
Python 学习
如何安装Python?
去Python官网下载安装包
在安装过程中第一步需要在安装页面选择添加环境变量add Python 3.7 to PATH
安装完成之后,需要在cmd 输入python 查看python的版本号
用什么软件编写Python?
常用的有Pycharm 、Eclipse 、 VS code
基础知识
1、数据类型:
整数:可以为任意大小、包含负数
浮点数:小数
字符串:以单引号、双引号、三引号括起来的文本
布尔:只有两种True 和Flase
空值:None表示
变量:用于保存数据
- 见名知意
- 变量名是由英文字母,数字和下划线
- 不能以数字开头
- 举例 :
name = input ('键盘输入')
print (name)
扩展:
python为引用变量,存放的是地址,计算机会根据此地址查找对象的值
常量:不可变的量
扩展:python 解释器有;CPython,Jython,IronPython,pyPy....
2、注释
单行注释:# 这是一个注释
多行注释:''' 这是多行注释 '''
3、转义字符
转义符是为了让计算器识别字符串,例如英文的I‘m love you 在计算器输出中时,他会判断字符串,因为出现三个单引号,他识别失败,而转义符就是解决这种问题,当在I'\m love you 在输出时,他就不会讲单引号识别成单个字符串,把这个单引号当成整体内容。
\例子和\
s = "使用\"创建字符串"
print(s)
---使用"创建字符串
a = "亲爱的宝宝们" \
"我爱你们"
print(a)
--亲爱的宝宝们我爱你们
# 在字符串行尾的续行符,即一行未完,转到下一行继续写,使其作为完整的一行内容来输出
\n : 表示换行 换行输出 print('1234\n56789')
\t:表示制表 四个空格即两个tab print('1234\t56789')
r:取消转义字符
当打印输出有多个\\\ 这种情况如目录 需要使用 r 去掉转义字符
扩展

4、占位符
%s : 表示字符串 print('我叫%s,今年%s岁' % (name, age))
%d ; 整数 print('我叫%s,今年%s岁' % (name, 20)) 当在%之后加上数字,意味着这里需要留出相对应空位
%f : 浮点数 print('圆周率=%.6f' % 3.1415926)
在%之后加.输入位数即精确到小数点后几位
input() : 获取用户输入即键盘输入
强制转化:将一个字符串转化成其他类型
int() 将字符串类型数组转换为整数 print('我叫%s,今年%d岁' % (name, int(age)))
print('我叫%s,今年%d岁' % (name, int(age))) # int()将字符串类型数字转换位整数
print('我叫%s,今年%3d岁' % (name, int(age))) # % ---我叫lll,今年 18岁
print('圆周率=%f' % 3.1415926) # %
print('圆周率=%.6f' % 3.1415926) # %
5、字符编码
计算机需要通电工作,电的特性是高低电平,人门从逻辑上讲二进制数对应高低电平,机器也是是识别高低电平,也就是说机器只认识数字。在日常生活中,我们都是用人类能懂得字符交流,为了让机器也识别人类的字符,也就是说,需要计算机翻译人类的字符。
总结就是,字符编码就是讲人类的字符编码成计算机能识别的数字,而这有一套固定的标准。称为字符编码。
ASCII美国人指定的,规定英文字母数字和一些特殊字符与数字对应关系。最多有8位(8位8个二进制),即2**8=256。
GBK
Unicone - 2byte 内存
utf-8 1~4byte 硬盘
7、打印格式化输出
举例:
name = input('请输入您的姓名:')
age = input('请输入年龄:')
# 我叫xxx,今年xx岁
print('我叫' + name + ',今年' + age + '岁')
print('我叫%s,今年%s岁' % (name, age))
print(f'我叫{name},今年{age}岁')
第二和第三在python常用,使用第一种也可以,但是太过于复杂。第二种和第三种记住就可以。

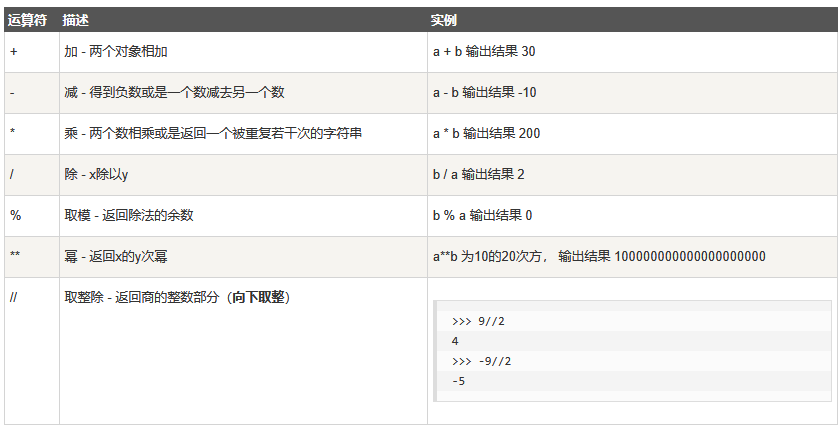
8、运算符
算术运算符
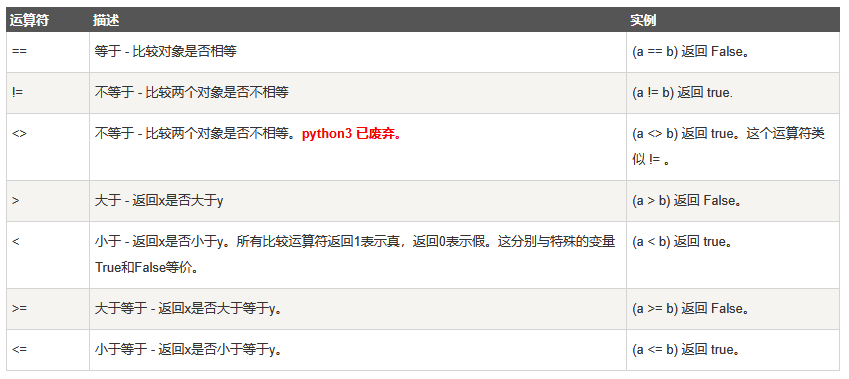
 比较运算符
比较运算符
赋值运算符 =
a = 10
c = a + 1
print(c)
逻辑运算符

9、列表与元组与字典
列表 [ ]:list
python最常用的数据类型,list
