
LongAdder是JDK1.8在java.util.concurrent.atomic包下新引入的 为了高并发下实现高性能统计的类。
1.背景
AtomicLong是在高并发下对单一变量进行CAS操作,从而保证其原子性。
public final long getAndAdd(long delta) {
return unsafe.getAndAddLong(this, valueOffset, delta);
}
在Unsafe类中,如果有多个线程进入,只有一个线程能成功CAS,其他线程都失败。失败的线程会重复进行下一轮的CAS,但是下一轮还是只有一个线程成功。
public final long getAndAddLong(Object o, long offset, long delta) {
long v;
do {
v= this.getLongVolatile(o,offset);
} while(!this.compareAndSwapLong(o,offset, v, v+delta));
return v;
}
即在高并发下,AtomicLong的性能会越来越差劲。
因此,引入了替代方案,LongAdder。
2.LongAdder
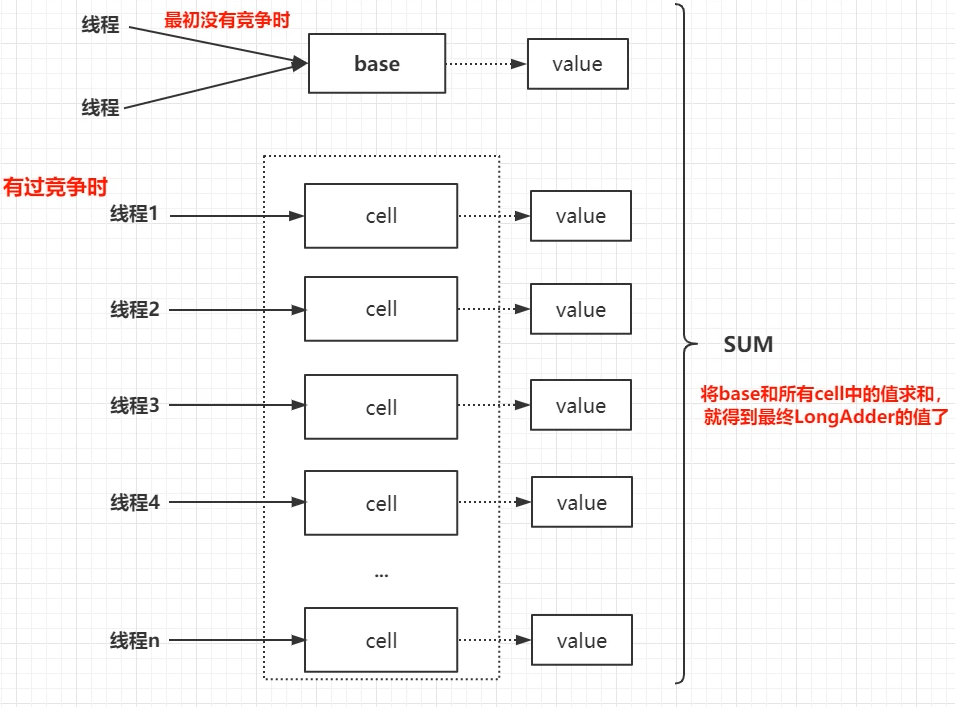
LongAdder是一种以空间换时间的解决方案。其内部维护了一个值base,和一个cell数组,当线程写base有冲突时,将其写入数组的一个cell中。将base和所有cell中的值求和就得到最终LongAdder的值了。
Method sum() (or, equivalently, longValue()) returns the current total combined across the variables maintaining the sum.
