

Django-model-查询API-双下划线查询
1.什么是ORM
ORM,即Object-Relational Mapping(对象关系映射),它的作用是在关系型数据库和业务实体对象之间作一个映射,这样,我们在具体的操作业务对象的时候,就不需要再去和复杂的SQL语句打交道,只需简单的操作对象的属性和方法。
2.ORM的优缺点是什么
优点:摆脱复杂的SQL操作,适应快速开发;让数据结构变得简洁;数据库迁移成本更低(如从mysql->oracle)
缺点:性能较差、不适用于大型应用;复杂的SQL操作还需通过SQL语句实现
Django
创建表
实例:我们来假定下面概念,字段和关系
书籍模型:图书编号,图书名称,出版日期,图书价格,作者,出版社
class Book(models.Model):#需要继承models.Model类
nid = models.AutoField(primary_key=True)#主键自增,必须是索引
title = models.CharField( max_length=32)#书名最大32个字符
publishDate=models.DateField()#日期
price=models.DecimalField(max_digits=5,decimal_places=2)#价格一共5位包含两位小数
zuozhe=models.CharField(max_lenght=32)#作者姓名
chubanshe=models.CharField(max_lenght=32)#出版社姓名
如何将modles中的Book类转化为对应的库
termiral中执行
python manage.py makemigrations
执行命令后django的orm会自动根据Book类创建一个0001_initial.py的文件,这个是创建库的中间转换阶段
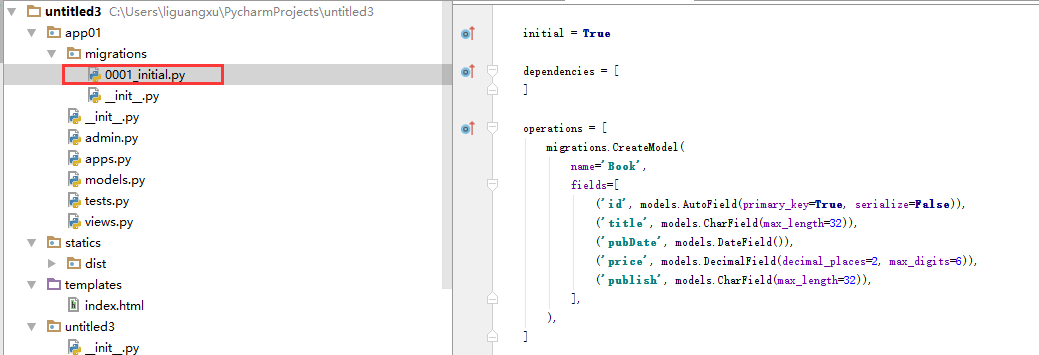
然后执行
#生成数据库 python manage.py migrate
之后怎么看我们生成的数据库呢~
拖动
到
我们可以看到db下面有错误,点击
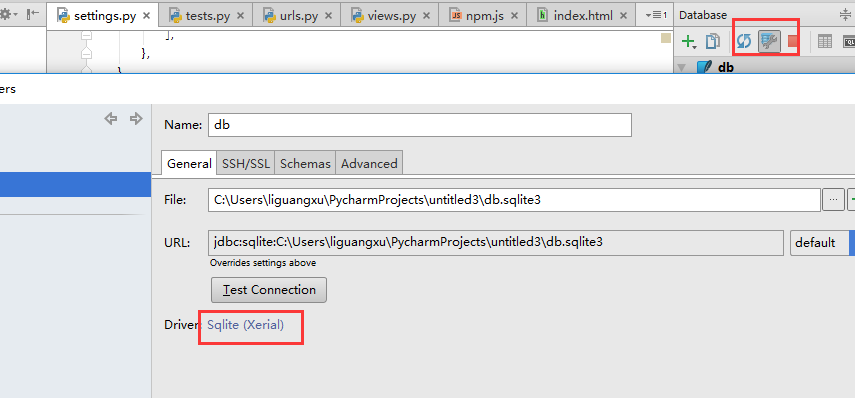

之后就可以看到我们生成的库了。
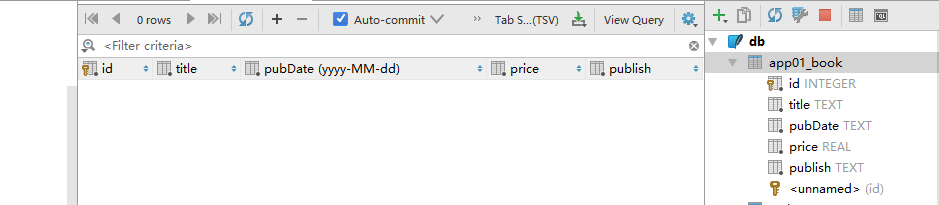 其中app01_book便是我们创建的表,其他的表是django自带的表。
其中app01_book便是我们创建的表,其他的表是django自带的表。