列表 [元素1,元素2,元素3]
元素 列表中保存的数据称为元素
元素 元素之间用逗号隔开
列表中的元素是有序的,元素的下标-index,下标从0开始
列表中可以存整数,浮点数,字符串,布尔值
正索引:从0开始
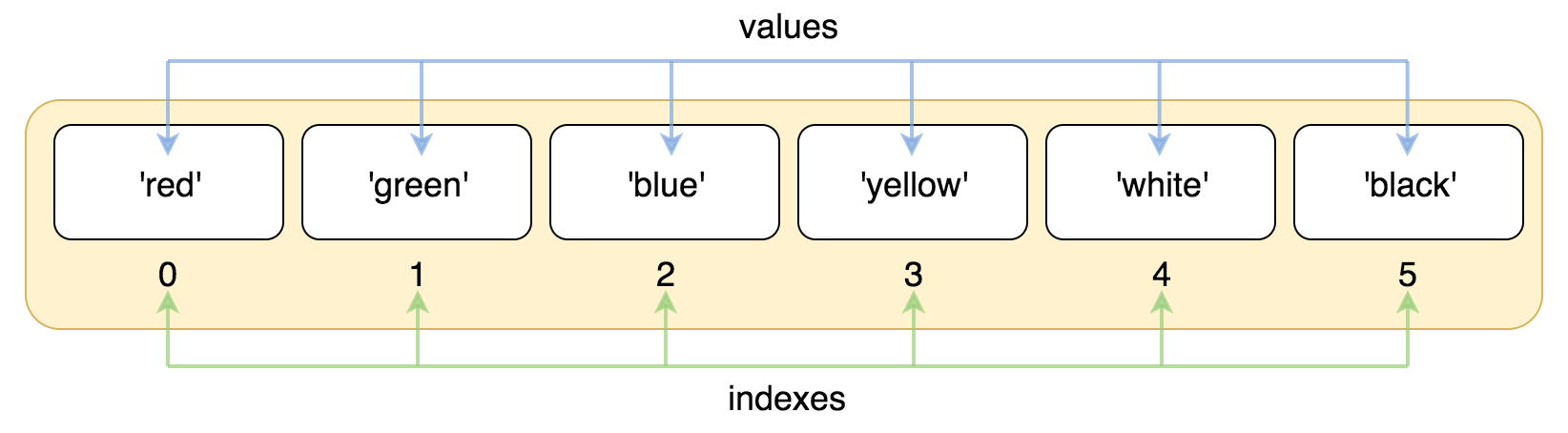
values: 代表元素
indexs: 索引也称为下标
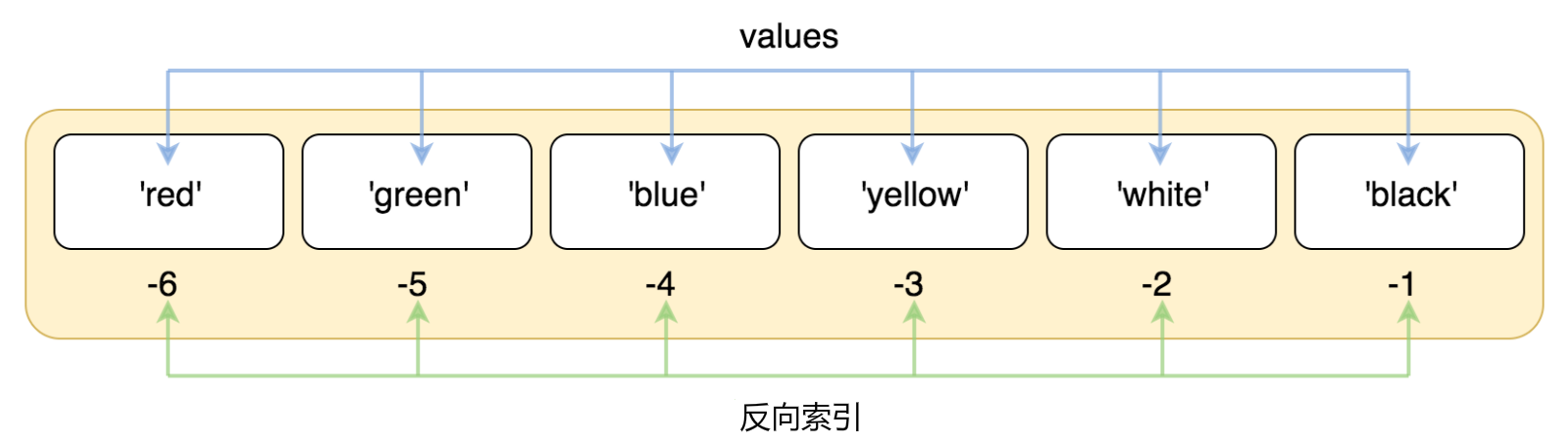
负索引/反向索引:下标从尾部开始,从-1开始
列表操作符:
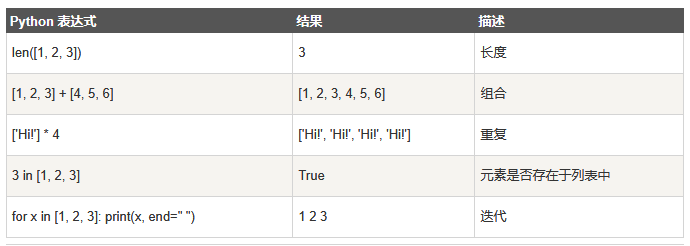
常用函数方法:
获取元素长度len(变量)函数:
# 获取元素个数
print('---获取元素个数')
lenth = len(name3)
print(lenth)
print('-----获取元素长度')
print(len(name4))
# 获取最后一个元素
print('---获取最后一个元素')
print(name3[lenth - 1])
函数扩展:
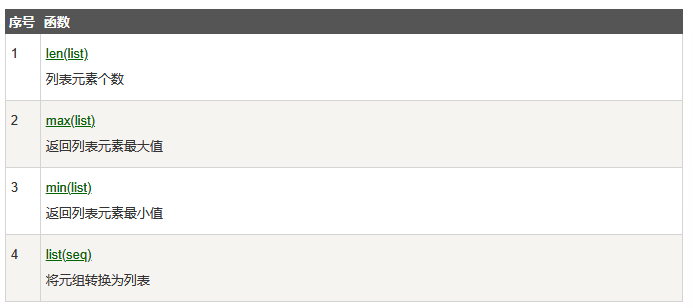
追加元素到列表末尾和:
name3.append('新疆') # 追加元素到列表的末尾
print(name3)
print(name3.append('肖黄'))
print(name3)
追加元素到指定位置insert(索引,‘值’)
name3.insert(0, '成都') # 追加元素到指定位置下标
print(name3)
删除元素用索引pop() 默认删除最后一个:
name5 = name3.pop(5) # 删除按下标删除,并返回指定元素
print(name3)
print(name5)
print(name3.pop(2))
print(name3)
print('----------')
# name.pop() 默认删除最后一个
print('--默认删除最后一个元素打印输出')
print(name3.pop())
清空列表clear():
print(name3.clear())
删除元素用元素remove():
print('---删除指定元素')
print(name3.remove('深圳'))
print(name3)
修改元素 根据index修改:
index = name3.index('北京') # 使用index获取值
name3[index] = '地狱'
print(name3)
print('---修改指定元素')
name3[1] = '天堂' # 修改指定元素按照索引修改
print(name3)
空列表:
空列表也是有意义的,当我们需要存放一些变量是可用列表存放
a = []
二维列表和多维列表:
二维列表也就是在一维列表中添加了新的列表。多维亦是如此。
b = [1,2,3,[4,5,6]]
print(b[1])
print(b[3])
查询二维列表的值
# 取二维列表,先取二维数组的下标,然后在取二维列表中的下标
print(b[3][1])
注意:当下标越界或者是索引越界就会出现异常
lsit index out of range 下标越界错误
元组()
元组与列表类似,不同之处在于处在元组下的元素不能修改。
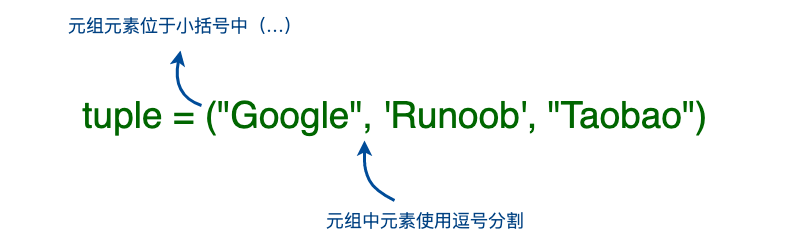
# 元组中只有一个元素时,必须补一个逗号
a = (1,)
print(a)
# 空元组
c = ()
print(c)
元组和列表一样,也是个序列,与列表不同元组是不可变的,只能查询元素,增删改元素都不允许
# 元组中只有一个元素时,必须补一个逗号
a = (1,)
print(a)
# 空元组
c = ()
print(c)
列表与元组转换list 和 tuple
# 列表和元组进行转换
# list 元组转列表 将一个序列变成列表
print('---list 将一个序列变成列表')
print(list(address))
# tuple 列表转换元组 讲一个序列转化成元组
print('---tuple 列表转换元组')
score = [90, 18, 85, 46, 89, 100]
print(tuple(score))
字典 dict
字典能够更加精确的存储数据,以键值对的形式存储。
- 字典中每个key对应一个值,key是不可变化的
- 字典中的数据是无序的
- key,是唯一的,value是可变的
- 字典的查询特别快
- 字典是以空间换时间,会浪费内存
与列表类似有一样的方法
# 字典
classmates = {'王海':90, '骆纯':80, '李宁':70, '赵艳芳':88, '任收港':98, '李颖':85, '王珍':87}
