15. 散列表
一、什么是散列表
散列表(Hash Table),又称 哈希表,它是一种数据结构,特点是 数据元素的关键字与其存储地址直接相关。
我们将每个关键字映射到从 0 到 TableSize-1 这个范围中的某个数,并且放到适当的单元中。这种映射就叫做 散列函数。理想情况下,它应该运算简单并且应该保证任何两个不同的关键字映射到不同的单元。不过,这是不可能的,这是因为单元的数目是有限的,而关键字实际上是无穷无尽的。
如果新插入的元素的哈希地址已经存在另一个元素的话,就会产生 哈希冲突 问题。解决哈希冲突的方法一般有 开放地址法 和 分离链接法 两类。
ADT SymbolTable
{
Data:
Table∈SymbolTable, Name∈NameType, Attribute∈AttributeType;
Operation:
SymbolTable InitializeTable(int TableSize); // 创建一个长度为TableSize的表
int IsIn(SymbolTable Table, NameType Name); // 查找特定的名字Name是否在符号表Table中
Attribute Find(SymbolTable Table, NameType Name); // 获取Table中指定名字Name对应的属性
SymbolTable Modefy(SymbolTable Table, NameType Name, AttributeType Attribute); // 将Table中指定名字Name的属性修改为Attribute
SymbolTable Insert(SymbolTable Table, NameType Name, AttributeType Attribute); // 向Table中插入一个新名字Name及其属性Attribute
SymbolTable Delete(SymbolTable Table, NameType Name); // 从Table中删除一个名字Name及其属性
} ADT SymbolTable;
二、散列函数
一个好的散列函数应该考虑下列两个因素:
- 计算简单,以便提供转换效率。
- 关键字对应的地址空间分布均匀,以尽量减少冲突。
一般,关于数字关键字的散列函数,我们可以通过如下方法构造:
- 直接定址法:取关键字的某个线性函数值为散列函数,即 \(h(key) = a * key + b\)。
- 除留余数法:取关键字取余某个整数,即 $h(key) = key % a $。
- 数字分析法:分析数字关键字在各位上的变化情况,取比较随机的位为散列地址。
- 折叠法:把关键字分隔成位数相同的几个部分,然后叠加。
关于字符关键字的散列函数的构造方法一般如下:
- ASCII 码加和法:\(h(key) = (\sum{key[i]}) \% TableSize\)。
- 移位法:
三、哈希冲突的解决方法
3.1、开放地址法
在开放地址散列算法系统中,若发生了第 i 次冲突,则试探下一个地址将增加 \(d_{i}\),基本公式是:\(h_{i}(key) = (h(key) + d_{i}) \% TableSize\)。\(d_{i}\) 决定了不同的解决冲突方案。