注意:有些版本的django这里需要添加上你自己项目的名称,没有添加的话无法生成库。
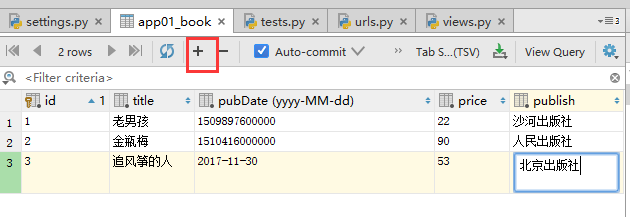
表记录操作
之后我们添加几条记录
我们在视图函数中拿到库中的每条记录
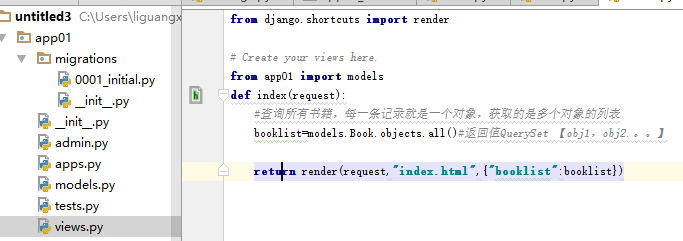
然后在模板层的index.html中
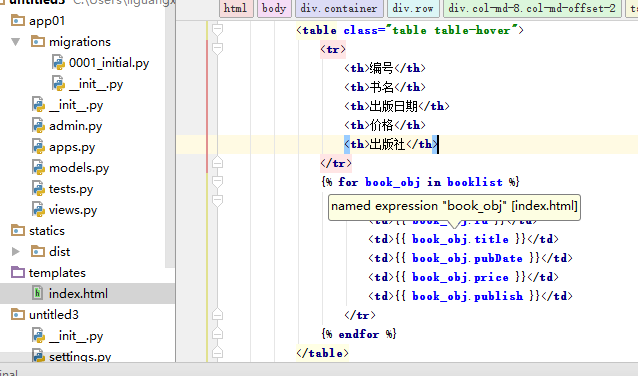
启动项目打开127.0.0.1/8000/index
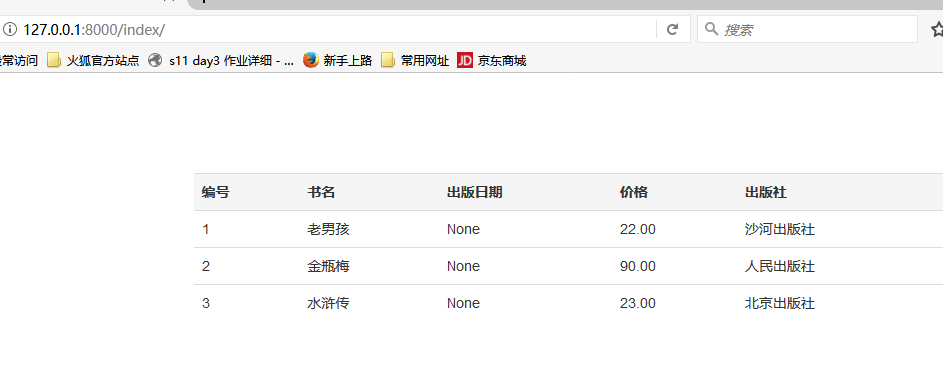
我们想要的效果出来了~~~~
查询数据库并在前端显示的功能已经出来了,
下面我们进行前端页面往数据库中添加记录。
首先在index.html中添加个添加按钮
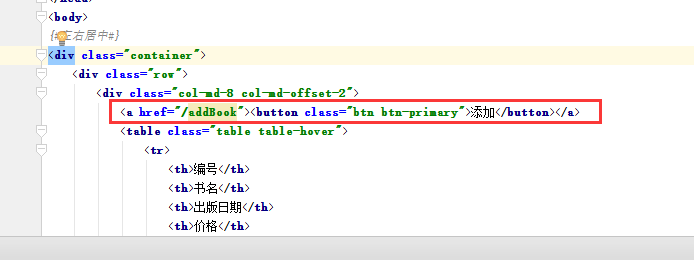
由于button没有提交功能,所以嵌套a标签,路径为/addBook
在url中添加视图函数映射的url
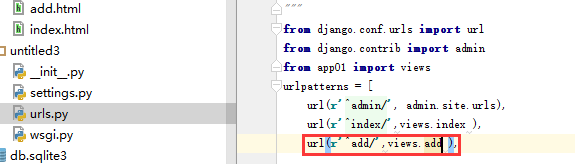
在views.py中添加视图函数

我们希望在点击添加记录的时候会返回一个新的页面来接受用户要插入的记录信息。
创建add.html