print(classmates)
# 添加元素
classmates['张玮越'] = 83
print(classmates)
# 删除元素
classmates.pop('李宁')
print(classmates)
# 修改值
classmates['张玮越'] = 89
print(classmates)
# 查询
score = classmates.get('赵艳芳')
print(score)
# 计算字典元素个数
print(len(students))
# 清除所有元素
print(student.clear())
# 返回字典中所有的元素的主键key
print(students.keys())
# 返回字典中所有的元素的值value
print(students.values())
# 返回以列表返回可遍历的(键, 值) 元组数组
print(students.items())
print('--for循环遍历字典--')
# 循环遍历key
for i in students:
print(i,students.get(i))
# 遍历value
for value in students.values():
print(value)
# 遍历key,value
for key , value in students.items():
print(key,value)
set集合
- 也是一组key的集合
- setj集合也是无序的
- set中的元素是不可重复的
- set集合可以用来去重和关系运算
- 使用{}大括号/花括号,只能存储不可变类型
扩展:
查看可变数据类型和不可变数据类型
不可变数据类型更改后地址发生改变,可变数据类型更改地址不发生改变
-
不可变数据类型: 当该数据类型的对应变量的值发生了改变,那么它对应的内存地址也会发生改变,对于这种数据类型,就称不可变数据类型。
-
可变数据类型 :当该数据类型的对应变量的值发生了改变,那么它对应的内存地址不发生改变,对于这种数据类型,就称可变数据类型
-
数据类型 可变/不可变 整型 不可变 字符串 不可变 元组 不可变 列表 可变 集合 可变 字典 可变 -
可以使用id()方法查看
10、分支结构
首先讲下python的流程控制
分三种:
- 顺序结构:从上到下执行
- 分支结构:根据条件选择执行某段代码,实现分支只有一种if
- 循环结构:让代码重复执行,在python中,有两种for、while两种方式
-
if单分支结构:
if单分支结构-满足某个条件就执行某个操作,不满足就不执行
# 语法 : # if 条件语句: # 代码块 age = int(input('请输入您的你年龄:')) if age <= 18: # 缩进-indent print('未成年')条件语句可以是任何有结果的表达式,比如:独立的数据、运算表达式(不能是赋值运算)、函数调用表达式
:固定写法
代码块和if 保持一个缩进的一条或者多条语句;满足条件才会执行的语句
执行过程:先判断条件语句是否是true(若果不是布尔值,就转化为布尔值再判断),如果为true就执行if语句的代码块,否则不执行
-
if双分支结构
age = int(input('请输入您的你年龄:')) if age <= 18: # 缩进-indent print('未成年') else: # 无条件执行 print('成年人') # else可以有,可以没有,但是最多有一个, -
if多分支
weight = float(input('请输入您的体重(kg):')) height = float(input('请输入您的身高(m):')) # 计算bmi bmi = weight/height**2 print('您的bmi指数是%.1f'%bmi) if bmi<18.5: print('太瘦') elif bmi<25: print('正常') elif bmi<28: print('微胖') elif bmi<32: print('肥胖') else: print('死肥宅')多分支,即有多个选择判断,使用elif 条件语句:,最后面的else 可有可无。
11、循环结构
循环示意图:
for 循环
又称:循环 迭代,遍历
遍历操作,以此从集合容器中取每个值
循环格式:
# for 临时变量 in 字符串,列表等:
# 执行代码块
举例
# 求100之内数和
sum = 0 # 定一个初始变量 ,用于存放累加和
for data in range(1,101): # 使用range函数创建一个顺序的集合,range(1,101)1代表从1开始,101代表索引即下标为101的元素,代表是100这个元素
