
主要内容:
l 客户端
¡ zookeeper客户端简介,C客户端
¡ 客户端连接参数说明
¡ 客户端CRUD
¡ 客户端监听
l 集群
¡ 集群架构说明
¡ 集群配置及参数说明
¡ 选举投票机制
¡ 主从复制机制
一、客户端API常规应用
zookeeper 提供了java与C两种语言的客户端。我们要学习的就是java客户端。引入最新的maven依赖:
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.5.5</version>
</dependency>
知识点:
1. 初始连接
2. 创建、查看节点
3. 监听节点
4. 设置节点权限
5. 第三方客户端ZkClient
初始连接:
常规的客户端类是 org.apache.zookeeper.ZooKeeper,实例化该类之后将会自动与集群建立连接。构造参数说明如下:
|
参数名称 |
类型 |
说明 |
|
connectString |
String |
连接串,包括ip+端口 ,集群模式下用逗号隔开 192.168.0.149:2181,192.168.0.150:2181 |
|
sessionTimeout |
int |
会话超时时间,该值不能超过服务端所设置的 minSessionTimeout 和maxSessionTimeout |
|
watcher |
Watcher |
会话监听器,服务端事件将会触该监听 |
|
sessionId |
long |
自定义会话ID |
|
sessionPasswd |
byte[] |
会话密码 |
|
canBeReadOnly |
boolean |
该连接是否为只读的 |
|
hostProvider |
HostProvider |
服务端地址提供者,指示客户端如何选择某个服务来调用,默认采用StaticHostProvider实现 |
2.创建、查看节点
创建节点
通过org.apache.zookeeper.ZooKeeper#create()即可创建节点,其参数说明如下:
|
参数名称 |
类型 |
说明 |
|
path |
String |
|
|
data |
byte[] |
|
|
acl |
List<ACL> |
|
|
createMode |
CreateMode |
|
|
cb
|
StringCallback |
|
|
ctx |
Object |
|
查看节点:
通过org.apache.zookeeper.ZooKeeper#getData()即可创建节点,其参数说明如下:
|
参数名称 |
类型 |
说明 |
|
path |
String |
|
|
watch |
boolean |
|
|
watcher |
Watcher |
|
|
cb |
DataCallback |
|
|
ctx |
Object |
|
查看子节点:
通过org.apache.zookeeper.ZooKeeper#getChildren()即可获取子节点,其参数说明如下:
|
参数名称 |
类型 |
说明 |
|
path |
String |
|
|
watch |
boolean |
|
|
watcher |
Watcher |
|
|
cb |
Children2Callback |
|
|
ctx |
Object |
|
3.监听节点
在getData() 与getChildren()两个方法中可分别设置监听数据变化和子节点变化。通过设置watch为true,当前事件触发时会调用zookeeper()构建函数中Watcher.process()方法。也可以添加watcher参数来实现自定义监听。一般采用后者。
注:所有的监听都是一次性的,如果要持续监听需要触发后在添加一次监听。
4.设置节点ACL权限
ACL包括结构为scheme:id:permission(有关ACL的介绍参照第一节课关于ACL的讲解)
客户端中由org.apache.zookeeper.data.ACL 类表示,类结构如下:
1. ACL
a. Id
i. scheme // 对应权限模式scheme
ii. id // 对应模式中的id值
b. perms // 对应权限位permission
关于权限位的表示方式:
每个权限位都是一个唯一数字,将其合时通过或运行生成一个全新的数字即可
@InterfaceAudience.Public
public interface Perms {
int READ = 1 << 0;
int WRITE = 1 << 1;
int CREATE = 1 << 2;
int DELETE = 1 << 3;
int ADMIN = 1 << 4;
int ALL = READ | WRITE | CREATE | DELETE | ADMIN;
}
5.第三方客户端ZkClient
zkClient 是在zookeeper客户端基础之上封装的,使用上更加友好。主要变化如下:
l 可以设置持久监听,或删除某个监听
l 可以插入JAVA对象,自动进行序列化和反序列化
l 简化了基本的增删改查操作。
二、Zookeeper集群
知识点:
1. 集群部署
2. 集群角色说明
3. 选举机制
4. 数据提交机制
5. 集群配置说明
zookeeper集群的目的是为了保证系统的性能承载更多的客户端连接设专门提供的机制。通过集群可以实现以下功能:
l 读写分离:提高承载,为更多的客户端提供连接,并保障性能。
l 主从自动切换:提高服务容错性,部分节点故障不会影响整个服务集群。
半数以上运行机制说明:
集群至少需要三台服务器,并且强烈建议使用奇数个服务器。因为zookeeper 通过判断大多数节点的存活来判断整个服务是否可用。比如3个节点,挂掉了2个表示整个集群挂掉,而用偶数4个,挂掉了2个也表示其并不是大部分存活,因此也会挂掉。
1. 集群部署
配置语法:
server.<节点ID>=<ip>:<数据同步端口>:<选举端口>
l 节点ID:服务id手动指定1至125之间的数字,并写到对应服务节点的 {dataDir}/myid 文件中。
l IP地址:节点的远程IP地址,可以相同。但生产环境就不能这么做了,因为在同一台机器就无法达到容错的目的。所以这种称作为伪集群。
l 数据同步端口:主从同时数据复制端口,(做伪集群时端口号不能重复)。
l 远举端口:主从节点选举端口,(做伪集群时端口号不能重复)。
配置文件示例:
tickTime=2000
dataDir=/var/lib/zookeeper/
clientPort=2181
initLimit=5
syncLimit=2
#以下为集群配置,必须配置在所有节点的zoo.cfg文件中
server.1=zoo1:2888:3888
server.2=zoo2:2888:3888
server.3=zoo3:2888:3888
集群配置流程:
1. 分别创建3个data目录用于存储各节点数据
mkdir data
mkdir data/1
mkdir data/3
mkdir data/3
编写myid文件
echo 1 > data/1/myid
echo 3 > data/3/myid
echo 2 > data/2/myid
3、编写配置文件
conf/zoo1.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=data/1
clientPort=2181
#集群配置
server.1=127.0.0.1:2887:3887
server.2=127.0.0.1:2888:3888
server.3=127.0.0.1:2889:3889
conf/zoo2.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=data/2
clientPort=2182
#集群配置
server.1=127.0.0.1:2887:3887
server.2=127.0.0.1:2888:3888
server.3=127.0.0.1:2889:3889
conf/zoo3.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=data/3
clientPort=2183
#集群配置
server.1=127.0.0.1:2887:3887
server.2=127.0.0.1:2888:3888
server.3=127.0.0.1:2889:3889
4.分别启动
