
01. 初识数据结构
一、什么是数据结构
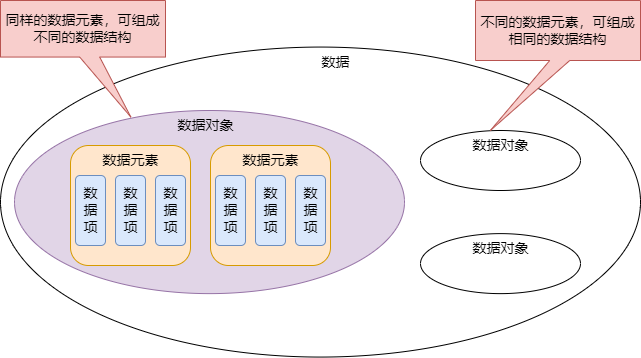
数据 是 信息的载体,是描述客观事物属性的数、字符及所所有输入到计算机中并被计算机程序识别和处理的符号的集合。数据是计算机程序加工的原料。数据元素 是 数据的基本单位,通常作为一个整体进行考虑和处理。一个数据元素可以由若干个数据项组成,数据项是构成数据元素的不可分割的最小单位。数据对象 是具有 相同性质 的 数据元素的集合,是数据的一个子集。数据结构 是相互之间存在一种或多种 特定关系 的 数据元素的集合。
数据结构是数据对象,以及存在于该对象的实例和组成实例的数据之间的各种联系。这些联系可以用通过定义相关的函数实现。数据结构是 ADT(抽象数据类型 Abstract Data Type)的物理实现。
二、数据结构的三要素
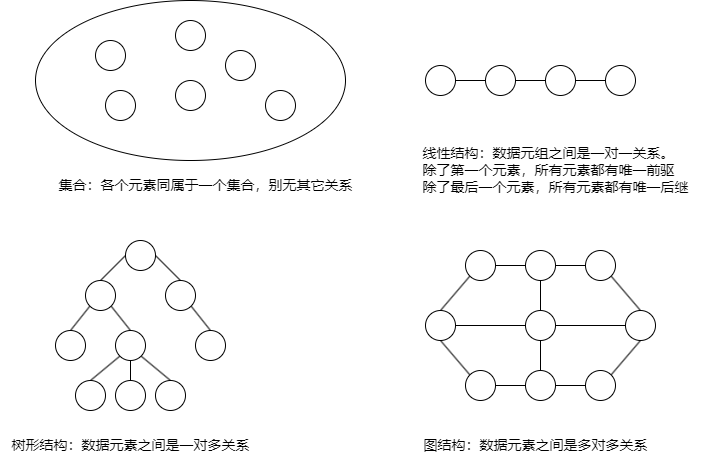
【1】、逻辑结构
【2】、数据的运算
结合逻辑结构,实际需求来定义基本运算。
【3】、存储结构
如何用计算机实现这种数据结构。
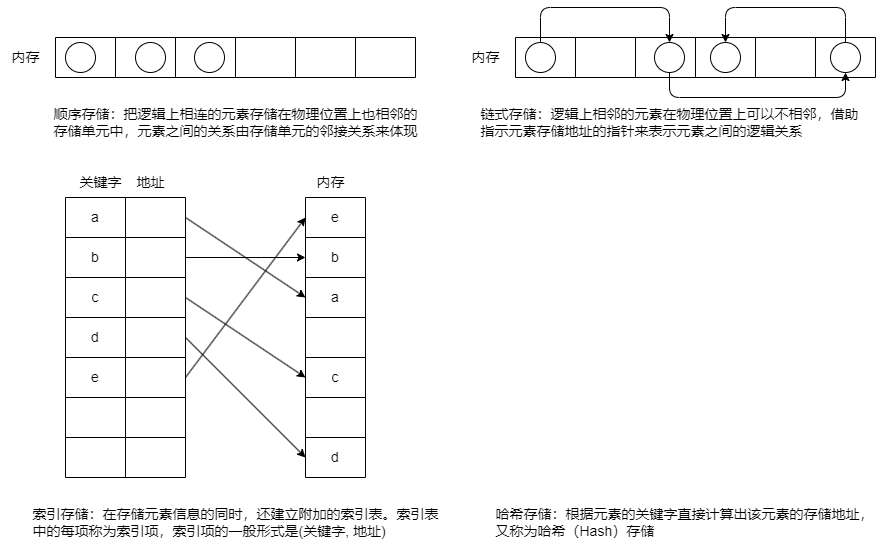
若采用顺序存储,则各个数据元素在物理上必须是连续的;若采用非顺序存储,则各个元素之间在物理上可以是离散的;
数据的存储结构会影响存储空间分配的方便程序,也会影响对数据运算的速度。
三、抽象数据类型
数据类型 是一个值的集合和定义在此集合上的一组操作的总称。数据类型分为 原子类型 和 结构类型。原子类型 是其值 不可再分 的数据类型。结构类型 是其值可以在 分解为若干分量 的的数据类型。
// 原子类型
int num = 0;
// 结构类型
struct Person
{
char name[30];
int age;
};
抽象数据类型(Abstract Data Type, ADT)是抽象数据组织及与之相关的操作。定义一个 ADT,就是在 “定义” 一种数据结构。确定了 ADT 的存储结构,才能 “实现” 这种数据结构。
ADT 抽象数据类型名
{
Data:
数据对象的定义;
数据元素之间逻辑关系的定义;
Operation:
操作1;
操作2;
...