sum = sum + data # 每次累加,
print(f'--{sum}') # 打印输出
# 输出100以内的偶数和奇数
for i in range(1, 101):
if i % 2 == 0: # 判断是否能被2整除,即为偶数
print(f'是偶数{i}')
else: # 其他就是奇数
print(f'是奇数{i}')
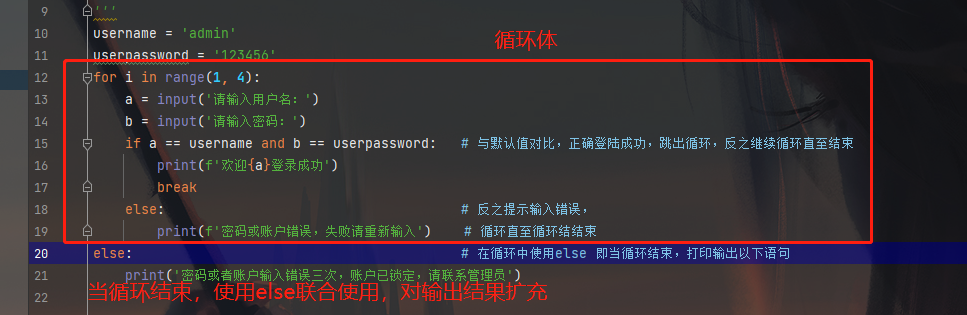
案例----登录判断用户和密码,限定用户输入次数。for 与else 联合使用
'''
案例,限定用户登陆的次数,一旦三次没有登录成功就提示用户已被锁定
思路: 用for循环控制尝试登陆的次数,执行完整个for循环没有登录成功则锁定账户
所采用的结构:
for 变量 in 遍历对象:
执行代码块
else:
循环执行结束后,要执行的内容
'''
username = 'admin'
userpassword = '123456'
for i in range(1, 4):
a = input('请输入用户名:')
b = input('请输入密码:')
if a == username and b == userpassword: # 与默认值对比,正确登陆成功,跳出循环,反之继续循环直至结束
print(f'欢迎{a}登录成功')
break
else: # 反之提示输入错误,
print(f'密码或账户错误,失败请重新输入') # 循环直至循环结结束
else: # 在循环中使用else 即当循环结束,打印输出以下语句
print('密码或者账户输入错误三次,账户已锁定,请联系管理员')
注意:只要循环语句中break语句没有执行,else就会执行 ,也是break与else使用。
while 循环
重复执行某一段代码,当达到循环条件时,结束循环。
格式:
# 1. 设置循环结束条件
# 2. 书写循环条件判断条件
while 判断条件:
# 3. 需要重复执行的代码
# 4. 改变循环的初始条件(计数器)
# 1. while 是关键字
举例:
'''
while循环
'''
s = 0
i = 1
while i<=10: # 只要条件满足,就执行循环体
s = s + i
i = i + 1
print(s,i)
for循环与while循环区别
- for循环已知循环次数,
- while循环不知道循环的次数,只有循环条件
break:跳出循环,执行循环之外的语句
for i in range(1,11): # 定义一个集合
if i ==4: # 判断当i =4 跳出循环
break
print(i) # 此时还在for中执行打印输出循环次数
continue:跳过本次循环,继续下次循环
for i in range(1, 11):
if i == 5:
continue # 跳过此次循环,不计入打印
print(i)
12、函数
简单讲就是讲代码封装起来,方便使用,函数就是‘洗衣机’ , 定义函数就是‘准备装洗衣机’ , 调用就是 ‘ 用洗衣机 ’, 函数注释就是 ‘ 洗衣机说明书 ’ , return 返回值就是 ‘ 拿出洗完的衣服 ’。
语法格式:
# def 函数名(参数名1, 参数名2) :
# ''' 函数注释 '''
# 函数体代码
# return 返回值
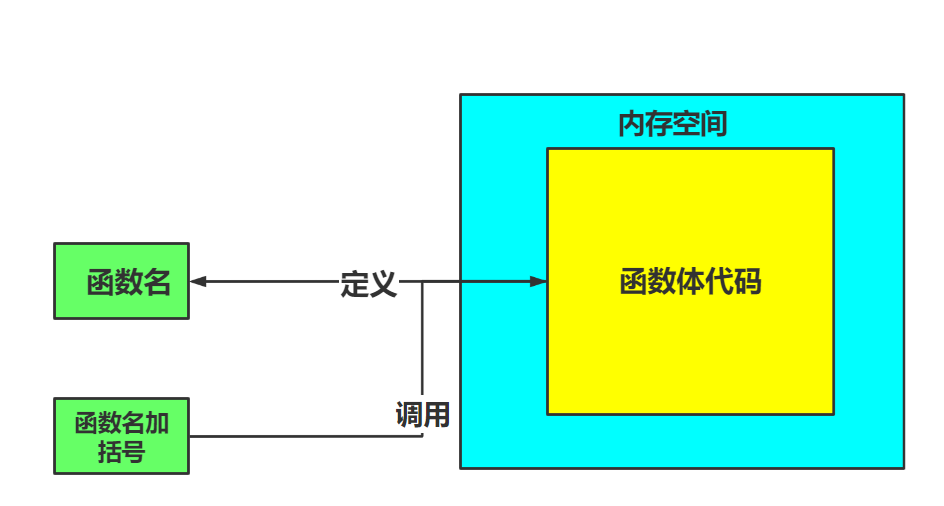
- 函数的定义
- 函数必须先定义后调用
- 函数在定义阶段只检测语法不执行语法,简单讲就是自检,不执行输出
- 函数只有在调用阶段才会执行函数体代码
- 函数调用
- 函数名加括号
- 定义时有参数,需要传参
图了解函数
函数的分类:
内置函数
- python解释器自带的函数
自定义函数
- 有参函数
- 无参函数
- 空函数
注意:
- 函数一定要有返回值,如果不显示指明返回值,则默认返回None
- return语句只能返回一个值,如果试图返回多个值,会自动打包成一个元组
函数参数详解
'''
位置参数:positional argument
-必须传参
-传入的实参按照顺序(位置)传递给形参, 不能多,不能少
默认参数: default parameter
-有默认值的参数
-可以极大的降低调用函数的难度
-默认参数必须放在位置参数的后面
-默认参数可以按照顺序传参, 但如果不按照顺序传参,则必须指明参数名称
可变参数:
-实参的多少不固定,形参前面有一个*, 星号的作用是将传入的所有实参封装为一个元组
*在实参的前面表示拆包,*在形参的前面表示打包
-可变参数允许传入0个或多个实参
-一个函数中最多有一个可变参数,也可以没有