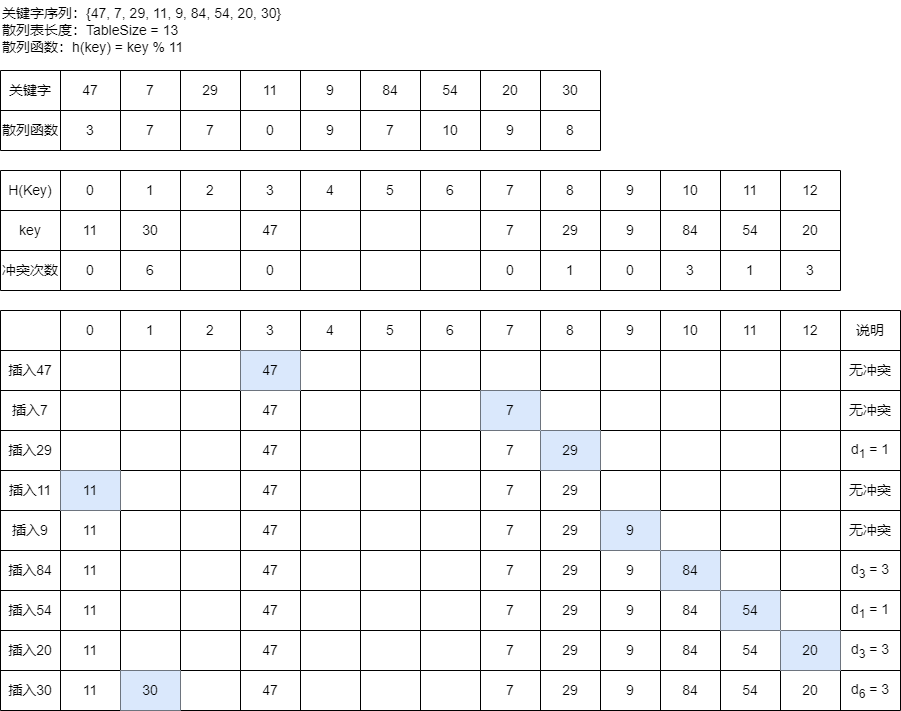
3.1.1、线性探测法
线性探测就是以 增量序列 \(1,2, ..., (TableSize - 1)\) 循环试探下一个存储地址。
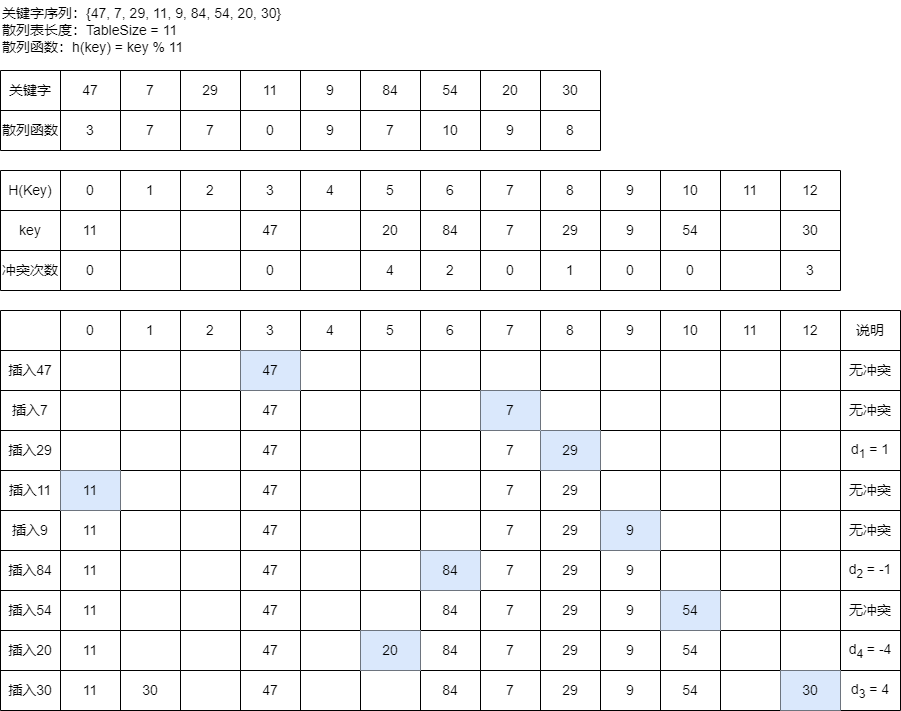
3.1.2、平方探测法
平方探测就是以 增量序列 \(1, -1^{2}, 2, -2^{2}, ..., q^{2}, -q^{2}, 且 q ≤ \frac{TableSize}{2}\)循环试探下一个存储地址。
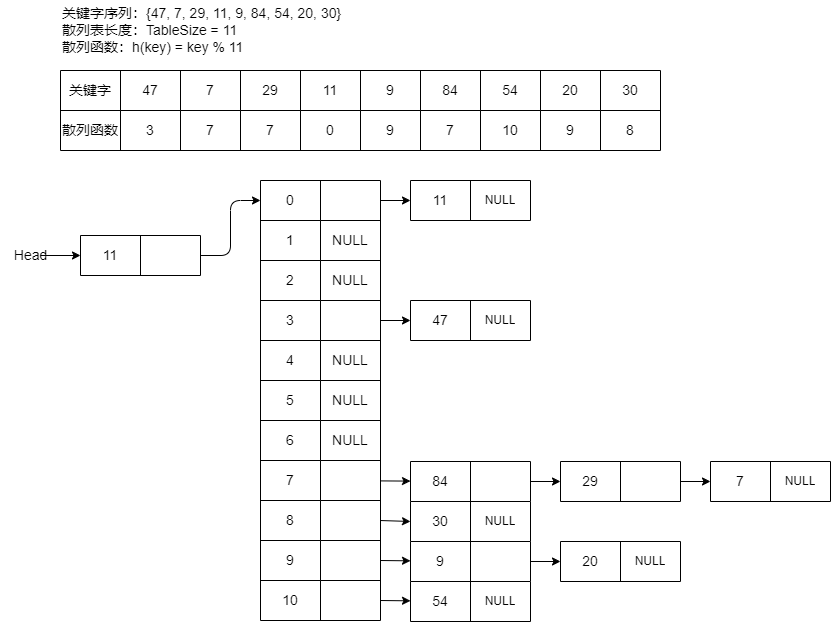
3.2、分离链接法
分离链接法 就是将相应位置上冲突的所有关键字存储在同一个单链表中。
typedef int ElementType;
typedef struct ListNode
{
ElementType Data;
struct ListNode * Next;
}ListNode, * Positon, *List;
typedef struct SymbolTable
{
int TableSize;
List * TheLists;
}SymbolTable, * HashTable;
初始化 Hash 表:
/**
* @brief 初始化Hash表
*
* @param TableSize Hash表的大小
* @return HashTable 执行Hash表的指针
*/
HashTable InitialzeTable(int TableSize)
{
if (TableSize < 0)
{
return NULL;
}
HashTable Table = (HashTable)malloc(sizeof(SymbolTable));
Table->TableSize = TableSize;
Table->TheLists = (List *)malloc(sizeof(List) * TableSize);
for (int i = 0; i < TableSize; i++)
{
Table->TheLists[i] = malloc(sizeof(ListNode));
Table->TheLists[i]->Data = i;
Table->TheLists[i]->Next = NULL;
}
return Table;
}
Hash 函数:
/**
* @brief Hash函数
*
* @param Table 哈希表
* @param Element 关键字
* @return int 根据关键字计算出的索引
*/
int Hash(HashTable Table, ElementType Element)
{
return Element % Table->TableSize;
}
根据关键字查找元素:
/**
* @brief 根据关键字查找元素
*
* @param Table Hash表
* @param Element 关键字
* @return Positon 如果找到返回该元素位置,否则返回NULL