public long longValue() {
return sum();
}
public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
3.Striped64内部结构
LongAdder类继承了Striped64类,其中,class Striped64维护有有 Cell的内部类,Base,Cell数组等相关成员变量。
NCPU:表示当前计算机CPU数量,用于控制cells数组长度。因为一个CPU同一时间只能执行一个线程,如果cells数组长度 大于 CPU数量,并不能提高并发数,且造成空间的浪费。
cells:存放Cell的数组。
base:在没有发生过竞争时,数据会累加到base上。 或者,当cells扩容时,是需要将数据写到base中的。
cellsBusy:锁。0表示无锁状态,1表示其他线程已经持有锁。初始化cells,创建Cell,扩容cells都需要获取锁。
@sun.misc.Contended static final class Cell {
volatile long value;
Cell(long x) { value = x; }
final boolean cas(long cmp, long val) {
return UNSAFE.compareAndSwapLong(this, valueOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long valueOffset; // 当前value基于当前对象的内存偏移
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> ak = Cell.class;
valueOffset = UNSAFE.objectFieldOffset(ak.getDeclaredField("value"));
} catch (Exception e) {
throw new Error(e);
}
}
}
//表示当前计算机CPU数量,控制cells数组长度
static final int NCPU = Runtime.getRuntime().availableProcessors();
transient volatile Cell[] cells;
transient volatile long base; //在没有发生过竞争时,数据会累加到base上, 或者 当cells扩容时,需要将数据写到base中
transient volatile int cellsBusy; // 初始化cells或者扩容cells都需要获取锁,0表示无锁状态,1表示其他线程已经持有锁
4.LongAdder的add方法解析
add(long x):加上给定的x。
1.一开始只加给base,那么此时cells一定没有初始化,此时只会casBase,成功则返回。
2.casBase失败,意味着多线程写base发生竞争,进入longAccumulate(x, null, uncontended = true)重试或者初始化cells。
3.如果cells已经初始化过了,但是,当前线程对应下标的cell为空,需要创建。进入longAccumulate(x, null, uncontended = true)创建对应cell。
4.如果cells已经初始化过了,同时,当前线程对应的cell 不为空,cas给当前cell赋值,成功则返回。失败,意味着当前线程对应的cell 有竞争,进入longAccumulate(x, null, uncontended = false) 重试或者扩容cells。
public void add(long x) {
//as 表示cells引用
//b 表示获取的base值
//v 表示 期望值
//m 表示 cells 数组的长度
//a 表示当前线程命中的cell单元格
Cell[] as; long b, v; int m; Cell a;
//条件一:true->表示cells已经初始化过了,当前线程应该将数据写入到对应的cell中
// false->表示cells未初始化,当前所有线程应该将数据写到base中
//条件二:false->表示当前线程cas替换数据成功,
// true->表示发生竞争了,可能需要重试 或者 扩容
if ((as = cells) != null || !casBase(b = base, b + x)) {
//什么时候会进来?
//1.true->表示cells已经初始化过了,当前线程应该将数据写入到对应的cell中
//2.true->表示发生竞争了,可能需要重试 或者 扩容
boolean uncontended = true; //true -> 未竞争 false->发生竞争
//条件一:true->说明 cells 未初始化,也就是多线程写base发生竞争了
// false->说明 cells 已经初始化了,当前线程应该是 找自己的cell 写值
//条件二:getProbe() 获取当前线程的hash值 m表示cells长度-1 cells长度 一定是2的次方数 15= b1111
// true-> 说明当前线程对应下标的cell为空,需要创建 longAccumulate 支持
// false-> 说明当前线程对应的cell 不为空,说明 下一步想要将x值 添加到cell中。
//条件三:true->表示cas失败,意味着当前线程对应的cell 有竞争
// false->表示cas成功
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
//都有哪些情况会调用?