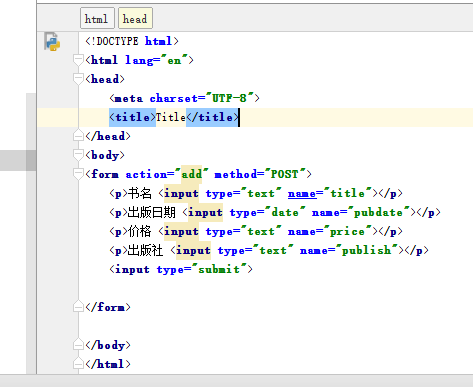
我们点击添加按钮提交之后,在服务端可以接收到根据
print(request.POST)得到
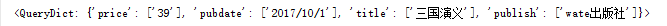
添加记录到数据库的方法
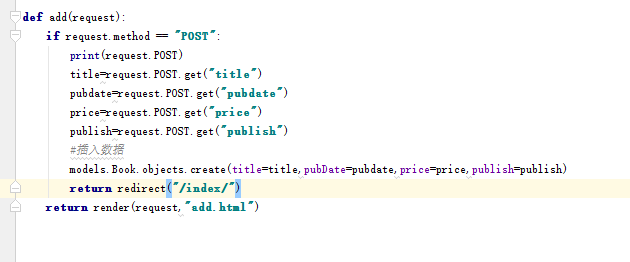
将用户传递过来的值赋给变量,之后用create方法进行字段对应,创建记录,然后返回index路径
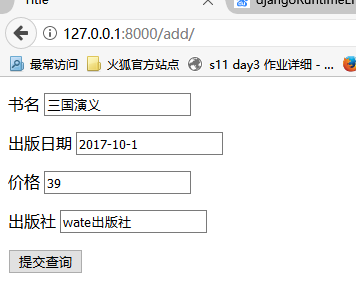
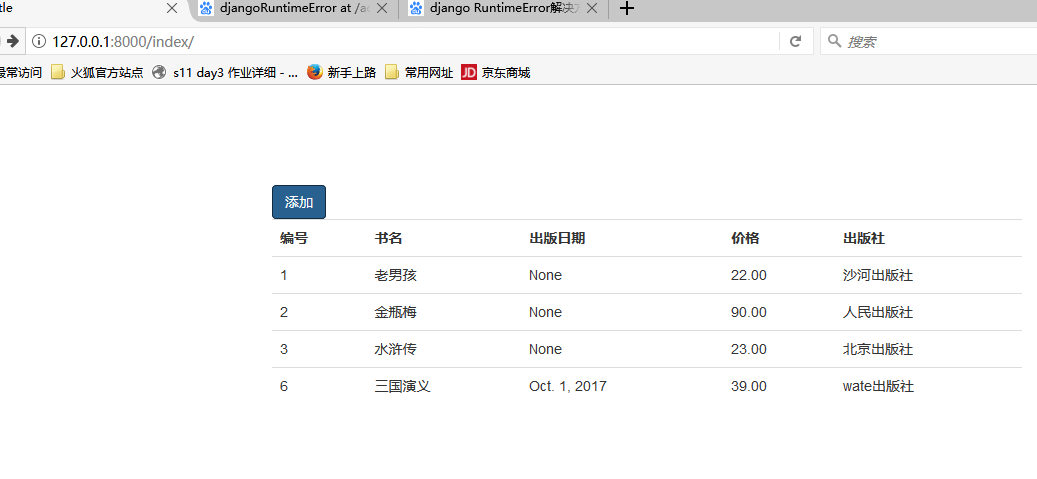
这样添加的效果就出来了。
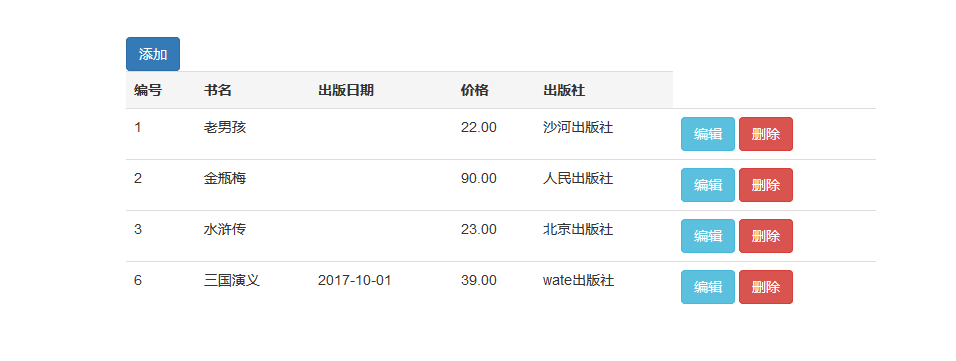
然后进行编辑和删除,现在index.html添加按钮

为了知道要删除的是哪条记录,我们在路径中传给服务端要删除记录的id

还是通过url中分组的方式
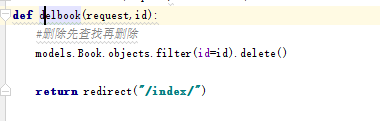
视图中用下面这句话进行过滤记录删除
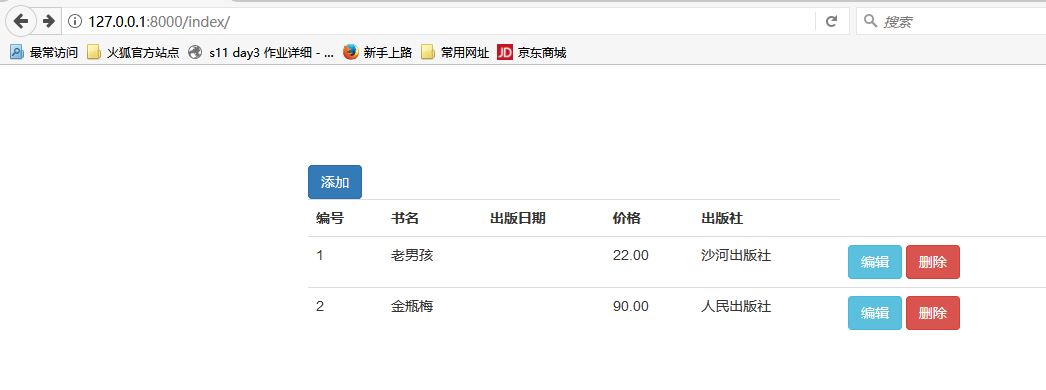
删除成功!!
