二十三、Flink Table API之基本API
一、介绍
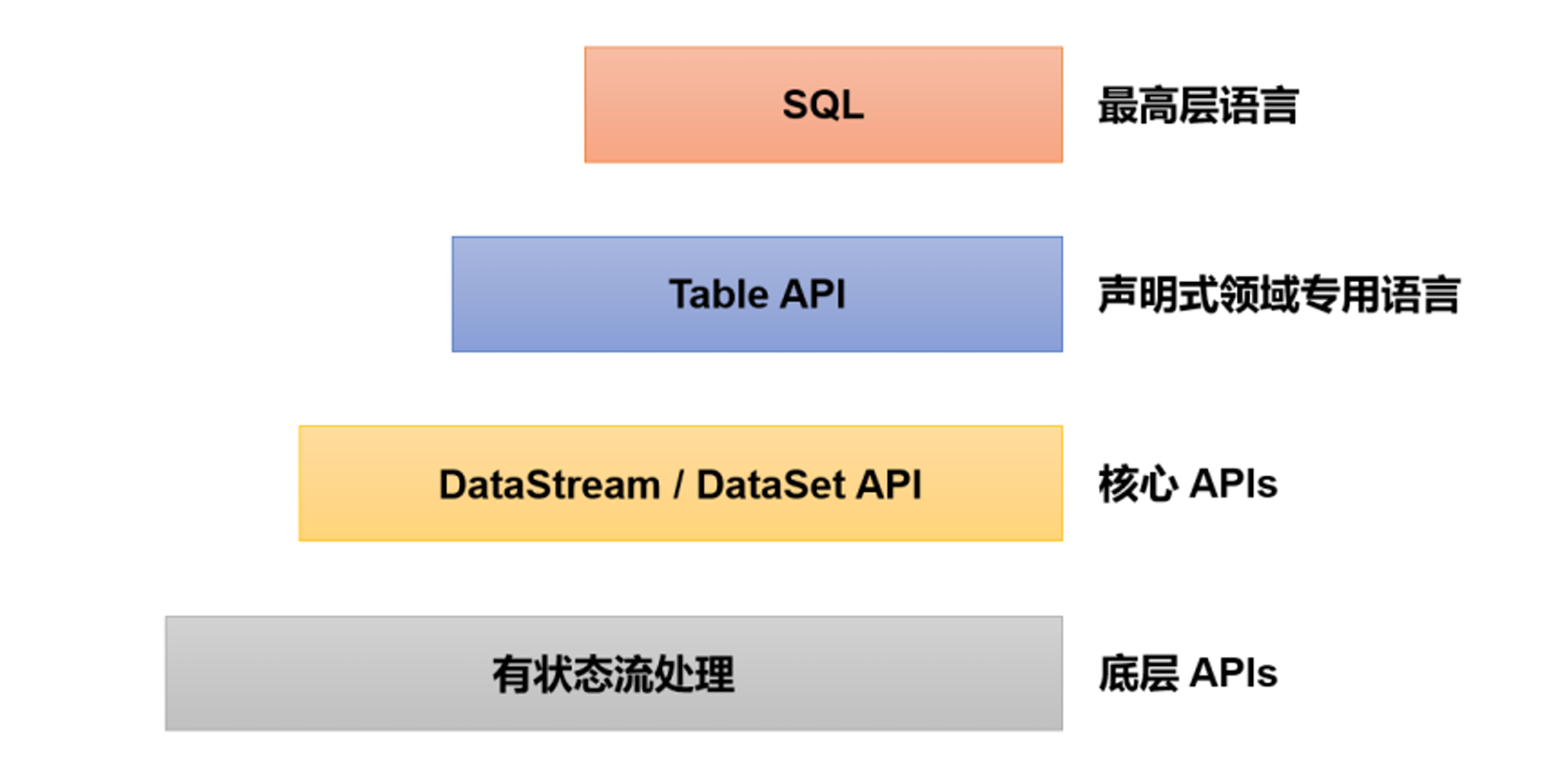
在Flink提供的多层级API中(如下图示),核心是DataStreamAPI,这是开发流处理应用的基本途径;底层则是所谓的处理函数(processfunction),可以访问事件的时间信息、注册定时器、自定义状态,进行有状态的流处理。DataStreamAPI和处理函数比较通用,有了这些API,理论上就可以实现所有场景的需求了。不过在企业实际应用中,往往会面对大量类似的处理逻辑,所以一般会将底层API包装成更加具体的应用级接口。怎样的接口风格最容易让大家接受呢?作为大数据工程师,最为熟悉的数据统计方式,当然就是写SQL。
SQL是结构化查询语言(StructuredQueryLanguage)的缩写,是对关系型数据库进行查询和修改的通用编程语言。在关系型数据库中,数据是以表(table)的形式组织起来的,所以也可以认为SQL是用来对表进行处理的工具语言。无论是传统架构中进行数据存储的MySQL、PostgreSQL,还是大数据应用中的Hive,都少不了SQL的身影;而Spark作为大数据处理引擎,为了更好地支持在Hive中的SQL查询,也提供了SparkSQL作为入口。
Flink同样提供了对于“表”处理的支持,这就是更高层级的应用API,在Flink中被称为TableAPI和SQL。TableAPI顾名思义,就是基于“表”(Table)的一套API,它是内嵌在Java、Scala等语言中的一种声明式领域特定语言(DSL),也就是专门为处理表而设计的;在此基础上,Flink还基于ApacheCalcite实现了对SQL的支持。这样一来,就可以在Flink程序中直接写SQL来实现处理需求了。
二、快速上手
如果对关系型数据库和SQL非常熟悉,那么TableAPI和SQL的使用其实非常简单:只要得到一个“表”(Table),然后对它调用TableAPI,或者直接写SQL就可以了。接下来就以一个非常简单的例子上手,初步了解一下高层级API的使用方法。
1.引入依赖
要在代码中使用Table API,必须引入相关的依赖。
<!--Table API 桥接器-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
这里的依赖是一个Java的“桥接器”(bridge),主要就是负责TableAPI和下层DataStreamAPI的连接支持,按照不同的语言分为Java版和Scala版。
如果希望在本地的集成开发环境(IDE)里运行TableAPI和SQL,还需要引入以下依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
这里主要添加的依赖是一个“计划器”(planner),它是TableAPI的核心组件,负责提供运行时环境,并生成程序的执行计划。这里用到的是新版的blinkplanner。由于Flink安装包的lib目录下会自带planner,所以在生产集群环境中提交的作业不需要打包这个依赖。
而在TableAPI的内部实现上,部分相关的代码是用Scala实现的,所以还需要额外添加一个Scala版流处理的相关依赖。而在TableAPI的内部实现上,部分相关的代码是用Scala实现的,所以还需要额外添加一个Scala版流处理的相关依赖。
另,如果想实现自定义的数据格式来做序列化,可以引入下面的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
2.简单示例
有了基本的依赖,接下来就可以在Flink代码中使用TableAPI和SQL了。比如,可以自定义一些Event类型的用户访问事件,作为输入的数据源;而后从中提取url地址和用户名user两个字段作为输出。
package com.kunan.StreamAPI.Source;
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user, String url, Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString() {
return "Event{" +
"user='" + user + '\'' +
", url='" + url + '\'' +
", timestamp=" + new Timestamp(timestamp) +
'}';
}
}