//1.true->说明 cells 未初始化,也就是多线程写base发生竞争了[重试|初始化cells]
//2.true-> 说明当前线程对应下标的cell为空,需要创建 longAccumulate 支持
//3.true->表示cas失败,意味着当前线程对应的cell 有竞争[重试|扩容]
longAccumulate(x, null, uncontended);
}
}
5.Striped64的longAccumulate方法解析
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended)
根据LongAdder的add方法可知,参数x是add函数的传入参数,即要增加的数;
LongBinaryOperator是一个接口可扩展,重写applyAsLong方法用于处理cell中值与参数x的关系,此处传null;
wasUncontended只有在 【cells已经初始化过了,同时,当前线程对应的cell 不为空,cas给当前cell赋值,竞争修改失败】的情况下为false,其他为true。
第一种情况:写base发生竞争,此时cells没有初始化,所以才会写到base,不走CASE1;
走Case2,判断有没有锁,没有锁的话,尝试加锁,成功加锁后执行初始化cells的逻辑。如果没有拿到锁,表示其它线程正在初始化cells,所以当前线程将值累加到base。
第二种情况:当前线程对应下标的cell为空,满足CASE1,到达CASE1.1中,创建一个Cell,加锁,如果成功,对应的位置其他线程没有设置过cell,将创建的cell插入相应位置。
第三种情况:当前线程对应下标的cell已经创建成功,但写入cell时发生竞争,到达CASE1.2,wasUncontended = true,把发生竞争线程的hash值rehash。
重置后走若CASE1.1,CASE1.2均不满足,到达CASE1.3【当前线程rehash过hash值,然后新命中的cell不为空】重试cas赋值+x一次,成功则退出。失败,扩容意向设置成true,rehash当前线程的hash值,再到1.3重试,还失败走CASE1.6扩容。
注意:CASE1.4要求cells数组长度不能超过cpu数量,因为一个CPU同一时间只能执行一个线程,如果cells数组长度 大于 CPU数量,并不能提高并发数,且造成空间的浪费。
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
//h 表示线程hash值
int h;
//条件成立:说明当前线程 还未分配hash值; getProbe()获取当前线程的Hash值
if ((h = getProbe()) == 0) {
//给当前线程分配hash值
ThreadLocalRandom.current(); // force initialization
//取出当前线程的hash值 赋值给h
h = getProbe();
//为什么? 因为默认情况下 当前线程hash为0, 肯定是写入到了 cells[0] 位置。 不把它当做一次真正的竞争
wasUncontended = true;
}
//表示扩容意向 false 一定不会扩容,true 可能会扩容。
boolean collide = false; // True if last slot nonempty
//自旋
for (;;) {
//as 表示cells引用
//a 表示当前线程命中的cell
//n 表示cells数组长度
//v 表示 期望值
Cell[] as; Cell a; int n; long v;
//CASE1: 表示cells已经初始化了,当前线程应该将数据写入到对应的cell中
if ((as = cells) != null && (n = as.length) > 0) {
// 以下两种情况会进入Case1:
//2.true-> 说明当前线程对应下标的cell为空,需要创建 longAccumulate 支持
//3.true->表示cas失败,意味着当前线程对应的cell 有竞争[重试|扩容]
//CASE1.1:true->表示当前线程对应的下标位置的cell为null,需要创建new Cell
if ((a = as[(n - 1) & h]) == null) {
//true->表示当前锁 未被占用 false->表示锁被占用
if (cellsBusy == 0) { // Try to attach new Cell
//拿当前的x创建Cell
Cell r = new Cell(x); // Optimistically create
//条件一:true->表示当前锁 未被占用 false->表示锁被占用
//条件二:true->表示当前线程获取锁成功 false->当前线程获取锁失败..
