| order_by | 指定关系中记录的排序方式 |
| secondary | 指定多对多中记录的排序方式 |
| secondary join | 在SQLAlchemy中无法自行决定时,指定多对多关系中的二级联结条件 |
连接其他数据库
当然,如果你要连接其他数据库,可以参考下面的方式:
完整连接 URI 列表请跳转到 SQLAlchemy 下面的文档 (Supported Databases) 。这里给出一些 常见的连接字符串。
- Postgres:
postgresql://scott:tiger@localhost/mydatabase
- MySQL:
mysql://scott:tiger@localhost/mydatabase
- Oracle:
oracle://scott:tiger@127.0.0.1:1521/sidname
- SQLite (注意开头的四个斜线):
sqlite:////absolute/path/to/foo.db
数据库基本操作
-
在Flask-SQLAlchemy中,插入、修改、删除操作,均由数据库会话管理。
- 会话用 db.session 表示。在准备把数据写入数据库前,要先将数据添加到会话中然后调用 commit() 方法提交会话。
-
在 Flask-SQLAlchemy 中,查询操作是通过 query 对象操作数据。
- 最基本的查询是返回表中所有数据,可以通过过滤器进行更精确的数据库查询。
代码示例
第一步
创建模型类
class Role(db.Model): # 定义表名 __tablename__ = 'roles' # 定义列对象 id = db.Column(db.Integer, primary_key=True) name = db.Column(db.String(64), unique=True) us = db.relationship('User', backref='role') #repr()方法显示一个可读字符串 def __repr__(self): return 'Role:%s'% self.name
第二步
根据模型类创建表
if __name__ == '__main__': db.create_all() app.run(debug=True)
在这里使用db.create_all()会把所有继承自db.Model的模型类在数据库中生成相关的表,但是这种方法并不好,我们只在这里测试使用。
如果想要删除表的话,可以用:db.drop_all()。
第三步
增加数据
@app.route("/add_role") def add_role(): ro1 = Role(name='admin') db.session.add(ro1) db.session.commit() return "添加成功"
这里要注意,commit是提交的意思,上面例子中,我们添加了一条数据就提交了,其实也可以对数据库完成更多的操作再统一提交。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号