编辑表
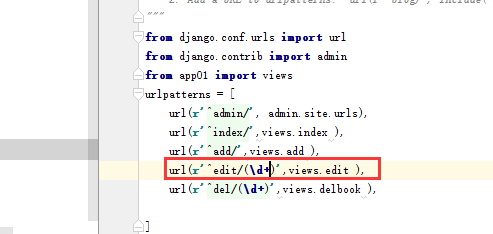
点击编辑时,跳转路径edit,传回id



添加表记录
方式一
publish_obj=Book(name="人民出版社",city="京",email="renMin@163.com")
publish_obj.save() # 将数据保存到数据库
方式二
publish_obj=Publish.objects.create(name="人民出版社",city="北京",email="renMin@163.com")
查询表记录
<1> all(): 查询所有结果queryset类型【obj1,obj2,obj3...】 book_list=models.Book.objects.all()
1、可以用索引取值 print(book_list[2].title) 2、也可以通过遍历来取 for book_obj in book_list: print(book_obj.title)
<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 queryset类型【obj1,obj2,obj3...】
#查询价格为134,的数学书 book_list=models.Book.objects.filter(price=134,title='数学书') #查询价格为134的,或者数学书 from django.db.models import Q book_list=models.Book.objects.filter(Q(price=134)|Q(title='数学书'))
<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,
如果符合筛选条件的对象超过一个或者没有都会抛出错误。
#返回值为一个models对象,一般用作主键,结果值多或无匹配都会报错 a = models.Book.objects.get(title="数学书")
<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象
book_list=models.Book.object.exclude(price=134) #取匹配记录的反
<5> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列 model的实例化对象,而是一个可迭代的字典序列
#queryset类型 ret=models.Book.objects.all().values("title") [{'title':'语文书},{'title':'数学书},{'title':'英语书},{'title':'物理书},] #queryset类型 ret=models.Book.objects.all().values("title",'price') [{'title':'语文书','price':Decimal('134.00')},{'title':'数学书'',price':Decimal('134.00')},{'title':'英语书','price':Decimal('134.00')},{'title':'物理书','price':Decimal('134.00')}]
<6> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列
ret = models.Book.objects.all().values_list("title") print(ret) [('语文书'),('数学书'),('英语书'),('物理书')]
<7> order_by(*field): 对查询结果排序
#排序 book_list=models.Book.objects.all().order_by("-price")
<8> reverse(): 对查询结果反向排序 <9> distinct(): 从返回结果中剔除重复纪录 <10> count(): 返回数据库中匹配查询(QuerySet)的对象数量。 <11> first(): 返回第一条记录
book_obj=models.Book.objects.all().first()
<12> last(): 返回最后一条记录 <13> exists(): 如果QuerySet包含数据,就返回True,否则返回False
#查询出记录并只取第一条 ret=models.Book.objects.all().exists() #判断记录是否存在 ret=models.Book.objects.all() if ret: print('ok') else: print('no')
在setting中设置logging进行sql查看


DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'books', #你的数据库名称 'USER': 'root', #你的数据库用户名 'PASSWORD': '', #你的数据库密码 'HOST': '', #你的数据库主机,留空默认为localhost 'PORT': '3306', #你的数据库端口 } }
完美的双下划线
django中借助双下划线进行模糊查询
#查询id>10的个数 (小于lt) book_list=models.Book.objects.filter(id__gt=10) print(book_list.count()) #以语文开头的记录 book_list =models.Book.objects.filter(title__startswith="语文") print(book_list[0].title) #查询包含语文的记录 book_list =models.Book.objects.filter(title__contains="语文") print(book_list[0].title) #查询包含语文的记录带有i开头的,是不区分大小写 book_list =models.Book.objects.filter(title__icontains="语文") print(book_list[0].title) models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据 models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in models.Tb1.objects.filter(name__contains="ven") models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感 models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and #startswith,istartswith, endswith, iendswith