*/
Positon Find(HashTable Table, ElementType Element)
{
Positon P = NULL;
if (Table == NULL)
{
return NULL;
}
List L = Table->TheLists[Hash(Table, Element)];
P = L->Next;
while (P != NULL && P->Data != Element)
{
P = P->Next;
}
return P;
}
往 Hash 表中插入元素:
/**
* @brief 往Hash表中插入元素
*
* @param Table Hash表
* @param Element 关键字
*/
void Insert(HashTable Table, ElementType Element)
{
Positon P = NULL, NewCell = NULL;
List L = NULL;
if (Table == NULL)
{
return;
}
P = Find(Table, Element);
if (P == NULL) // 如果没有找到
{
L = Table->TheLists[Hash(Table, Element)];
NewCell = malloc(sizeof(ListNode));
NewCell->Data = Element;
NewCell->Next = L->Next;
L->Next = NewCell;
}
}
根据关键字删除元素:
/**
* @brief 根据关键字删除元素
*
* @param Table Hash表
* @param Element 关键字
*/
void Delete(HashTable Table, ElementType Element)
{
Positon P = NULL;
List L = NULL;
if (Table == NULL)
{
return;
}
P = Find(Table, Element);
if (P == NULL)
{
printf("未找到%d\n", Element);
return;
}
L = Table->TheLists[Hash(Table, Element)];
while (L->Next != P)
{
L = L->Next;
}
L->Next = P->Next;
free(P);
}
遍历 Hash 表:
/**
* @brief 遍历Hash表
*
* @param Table
*/
void PrintHashTable(HashTable Table)
{
if (Table == NULL)
{
return;
}
for (int i = 0; i < Table->TableSize; i++)
{
printf("key([%d]): ", i);
List L = Table->TheLists[i];
L = L->Next;
while (L != NULL)
{
printf(" -> %-3d ", L->Data);
L = L->Next;
}
printf("\n");
}
}