关键字参数:keyword arguments
-形参的前面有2个星号: **, 将传入的所有参数封装为一个字典
-关键字参数允许传入0个或多个包含参数名的参数
-可以扩展函数的功能
-一个函数中最多有一个关键字参数,也可以没有
命名关键字参数:keyword-only argument
-命名关键字参数必须写在 一个单独的 * 号的后面
-命名关键字参数如果放在可变参数的后面,可以省略 *
-命名关键字参数必须给值,除非已经有默认值了
'''
位置参数:
# 一个参数 求数的平方
def sss(x):
return x * x
print(sss(10))
print('------')
# 两个参数 求数任意次方
def ddd(x, y):
return x ** y
print(ddd(10, 20))
默认参数:
def sqere(x, y=2):
return x + y
# 因为有默认的值,在传参数的时候,可以直接使用默认的
print(sqere(10))
# 也可以同时传参,将默认的值替换了
print(sqere(10, 3))
可变参数:
def sum(*data):
print(data)
s = 0
for i in data:
s = s + i
return s
# 直接将多参数传给函数
r = sum(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
print(f'r={r}')
# 定义一个列表存放传参
data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 与函数中参数要相同
r = sum(*data)
print(f'r={r}')
关键字参数:
def info(name, age, gender='男', city='西安', **kw):
print(name, age, gender, city, kw)
info('tom', 20, '男', '北京')
info('tom', 20, '男', '北京', marrige='否', car='BBA', house='200')
命名关键字参数:
def info(name, age, gender='男', city='西安', *, hobby, education='本科'):
print(name, age, gender, city, hobby, education)
# info('tom', 20, '男', '北京', marrige='否', car='BBA', house='200')
info('tom', 20, '男', '北京', hobby='游戏', education='本科')
info('tom', 20, '男', '北京', hobby='游戏')
多种参数同时使用:
def funtion(a,b,c=2,d='tom',*e, f,g,**h):
print(a,b,c,d,e,f,g,h)
# 分析,a,b,为位置参数,c为默认参数,形参中*e代表可变参数,形参**h为关键字参数
funtion(1,20,3,'mike',3,6,9,f=100, g=200, marrige='否', car='BBA', house='200')
def funtion(*args, **kw):
print(args, kw)
# 前面到9,都是可变参数,因为后面是直接定义参数赋值,归到命名关键字参数
funtion(1,20,3,'mike',3,6,9,f=100, g=200, marrige='否', car='BBA', house='200')
13、递归函数
函数在运行过程中,直接和间接调用自身
特点:
- 必须有一个结束条件
- 每一次递归都必须离结果更进一步
- 通常前一次的输出作为下一次输入
- 没有结束条件,递归次数过多导出内存溢出,即报错
'''
5! = 5*4*3*2*1 = 5*4! = 5*(5-1)!
4! = 4*3!
3!= 3*2!
2!= 2*1!
1!= 1
'''
# 得出规律 n! = n* (n-1)!
def f(n): # 定义函数
if n == 1: # 结束条件-边界值条件
return 1
return n * f(n - 1) # 返回值对自身调用
print(f(5))
14、变量
全局变量
- 整个模块
局部变量
- 定义变量的函数或方法
成员变量/实例变量
- 定义变量的实例中:构造方法
__init__()中定义的,通过 self 参数引用;
类变量
- 定义变量的类中,在对象/类中,不在对象/类的函数中
