.NET备份博客园随笔分类文章
之前用.NET做网页采集实现采用正则表达式去匹配解析,比较繁琐,花费时间较多,若是Html复杂的话真是欲哭无泪。
很早就听过包HtmlAgilityPack,其是在.NET下用XPath来解析的HTML的一个类库(包)。但是一直没时间尝试,简单了解了下HtmlAgilityPack的API后,发现真是HTML解析利器,于是花些时间做一个例子记录下。
本次是以下载博客园随笔分类文章为例,采用两部分实现,第一部分是将采集到的文章放到集合变量中,第二部分是通过操作集合变量将文章下载到本地,
这样做效率较低,因为可以直接边采集文章边下载。暂时没有考虑效率问题,仅仅只是实现功能。下面简单阐述下。
获取随笔分类
根据输入的博客名取得对应的随笔分类。


/// <summary> /// 获取博客分类 /// </summary> /// <param name=" uname"></param> /// <returns></returns> private static List< BlogType> GettBlogTypeList(string uname) { string url = "http://www.cnblogs.com/" + uname + "/mvc/blog/sidecolumn.aspx?blogApp=" + uname; string htmlStr = CommonHelper .GetRequestStr(url); HtmlDocument doc = new HtmlDocument(); doc.LoadHtml(htmlStr); var nodes = doc.DocumentNode.SelectNodes("//div[@id='sidebar_postcategory']//a"); //随笔分类 if (nodes == null || nodes.Count <= 0) return null ; List<BlogType > list = new List< BlogType>(); for (int i = 0; i < nodes.Count; i++) { var aUrl = nodes[i].Attributes["href" ].Value; var name = nodes[i].InnerText; list.Add( new BlogType () { BlogTypeUrl = aUrl, BlogTypeName = name.Contains( "(") ? name.Split('(')[0] : name,BlogTypeNameShow=name }); } return list; } public class BlogType { public string BlogTypeUrl { get; set; } public string BlogTypeName { get; set; } public string BlogTypeNameShow { get; set; } }
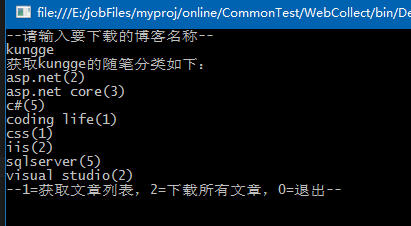
如获取到的随笔分类如下:
采集分类的文章
采用两步实现,第一步获取只包含标题和url的文章,第二步再获取文章内容。
/// <summary> /// 根据分类获取博客 /// </summary> /// <param name=" blogTypes"></param> /// <param name=" useTime"></param> /// <returns></returns> public static Dictionary< BlogType,List <BlogInfo>> GetBlogsByType( List<BlogType > blogTypes,out long useTime) { Stopwatch sw = new Stopwatch(); sw.Start(); Dictionary<BlogType , List< BlogInfo>> dic = new Dictionary< BlogType, List <BlogInfo>>(); foreach (var blogType in blogTypes) { List<BlogInfo > list = new List< BlogInfo>(); HtmlDocument doc = new HtmlDocument(); doc.LoadHtml( CommonHelper.GetRequestStr(blogType.BlogTypeUrl)); var typeNameNode = doc.DocumentNode.SelectSingleNode("//div[@class='entrylist']/h1"); string typeName = typeNameNode.InnerText; var listPosttitleNodes = doc.DocumentNode.SelectNodes("//div[@class='entrylistPosttitle']/a"); if (listPosttitleNodes != null && listPosttitleNodes.Count > 0) { for (int i = 0; i < listPosttitleNodes.Count; i++) { Console.WriteLine("正在爬取文章【{0}】..." , listPosttitleNodes[i].InnerText); list.Add( new BlogInfo () { BlogUrl = listPosttitleNodes[i].Attributes[ "href"].Value, BlogTitle = listPosttitleNodes[i].InnerText, BlogTypeName = typeName }); } } dic.Add(blogType,list); } sw.Stop(); useTime = sw.ElapsedMilliseconds; return dic; } /// <summary> /// 获取详细的博客信息 /// </summary> /// <param name=" dic"></param> /// <param name=" useTime"></param> /// <returns></returns> public static Dictionary< BlogType, List <BlogInfo>> GetBlogDetail( Dictionary<BlogType , List<BlogInfo >> dic, out long useTime) { Stopwatch sw = new Stopwatch(); sw.Start(); HtmlDocument doc = new HtmlDocument(); for(int k=0;k<dic.Keys.Count;k++) { var blogType = dic.Keys.ElementAt(k); var list = dic[blogType]; for (int i = 0; i < list.Count; i++) { Console.WriteLine("正在获取文章【{0}】内容..." , list[i].BlogTitle); doc.LoadHtml( CommonHelper.GetRequestStr(list[i].BlogUrl)); var bodyNode = doc.DocumentNode.SelectSingleNode("//div[@id='cnblogs_post_body']"); var dateNode = doc.DocumentNode.SelectSingleNode("//span[@id='post-date']"); var userNode = doc.DocumentNode.SelectSingleNode("//div[@class='postDesc']/a[1]"); list[i].BlogContent = bodyNode == null ? "内容获取失败" : bodyNode.InnerHtml; list[i].BlogPostTime = dateNode == null ? "发布时间获取失败" : dateNode.InnerText; list[i].BlogName = userNode == null ? "用户获取失败" : userNode.InnerText; } dic[blogType] = list; } sw.Stop(); useTime = sw.ElapsedMilliseconds; return dic; } public class BlogInfo { public string BlogUrl { get; set; } public string BlogName { get; set; } public string BlogTitle { get; set; } public string BlogContent { get; set; } public string BlogTypeName { get; set; } public string BlogPostTime { get; set; } }
下载到本地
根据上面采集到的文章再一步步下载到本地,期间分两步,第一步下载图片,第二步下载文章内容。