如果使用 DataStream API,我们可以直接读取数据源后,用一个简单转换算子 map 来做字 段的提取。而这个需求直接写 SQL 的话,实现会更加简单:
select url, user from EventTable;
这里把流中所有数据组成的表叫作 EventTable。在 Flink 代码中直接对这个表执行上 面的 SQL,就可以得到想要提取的数据了。
代码实现
package com.kunan.TableAPI;
import com.kunan.StreamAPI.Source.Event;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class TableExp {
public static void main(String[] args) throws Exception {
//1.获取流执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
//2.获取数据源
DataStreamSource<Event> EventStream = env.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
//3.获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
//4.将数据流转换成表
Table eventTable = tableEnv.fromDataStream(EventStream);
//5.用执行 SQL 的方式提取数据
Table resultTable = tableEnv.sqlQuery("select url,user from " + eventTable);
//6.将表转换成数据流,打印输出
tableEnv.toDataStream(resultTable).print();
//7.执行
env.execute();
}
}
这里我们需要创建一个“表环境”(TableEnvironment),然后将数据流(DataStream)转 换成一个表(Table);之后就可以执行 SQL 在这个表中查询数据了。查询得到的结果依然是 一个表,把它重新转换成流就可以打印输出了。
代码执行的结果如下:
+I[./home, Alice]
+I[./cart, Bob]
+I[./prod?id=1, Alice]
+I[./home, Cary]
+I[./prod?id=3, Bob]
+I[./prod?id=7, Alice]
可以看到,原始的Event数据转换成了(url,user)这样类似二元组的类型。每行输出前面有一个“+I”标志,这是表示每条数据都是“插入”(Insert)到表中的新增数据。
Table是TableAPI中的核心接口类,对应着“表”的概念。基于Table也可以调用一系列查询方法直接进行转换,这就是所谓TableAPI的处理方式:
//用TableAPI方式提取数据
Table resultTable2 = eventTable.select($("url"), $("user"));
这里的$符号是TableAPI中定义的“表达式”类Expressions中的一个方法,传入一个字段名称,就可以指代数据中对应字段。将得到的表转换成流打印输出,会发现结果与直接执行SQL完全一样。
三、基本API
1.程序架构
在Flink中,TableAPI和SQL可以看作联结在一起的一套API,这套API的核心概念就是“表”(Table)。在程序中,输入数据可以定义成一张表;然后对这张表进行查询,就可以得到新的表,这相当于就是流数据的转换操作;最后还可以定义一张用于输出的表,负责将处理结果写入到外部系统。
可以看到,程序的整体处理流程与DataStreamAPI非常相似,也可以分为读取数据源(Source)、转换(Transform)、输出数据(Sink)三部分;只不过这里的输入输出操作不需要额外定义,只需要将用于输入和输出的表定义出来,然后进行转换查询就可以了。
程序基本架构如下:
//创建表环境
TableEnvironment tableEnv = ...;
// 创建输入表,连接外部系统读取数据
tableEnv.executeSql("CREATE TEMPORARY TABLE inputTable ... WITH ( 'connector'= ... )");
// 注册一个表,连接到外部系统,用于输出