操作n;
} ADT 抽象数据类型名;
四、什么是算法
算法(Algorithm)是对特定问题求解的一种描述,它是指令的有限序列,其中的每条指令表示一个或多个操作。一个算法必须具备以下特性:
- 有穷性:一个算法必须总在执行有穷步之后结束,且每一步都可在又穷时间内完成。
- 确定性:算法中每条指令必须有确切的含义,对于 相同的输入 只能得出 相同的输出。
- 可行性:算法中描述的操作都可以通过已经实现的 基本运算执行有限次 来实现。
- 输入:一个算法有 零个或多个输入,这些输入取自某个特定的对象的集合。
- 输出:一个算法有 一个或多个输出,这些输出是与输入有着某种特定关系的量。
一个好的算法,必须具备一些特征:
- 正确性:算法应能正确地求解问题。
- 可读性:算法应具备良好的可读性,以帮助人们理解。
- 健壮性:输入非法数据时,算法能适当做出反应或进行处理,而不会产生莫名其妙的输出结果。
- 高效率和低存储需求:高效率指的是时间复杂度低,低存储指的是空间复杂度低。
算法必须是有穷的,而程序可以是无穷的。
五、衡量算法的好坏
5.1、空间复杂度
空间复杂度 S(N) 是指根据算法写成的程序在执行过程中 占用存储单元的长度。这个长度往往与输入数据的规模有关。空间复杂度过高的算法可能导致使用的内存超限,造成程序非正常中断。
5.1、时间复杂度
时间复杂度 T(n) 指的是根据算法写成的程序在执行时 耗费时间的长度。这个长度往往也与输入数据的规模有关。时间复杂度过高的低效算法可能导致我们在有生之年都等不到运行结果。
算法的时间效率可以用依据该算法编写的程序在计算机上执行所消耗的是时间来衡量。一般,有两种度量方法:事后统计法 和 事前分析法。
在 C 语言中,我们可以使用 clock() 函数捕捉从程序开始运行到 clock() 被调用时所耗费的时间。这个时间单位是 clock_size(机器时钟每秒所走的时钟打点数),即 “时钟打点”。
#include <stdio.h>
#include <time.h>
#include <math.h>
// 多项式最大项数,即多项式阶数+1
#define MAXN 10
// 被测函数最大调用重复次数
#define MAXK 1e7
// clock_t是clock()函数返回的变量类型
clock_t start, stop;
// 记录被测函数运行时间,以秒为单位
double duration;
double f1(double A[], int N, double x);
double f2(double A[], int N, double x);
int main()
{
int i = 0;
// 存储多项式的系数
double A[MAXN];
for (int i = 0; i < MAXN; i++)
{
A[i] = (double)i;
}
// 不在测试范围内的准备工作写在clock()函数调用之前
start = clock();
for (int i = 0; i < MAXK; i++)
{
// 被测函数
f1(A, MAXN, 1.1);
}
stop = clock();
// 不在测试范围内的收尾工作写在clock()函数调用之后
duration = (double)(stop - start) / CLK_TCK;
printf("f1 duration = %6.2e\n", duration);
start = clock();
for (int i = 0; i < MAXK; i++)
{
// 被测函数
f2(A, MAXN, 1.1);
}
stop = clock();
duration = (double)(stop - start) / CLOCKS_PER_SEC;
printf("f1 duration = %6.2e\n", duration);
return 0;
}
double f1(double A[], int N, double x)
{
int i = 0;
double p = A[0];
for (i = 1; i < N; i++)
{
p += (A[i] * pow(x, i));
}
return p;
}
double f2(double A[], int N, double x)
{
int i = 0;
double p = A[N];
for (i = N; i > 0; i--)
{
p = A[i-1] + x * p;
}
return p;
}
一个算法的运行时间是指一个算法在计算机上运行所耗费的时间大致等于计算机执行一种简单的操作所需的时间与算法中进行简单操作次数乘积,即 \(算法运行时间 = 一个简单操作所需的时间 * 简单操作次数\),也就是算法中每条语句的执行时间之和。
每一条语句执行一次所需的时间,一般是随机器而异的。取决于机器的指令性能、速度以及编译的代码质量,是由机器本身软硬件环境决定的,它与算法无关。所以,我们可假设执行每条语句所需的时间均为 单位时间。此时,对算法的运行时间的讨论就可转换为讨论该算法中所有语句的执行次数,即频度之和。
为了方便比较不同算法的时间效率,我们仅比较它们的数量级。若有某个辅助函数 f(n),使得当 n 趋近于无穷大时,T(n)/f(n) 的极限值为不等于零的常数,则称 f(n) 是 T(n) 的同数量级函数,记作 T(n)=O(f(n)),称 O(f(n)) 为算法的渐进时间复杂度,简称时间复杂度。
一般情况下,不必计算所有操作的执行次数,而只考虑算法中基本操作执行的次数,它是问题规模 n 的某个函数,用 T(n) 表示。若两端算法分别由复杂度 \(T_{1} = O(f_{1}(n))\) 和 \(T_{2} = O(f_{2}(n))\),则 \(T_{1} + T_{2} = max(O(f_{1}(n)), O(f_{2}(n)))\),\(T_{1} * T_{2} = O(f_{1}(n) * f_{2}(n))\)。若 T(n) 是关于 n 的 k 阶多项式,那么只考虑最高次项的时间复杂度。一个 for 循环的时间复杂度等于循环次数乘以循环体代码的复杂度。