总结:Python中变量的区别就是作用域不同,作用域越小的变量,优先级越高
# 局部变量和全局变量
# python中数据有类型,变量没有
# 变量之间唯一区别就是变量的作用域不同
# 全局变量-作用域是整个模块
# 局部变量-作用域在定义函数之中
# 局部变量的优先级高于全部变量
# 优先使用局部变量,一般不要使用全局变量
#成员变量/实例变量
# 作用域在定义变量的实例中
#类变量
# 定义变量的类中
a = 10 # 全局变量 - 作用域是整个模块
print(a)
def f(x):
b = "5" # 局部变量 - 作用域是在定义它的函数之中- 局部变量的优先级高于全局变量
print(b)
global a # 声明a是一个全局变量
a = 8
print(f'a1={a}')
f(4)
# print(b)
def m():
b = 9
print(f'a2={a}')
m()
class F():
clazz = 56 # 类变量
def __init__(self, v3)
v1 = 10 # 局部变量
self.v3 = v3 # 成员变量/实例变量
15、列表/元组/字符串切片---[:]
切片顾名思义及把列表切开分成不同的部分
注意:
- 切片操作产生一个新的列表
- 切片操作可以用于列表、元组、字符串
'''
切片
切片操作产生一个新的列表
因为切片操作适用于列表,元组,字符串
'''
names = ['王海', '骆纯', '李宁', '赵艳芳', '任收港', '李颖']
m = [names[0], names[1], names[2]]
print(m)
m = names[1:3] # 包含前面的索引,不不包含后面的索引
print(m)
m = names[2:] # 截取到末尾
print(m)
m = names[:4] # 从头开始截取
print(m)
m = names[:] # 复制列表
print(m)
print(id(m))
print(id(names))
# id()查看内存地址
n = names
print(n.pop())
print(id(n))
print(id(names))
o = names[::2] # 步长默认是1,也就是说::后面接步长
print(o)
16、列表/元组/字典生成式
t2 = (i for i in range(100)) # 元组()
print(t2) # 此时打印的这个对象的地址
print(tuple(t2)) # 将对象转化为元组
# 列表和字典无需转化
t3 = [i for i in range(10)] # 创建一个列表 []
print(t3)
t4 = {i for i in range(100)} # 字典表达式 {}
print(t4)
生成式:元组特殊需要对其tuple转化,其余[列表]和{字典}
17、装饰器
在不改变函数原有代码的情况下,增强函数的功能
装饰器本质上是一个高阶函数

'''
装饰器
作用:
在不改变函数原有代码的情况下,增强函数的功能
原理:
装饰器本质上是一个高阶函数,传入一个函数作为参数,然后返回一个新的函数
'''
import time
def log(func): #
def wrapper(*args, **kw):
print(f'正在执行函数{func.__name__}:')
return func(*args, **kw)
return wrapper
def service(func):
print(f'正在执行函数{func.__name__}:')
@log # now = log(now) # 调用这个函数@函数名
def now():
# print(f'正在执行函数-{now.__name__}:')
# service(now)
print(time.strftime('%Y/%m/%d %H:%M:%S'))
now()
def f():
print(f'正在执行函数{f.__name__}:')
# service(f)
pass
# 此处是直接调用函数中的函数
# f = log(f)
@log # g=log(g)
def g():
# print(f'正在执行函数{g.__name__}:')
# service(g)
pass
f()
g()
对于修饰器来讲最主要的是会调用,及@函数名,与运行函数的调用。
18、高阶函数
- 函数名就是一个变量,这个变量指向了函数对象本身
- 如果一个函数f接收了另一个函数g作为参数,那么我们就把函数f称为-高阶函数
- 如果一个函数f返回了另一个函数g作为返回值,那么我们就把函数f称为-高阶函数
- 闭包:内部函数引用外部函数
def g(x): # 参数函数