if (cellsBusy == 0 && casCellsBusy()) {
//是否创建成功 标记
boolean created = false;
try { // Recheck under lock
//rs 表示当前cells 引用
//m 表示cells长度
//j 表示当前线程命中的下标
Cell[] rs; int m, j;
//条件一 条件二 恒成立
//rs[j = (m - 1) & h] == null 为了防止其它线程初始化过该位置,然后当前线程再次初始化该位置
//导致丢失数据
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null) {
rs[j] = r;
created = true;
}
} finally {
cellsBusy = 0;
}
if (created)
break;
continue; // Slot is now non-empty
}
}
//扩容意向 强制改为了false
collide = false;
}
// CASE1.2:
// wasUncontended:只有cells初始化之后,并且当前线程 竞争修改失败,才会是false
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
//CASE 1.3:当前线程rehash过hash值,然后新命中的cell不为空
//true -> 写成功,退出循环
//false -> 表示rehash之后命中的新的cell 也有竞争 重试1次 再重试1次
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
//CASE 1.4:
//条件一:n >= NCPU true->扩容意向 改为false,表示不扩容了 false-> 说明cells数组还可以扩容
//条件二:cells != as true->其它线程已经扩容过了,当前线程rehash之后重试即可
else if (n >= NCPU || cells != as)
//扩容意向 改为false,表示不扩容了
collide = false; // At max size or stale
//CASE 1.5:
//!collide = true 设置扩容意向 为true 但是不一定真的发生扩容
else if (!collide)
collide = true;
//CASE 1.6:真正扩容的逻辑
//条件一:cellsBusy == 0 true->表示当前无锁状态,当前线程可以去竞争这把锁
//条件二:casCellsBusy true->表示当前线程 获取锁 成功,可以执行扩容逻辑
// false->表示当前时刻有其它线程在做扩容相关的操作。
else if (cellsBusy == 0 && casCellsBusy()) {
try {
//cells == as
if (cells == as) { // Expand table unless stale
Cell[] rs = new Cell[n << 1];
for (int i = 0; i < n; ++i)
rs[i] = as[i];
cells = rs;
}
} finally {
//释放锁
cellsBusy = 0;
}
collide = false;
continue; // Retry with expanded table
}
//重置当前线程Hash值
h = advanceProbe(h);
}
//CASE2:前置条件cells还未初始化 as 为null
//条件一:true 表示当前未加锁
//条件二:cells == as?因为其它线程可能会在你给as赋值之后修改了 cells
//条件三:true 表示获取锁成功 会把cellsBusy = 1,false 表示其它线程正在持有这把锁
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
boolean init = false;
try { // Initialize table
//cells == as? 防止其它线程已经初始化了,当前线程再次初始化 导致丢失数据
if (cells == as) {
Cell[] rs = new Cell[2];
rs[h & 1] = new Cell(x);
cells = rs;
init = true;
}
} finally {
cellsBusy = 0;
}
if (init)
break;
}
//CASE3:
//1.当前cellsBusy加锁状态,表示其它线程正在初始化cells,所以当前线程将值累加到base
//2.cells被其它线程初始化后,当前线程需要将数据累加到base
else if (casBase(v = base, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break; // Fall back on using base
}
}
6.总结
官方文档是这样介绍的
This class is usually preferable to AtomicLong when multiple threads update a common sum that is used for purposes such as collecting statistics, not for fine-grained synchronization control. Under low update contention, the two classes have similar characteristics. But under high contention, expected throughput of this class is significantly higher, at the expense of higher space consumption.
LongAdder在多个线程更新一个用于收集统计信息的而不是追求同步的公共和的情况下,是优于AtomicLong类的。在并发度小,低竞争情况下,两个类具有相似的性能。但是在高争用情况下,LongAdder的预期吞吐量要高得多,代价是更高的空间消耗。
最后,我们再来看一下sum方法的注释
Returns the current sum. The returned value is NOT an atomic snapshot; invocation in the absence of concurrent updates returns an accurate result, but concurrent updates that occur while the sum is being calculated might not be incorporated.
sum方法返回值只是一个接近值,并不是一个准确值。它在计算总和时,并发的更新并不会被合并在内。
总结:
- LongAdder是一种以空间换时间的解决方案,其在高并发,竞争大的情况下性能更优。
- 但是,sum方法拿到的只是接近值,追求最终一致性。如果业务场景追求高精度,高准确性,用AtomicLong。