/// <summary> /// 下载 /// </summary> /// <param name=" dic"></param> /// <param name=" uname"></param> /// <param name=" useTime"></param> /// <returns></returns> public static string DowanloadBlog( Dictionary<BlogType , List< BlogInfo>> dic, string uname,out long useTime) { Stopwatch sw = new Stopwatch(); sw.Start(); int countFlag = 0; for (int i = 0; i < dic.Keys.Count; i++) { var blogType = dic.Keys.ElementAt(i); var blogList = dic[blogType]; var dicPath = AppDomain .CurrentDomain.BaseDirectory +"BlogFiles\\" + uname + "\\" + blogType.BlogTypeName; Console.WriteLine("<<开始处理分类【{0}】<<" , blogType.BlogTypeName); FileHelper.CreatePath(dicPath); var blogModel = new BlogInfo(); for (int j = 0; j < blogList.Count; j++) { countFlag++; try { Console.WriteLine("~~~~开始处理文章{0}【{1}】~~~~" , countFlag,blogModel.BlogTitle); blogModel = blogList[j]; var filePath = dicPath + "\\" + FileHelper.FilterInvalidChar(blogModel.BlogTitle, "_") + ".html" ; HtmlDocument doc = new HtmlDocument(); doc.DocumentNode.InnerHtml = blogModel.BlogContent; //处理图片 Console.WriteLine("~~开始处理图片" ); var imgPath = dicPath + "\\images" ; FileHelper.CreatePath(imgPath); SaveImage(doc, imgPath); Console.WriteLine("~~处理图片完成" ); //去掉a标签 var aNodes = doc.DocumentNode.SelectNodes("//a"); if (aNodes != null && aNodes.Count > 0) { for (int a = 0; a < aNodes.Count; a++) { if (aNodes[a].Attributes["href" ] != null && aNodes[a].Attributes[ "href"].Value != "#" ) { aNodes[a].Attributes[ "href"].Value = "javascript:void()" ; } } } doc.DocumentNode.InnerHtml = "<div id='div_head'>" + uname + " " + blogType.BlogTypeName + "</div><div id='div_title'>" + blogModel.BlogTitle + "<div><div id='div_body'>" + doc.DocumentNode.InnerHtml + "</div>"; doc.Save(filePath, Encoding.UTF8); Console.WriteLine("~~~~处理文章{0}【{1}】完毕~~~~" ,countFlag,blogModel.BlogTitle); } catch (Exception ex) { string errorMsg = DateTime .Now.ToString("yyyyMMdd HH:mm:ss") + "\r\n" + "url=" + blogModel.BlogUrl + "\r\n" + "title=" + blogModel.BlogTitle + "\r\n" + "errorMsg=" + ex.Message + "\r\n" + "stackTrace=" + ex.StackTrace + "\r\n\r\n\r\n"; Console.WriteLine("error>>处理文章【{0}】出现错误,开始记录错误信息~~" , blogModel.BlogTitle); FileHelper.SaveTxtFile(dicPath, "errorLog.txt" , errorMsg, false); Console.WriteLine("error>>处理文章【{0}】出现错误,记录错误信息完成~~" , blogModel.BlogTitle); } } Console.WriteLine("<<处理分类【{0}】完成<<" , blogType.BlogTypeName); } sw.Start(); useTime = sw.ElapsedMilliseconds; return AppDomain .CurrentDomain.BaseDirectory + "BlogFiles\\" + uname; } /// <summary> /// 保存图片 /// </summary> /// <param name=" doc"></param> /// <param name=" filePath"></param> public static void SaveImage( HtmlDocument doc, string filePath) { var imgNodes = doc.DocumentNode.SelectNodes("//img"); if (imgNodes != null && imgNodes.Count > 0) { for (int i = 0; i < imgNodes.Count; i++) { try { string src = imgNodes[i].Attributes["src" ].Value; string fileName = "" ; if (src != null && src.Contains("/")) { fileName = src.Substring(src.LastIndexOf( "/") + 1); Console.WriteLine("~~开始下载图片【{0}】~~" , fileName); string imgPath = filePath + "\\" + fileName; imgNodes[i].Attributes[ "src"].Value = imgPath; byte[] imgByte = CommonHelper .GetRequestByteArr(src); if (imgByte != null ) { FileHelper.SaveImage(imgPath, imgByte); Console.WriteLine("~~下载图片【{0}】完成~~" , fileName); } else { Console.WriteLine("~~下载图片【{0}】失败~~" , fileName); } } } catch (Exception ex) { throw new Exception( "SaveImage_Error:" + ex.Message); } } } }
程序入口
主要代码如下
var types = GettBlogTypeList(uname); long time1 = 0; long time2 = 0; long timeDownload = 0; Console.WriteLine("正在爬取,请耐心等待..." ); var blogList = GetBlogsByType(types,out time1); var blogDetailList = GetBlogDetail(blogList,out time2); Console.WriteLine("爬取完毕,开始下载..." ); string filePath=DowanloadBlog(blogDetailList, uname,out timeDownload); Console.WriteLine("**处理完毕,爬取用时{0}ms,下载用时{1}ms,{2}" , time1+time2, timeDownload, filePath); handlerRight = false;
演示效果
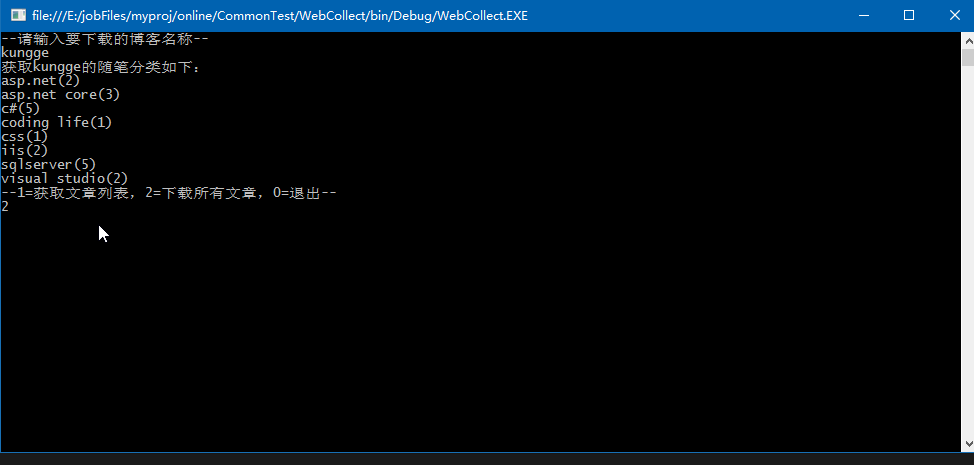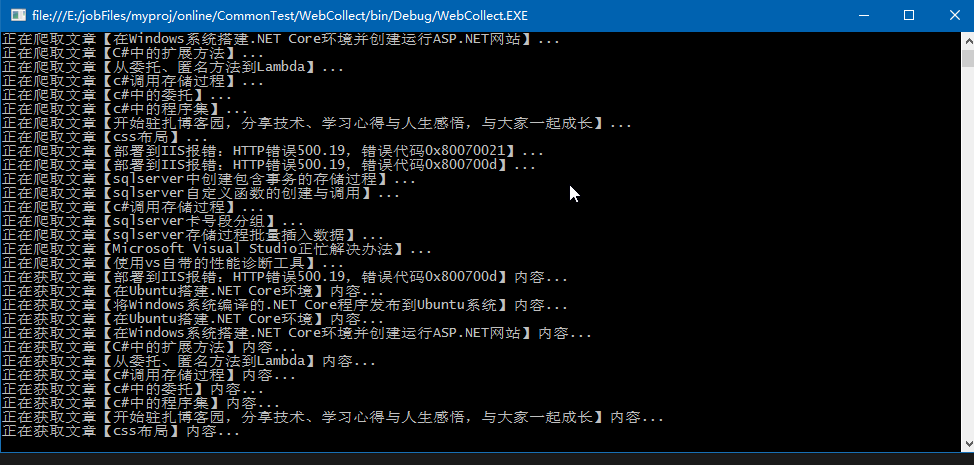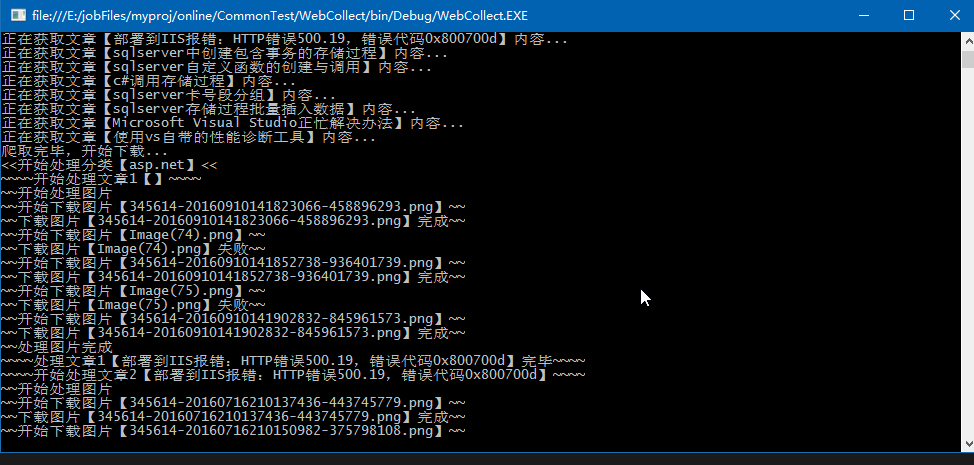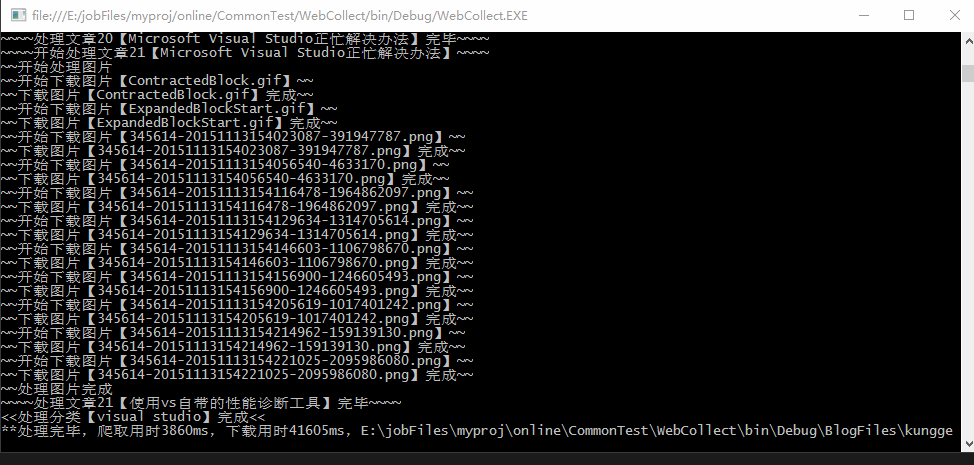
文件存储在项目bin目录下,一个用户一个文件夹
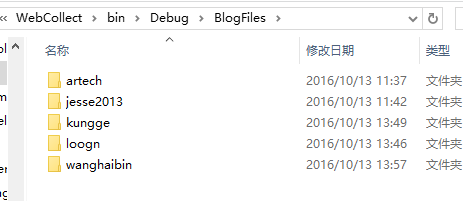
按随笔分类生成不同的文件夹
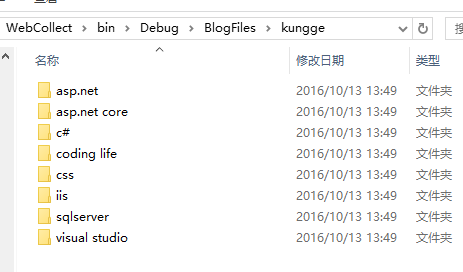
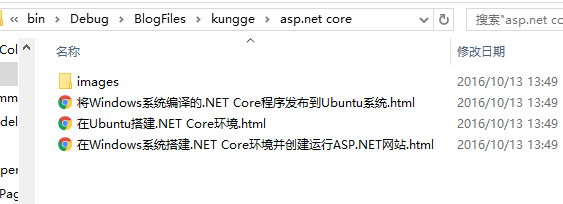
生成.html文件,一个分类的所有图片都存在该分类下的images下。
完整源码放在github下,https://github.com/kungge/CommonTest/tree/dev/WebCollect
欢迎指出程序bug,提出优化意见,(●'◡'●)
- 一步一个脚印,稳扎稳打,实事求是。
- 记录所学知识,记录自己的成长轨迹。
- 记录过程中,发现问题并解决问题。
- 感谢您的阅读!(●'◡'●),如果您觉得本文对您有帮助的话,麻烦点个推荐,欢迎转载,转载请带上原文链接,谢谢!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号