./bin/zkServer.sh start conf/zoo1.cfg
./bin/zkServer.sh start conf/zoo2.cfg
./bin/zkServer.sh start conf/zoo3.cfg
5.分别查看状态
./bin/zkServer.sh status conf/zoo1.cfg
Mode: follower
./bin/zkServer.sh status conf/zoo2.cfg
Mode: leader
./bin/zkServer.sh status conf/zoo3.cfg
Mode: follower
检查集群复制情况:
1、分别连接指定节点
zkCli.sh 后加参数-server 表示连接指定IP与端口。
./bin/zkCli.sh -server 127.0.0.1:2181
./bin/zkCli.sh -server 127.0.0.1:2182
./bin/zkCli.sh -server 127.0.0.1:2183
l 任意节点中创建数据,查看其它节点已经同步成功。
注意: -server参数后同时连接多个服务节点,并用逗号隔开 127.0.0.1:2181,127.0.0.1:2182
集群角色说明
zookeeper 集群中总共有三种角色,分别是leader(主节点)follower(子节点) observer(次级子节点)
|
角色 |
描述 |
|
leader |
主节点,又名领导者。用于写入数据,通过选举产生,如果宕机将会选举新的主节点。 |
|
follower |
子节点,又名追随者。用于实现数据的读取。同时他也是主节点的备选节点,并用拥有投票权。 |
|
observer |
次级子节点,又名观察者。用于读取数据,与fllower区别在于没有投票权,不能选为主节点。并且在计算集群可用状态时不会将observer计算入内。 |
observer配置:
只要在集群配置中加上observer后缀即可,示例如下:
server.3=127.0.0.1:2889:3889:observer
3.选举机制
通过 ./bin/zkServer.sh status <zoo配置文件> 命令可以查看到节点状态
./bin/zkServer.sh status conf/zoo1.cfg
Mode: follower
./bin/zkServer.sh status conf/zoo2.cfg
Mode: leader
./bin/zkServer.sh status conf/zoo3.cfg
Mode: follower
可以发现中间的2182 是leader状态.其选举机制如下图:
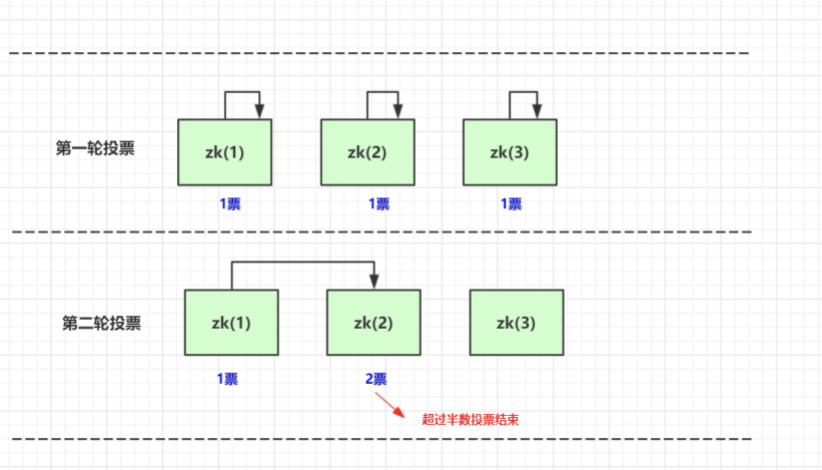
投票机制说明:
第一轮投票全部投给自己
第二轮投票给myid比自己大的相邻节点
如果得票超过半数,选举结束。
选举触发:
当集群中的服务器出现已下两种情况时会进行Leader的选举
1. 服务节点初始化启动
2. 半数以上的节点无法和Leader建立连接
当节点初始起动时会在集群中寻找Leader节点,如果找到则与Leader建立连接,其自身状态变化follower或observer。如果没有找到Leader,当前节点状态将变化LOOKING,进入选举流程。
在集群运行其间如果有follower或observer节点宕机只要不超过半数并不会影响整个集群服务的正常运行。但如果leader宕机,将暂停对外服务,所有follower将进入LOOKING 状态,进入选举流程。
数据同步机制
zookeeper 的数据同步是为了保证各节点中数据的一至性,同步时涉及两个流程,一个是正常的客户端数据提交,另一个是集群某个节点宕机在恢复后的数据同步。
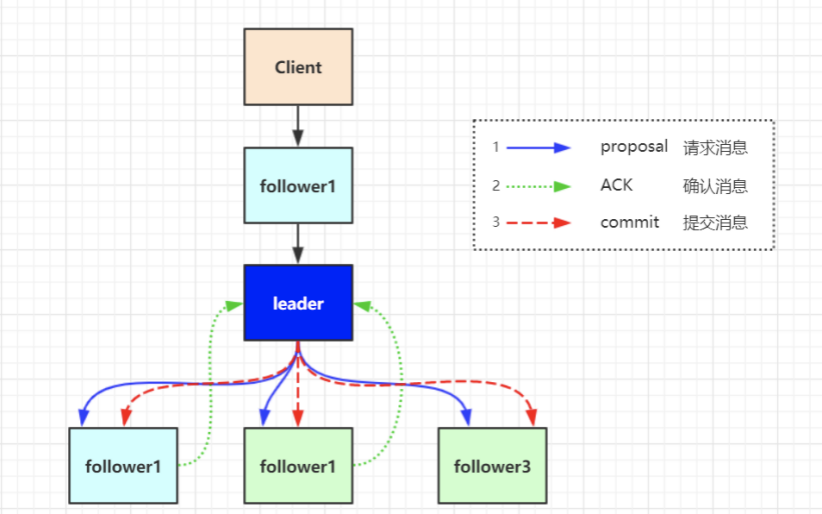
客户端写入请求:
写入请求的大至流程是,收leader接收客户端写请求,并同步给各个子节点。如下图:
但实际情况要复杂的多,比如client 它并不知道哪个节点是leader 有可能写的请求会发给follower ,由follower在转发给leader进行同步处理
客户端写入流程说明:
1. client向zk中的server发送写请求,如果该server不是leader,则会将该写请求转发给leader server,leader将请求事务以proposal形式分发给follower;
2. 当follower收到收到leader的proposal时,根据接收的先后顺序处理proposal;
3. 当Leader收到follower针对某个proposal过半的ack后,则发起事务提交,重新发起一个commit的proposal
4. Follower收到commit的proposal后,记录事务提交,并把数据更新到内存数据库;
5. 当写成功后,反馈给client。
服务节点初始化同步:
在集群运行过程当中如果有一个follower节点宕机,由于宕机节点没过半,集群仍然能正常服务。当leader 收到新的客户端请求,此时无法同步给宕机的节点。造成数据不一至。为了解决这个问题,当节点启动时,第一件事情就是找当前的Leader,比对数据是否一至。不一至则开始同步,同步完成之后在进行对外提供服务。
如何比对Leader的数据版本呢,这里通过ZXID事物ID来确认。比Leader就需要同步。
ZXID说明:
ZXID是一个长度64位的数字,其中低32位是按照数字递增,任何数据的变更都会导致,低32位的数字简单加1。高32位是leader周期编号,每当选举出一个新的leader时,新的leader就从本地事物日志中取出ZXID,然后解析出高32位的周期编号,进行加1,再将低32位的全部设置为0。这样就保证了每次新选举的leader后,保证了ZXID的唯一性而且是保证递增的。
思考题:
如果leader 节点宕机,在恢复后它还能被选为leader吗?
ZXID最大的为leader
5.四字运维命令
ZooKeeper响应少量命令。每个命令由四个字母组成。可通过telnet或nc向ZooKeeper发出命令。
这些命令默认是关闭的,需要配置4lw.commands.whitelist来打开,可打开部分或全部示例如下:
#打开指定命令
4lw.commands.whitelist=stat, ruok, conf, isro
#打开全部
4lw.commands.whitelist=*
安装Netcat工具,已使用nc命令
#安装Netcat 工具
yum install -y nc
#查看服务器及客户端连接状态
echo stat | nc localhost 2181
命令列表
1. conf:3.3.0中的新增功能:打印有关服务配置的详细信息。
2. 缺点:3.3.0中的新增功能:列出了连接到该服务器的所有客户端的完整连接/会话详细信息。包括有关已接收/已发送的数据包数量,会话ID,操作等待时间,最后执行的操作等信息。
3. crst:3.3.0中的新增功能:重置所有连接的连接/会话统计信息。
4. dump:列出未完成的会话和临时节点。这仅适用于领导者。
5. envi:打印有关服务环境的详细信息
6. ruok:测试服务器是否以非错误状态运行。如果服务器正在运行,它将以imok响应。否则,它将完全不响应。响应“ imok”不一定表示服务器已加入仲裁,只是服务器进程处于活动状态并绑定到指定的客户端端口。使用“ stat”获取有关状态仲裁和客户端连接信息的详细信息。
7. srst:重置服务器统计信息。
8. srvr:3.3.0中的新功能:列出服务器的完整详细信息。
9. stat:列出服务器和连接的客户端的简要详细信息。
10. wchs:3.3.0中的新增功能:列出有关服务器监视的简要信息。
11. wchc:3.3.0中的新增功能:按会话列出有关服务器监视的详细信息。这将输出具有相关监视(路径)的会话(连接)列表。请注意,根据手表的数量,此操作可能会很昂贵(即影响服务器性能),请小心使用。
12. dirs:3.5.1中的新增功能:以字节为单位显示快照和日志文件的总大小
13. wchp:3.3.0中的新增功能:按路径列出有关服务器监视的详细信息。这将输出具有关联会话的路径(znode)列表。请注意,根据手表的数量,此操作可能会很昂贵(即影响服务器性能),请小心使用。
14. mntr:3.4.0中的新增功能:输出可用于监视集群运行状况的变量列表。
 posted on
posted on

 浙公网安备 33010602011771号
浙公网安备 33010602011771号