return x * x
x = 3
# 函数作为参数
def f(x, g): # g代表上面的函数
return g(x) + g(x)
print(f(x, abs))
print(f(-3, abs))
print(f(-3, g))
# 函数作为返回值
def sum(*args):
def ss():
s = 0
for i in args:
s = s + i
return s
return ss # 返回值为函数
r = sum(1, 4, 7, 9, 10, 22)
print(f'r={r}') # 打印功能地址
print(f'r={r()}') # 调用函数输出
19、匿名函数
匿名函数及lambda表达式,
- 匿名函数及没有名字,
- 通常用于判断或者计算
- 函数的输入值为参数,输出值由表达式计算出来
# 匿名函数-lambda表达式,默认有一个return,将表达式的结果返回
r = map(lambda x:x*x,[1,2,3,4,5]) # 匿名函数求列表阶乘
print(list(r)) # 将map转化list
ff = lambda x:x*x
print(ff(4))
# 举例
print('---利用map函数将字符串首字母变为大写,其余字母小写(使用lambda表达式)---')
a = ['tom', 'MIKE', 'Tony']
# 定义一个变量,先将列表转化为map函数,在使用匿名函数,
# 对列表中元素操作调用map函数的方法capitalize首字母大写,最后对结果强制转为list
# lamba函数格式:lamba 变量:操作 ,变量
list_name = list(map(lambda a: a.capitalize(), a))
print(list_name)
# s:s[0]获取下标为0的元素,调用函数upper转化大写,+ 拼接字符串s[1:]从下标为1开始直至结束,使用函数lower()转化为小写,m代表
list1 = map(lambda a: a[0].upper() + a[1:].lower(), a)
print(list(list1))
20、模块
模块
一个.py文件就是一个模块(module)
-提高代码的可维护性
-方便代码复用
-避免函数名和变量名冲突
包
一个包含__init__.py模块的文件夹就是一个包(package)
-避免模块名冲突
-方便代码管理
# 自定义模块
# import demo19_装饰器
from demo19_装饰器 import log
from ppp.demo import ddd
# 系统模块
import time
import sys
# 第三方模块
# pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/ - 设置镜像
# pip list - 查看已安装模块
# pip install requests - 安装模块
# pip uninstall requests - 卸载模块
21、面向对象编程
面向对象编程
面向过程,函数是核心
面向对象
Class:类
类名首字母一般大写
写的类都是自定义类型
object:(对象)object是所有类的父类,默认继承object,可以省略不写
self.name 成员变量
面向对象编程三大特点
- 封装:将数据和处理数据的方法都封装在对象中
- 继承:当我们定义一个类的时候,都可以从某个现有的类继承,新的类称为子类(Subclass),
被继承的类称为父类(基类,超类SuperClass),通过继承,子类可以获取父类的全部功能 - 多态:一个对象既是子类的实例,也是父类的实例
class Person: # 创建父类
def __init__(self, name, age): # 定义成员变量
self.name = name
self.age = age
def talk(self): # 定义成员方法
print(f'{self.name}正在大声的说废话...')
class Worker(Person): # 继承
def __init__(self, name, age, position): # 成员变量
super().__init__(name, age) # 调用父类的初始化方法
self.position = position # 创建子类独有的成员变量
# 方法重写-子类和父类存在同名方法时,子类的方法会覆盖父类的方法
def talk(self):
# super().talk()
print(f'{self.position}{self.name}正在大声的讨论技术...')
# 实例化
# 创建某一个类的具体的一个对象的过程,称为实例化instanciate,
# 创建出来的对象也称为实例instance
# w = Worker('jonny', 30)
w = Worker('jonny', 30, '高工') # 创建工人对象实例
w.talk() # 调用子类重写父类的方法
22、异常处理
- try:
- 可能出问题的代码,必须要有,但是只能有一个
- except:
- 捕捉异常,发生异常时才执行,可以有,也可以没有,也可以最多有一个
- 当多个except语句时,小类型一定要放在大类型的前面
- finally
- 一定要执行的代码放在这里,可以有,也可以没有,但是最多有一个
- breakpoint:断点
try:
n = int(input('请输入一个整数:'))
a = 0
print(n,a)
r = n/a
print(f'r={r}')
# except ZeroDivisionError as e: # 捕捉异常
# print(f'ZeroDivisionError:{e}')
# except TypeError as e:
# print(f'TypeError:{e}')
# except Exception as e:
# print(f'Exception:{e}')
finally:
print('--OVER--')
print('--搞定收工--')
23、IO流
Input/Output
读(输入):从硬盘到内存
写(输出):从内存到硬盘
读文件:
- r:read
- encoding:编码方式,默认是gbk
对文件或者其他类型的文件时,都需要异常的处理,在对于文件操作时,使用以下格式
with open(r'.\demo.txt', 'r', encoding='utf-8') as f:
# read:读取文件的全部内容
# read(n): 读取指定个数的字符
# readline: 按行读取
# readlines(): 读取所有的行
r = f.readlines()
print(r)
'''
写文件
写的时候,如果文件不存在,则会创建一个新文件
w: write,覆盖写
a: append,追加写
'''
with open('demo.txt', 'a', encoding='utf-8') as f:
f.write('\n上海疫情失控。')
'''
: binary 二进制
'''
with open('demo.txt', 'wb') as f:
r = f.read()
print(r)
with open(r'D:\workspase\20190115-5.jpg', 'rb') as d:
# 打开被复制的图片,需要rb
# 读取图片
data = d.read()
print(data)
# 关闭
d.close()
with open(r'.\20220407.jpg', 'wb') as s:
new_data = s.write(data)
s.close()
24、字符串
'''
字符串
'''
import re
# 字符串切片
s = 'abcdefg'
print(s[:3]) # 切到 d(不包含d) 使用下标
index = s.index('d') # 切到 d(不包含d) 指定元素
print(s[:index])
s = ' tom, mike, jerry\n '
'''
split:
按照指定字符进行切分,并将切分的结果以列表的形式返回
strip:
去除字符串前后多余的空白字符
'''
# r = s.split(',', 1)
r = s.split(',')
print(r)
# 遍历元素按,分割字符串,去掉空白字符
r = [i.strip() for i in r]
# 列表生成式
r = [i.strip() for i in s.split(',')]
print(r)
a = ' abc\n '
print(a)
print(a.strip())
'''
正则表达式
'''
# 因为有边界值,当前面有空格,会选择一个空格
r = re.split(r'\s+', s)
print(r)
25、连接数据库数据库操作
- 导入数据包,import mysql.connector
- 连接数据库:
- 获取游标(操作数据的对象):cursor = db.cursor()
- 操作数据:cursor.execute('sql操作语句')
- 提交事务:mysqldb.commit()
- 关闭连接:mysqldb.close
# 连接数据库
db = mysql.connector.connect(host='localhost',
port=3306,
user='root',
password='123456',
database='demo') # 指定数据库
# 创建游标
cursor = mysqldb.cursor()
# 操作数据
# 创建数据库
cursor.execute('CREATE DATABASE demo CHARACTER SET "utf8";')
# 更新数据
cursor.execute("UPDATE USER SET age = %s WHERE id =%s;",(age,id))
# 提交事务
'''事务
将一系列可以看做一个整体的操作称为一个事务
提交commit - 如果事务执行成功,则提交,让改动永久生效
回滚rollback- 如果事务执行失败,则回滚,撤销之前的操作
A 原子性
C 一致性
I 隔离性
D 持久性
'''
mysqldb.commit()
# 关闭连接
mysqldb.close
# 查询数据
cursor.execute('select * from user')
# 获取查询的结果
result = cursor.fetchall() # 查询使用游标的fetchall方法,查询结果为一个列表包含元组
print(result)
ORM对象关系映射
将数据的数据映射到代码对象中,主要为了查询结果
# 获取查询的结果
result = cursor.fetchall()
# 创建对象
class User:
def __init__(self, id, name, age):
self.id = id
self.name = name
self.age = age
# 将查询结果给他对象实例化
user1 = User(result[0][0],result[0][1],result[0][2])
# 使用for循环遍历结果将数据放到对象中
users = []
for idd, name, age in result:
print(idd, name, age)
users.append(User(idd, name, age))
print(users)
# 查看对象内存地址
print(hex(id(users[0])))
26、方法种类
class Demo:
clazz = 88
def __init__(self, name):
self.name = name
# 实例方法 - 通过实例对象调用
def f(self):
print(self.name)
# 静态方法 - 可以用实例进行调用,也可以直接使用类名进行调用(推荐)
@staticmethod
def m():
print('好好学习,天天向上')
# 类方法 - 可以用实例进行调用,也可以直接使用类名进行调用(推荐)
@classmethod
def n(cls): # cls代表当前类对象
print(cls.clazz)
d = Demo('tom')
d.f()
d.m()
Demo('mike').m() # 当通过对象调用对象的方法时,因为对象有实例方法,需要传参
Demo.m()
Demo.n()
d.n()