tableEnv.executeSql("CREATE TEMPORARY TABLE outputTable ... WITH ( 'connector'= ... )");
// 执行 SQL 对表进行查询转换,得到一个新的表
Table table1 = tableEnv.sqlQuery("SELECT ... FROM inputTable... ");
// 使用 Table API 对表进行查询转换,得到一个新的表
Table table2 = tableEnv.from("inputTable").select(...);
与上一节不同,这里不是从一个DataStream转换成Table,而是通过执行DDL来直接创建一个表。这里执行的CREATE语句中用WITH指定了外部系统的连接器,于是就可以连接外部系统读取数据了。这其实是更加一般化的程序架构,因为这样就可以完全抛开DataStreamAPI,直接用SQL语句实现全部的流处理过程。
而后面对于输出表的定义是完全一样的。可以发现,在创建表的过程中,其实并不区分“输入”还是“输出”,只需要将这个表“注册”进来、连接到外部系统就可以了;这里的inputTable、outputTable只是注册的表名,并不代表处理逻辑,可以随意更换。至于表的具体作用,则要等到执行后面的查询转换操作时才能明确。如果直接从inputTable中查询数据,那么inputTable就是输入表;而outputTable会接收另外表的结果进行写入,那么就是输出表。
在早期的版本中,有专门的用于输入输出的TableSource和TableSink,这与流处理里的概念是一一对应的;不过这种方式与关系型表和SQL的使用习惯不符,所以已被弃用,不再区分Source和Sink。
2.创建表环境
对于Flink这样的流处理框架来说,数据流和表在结构上还是有所区别的。所以使用TableAPI和SQL需要一个特别的运行时环境,这就是所谓的“表环境”(TableEnvironment)。它主要负责:
(1)注册Catalog和表;
(2)执行SQL查询;
(3)注册用户自定义函数(UDF);
(4)DataStream 和表之间的转换。
这里的Catalog就是“目录”,与标准SQL中的概念是一致的,主要用来管理所有数据库(database)和表(table)的元数据(metadata)。通过Catalog可以方便地对数据库和表进行查询的管理,所以可以认为定义的表都会“挂靠”在某个目录下,这样就可以快速检索。在表环境中可以由用户自定义Catalog,并在其中注册表和自定义函数(UDF)。默认的Catalog就叫作default_catalog。
每个表和SQL的执行,都必须绑定在一个表环境(TableEnvironment)中。TableEnvironment是TableAPI中提供的基本接口类,可以通过调用静态的create()方法来创建一个表环境实例。方法需要传入一个环境的配置参数EnvironmentSettings,它可以指定当前表环境的执行模式和计划器(planner)。执行模式有批处理和流处理两种选择,默认是流处理模式;计划器默认使用blinkplanner。
//基于blink版本planner进行流处理执行环境
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings settings = EnvironmentSettings
.newInstance()
.inStreamingMode() // 使用流处理模式
.build();
TableEnvironment tableEnv = TableEnvironment.create(settings);
//基于老版本planner进行流处理
EnvironmentSettings settings1 = EnvironmentSettings.newInstance()
.inStreamingMode()
.useOldPlanner()
.build();
TableEnvironment tableEnv1 = TableEnvironment.create(settings1);
对于流处理场景,其实默认配置就完全够用了。所以也可以用另一种更加简单的方式来创建表环境:
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
这里引入了一个“流式表环境”(StreamTableEnvironment),它是继承自TableEnvironment的子接口。调用它的create()方法,只需要直接将当前的流执行环境(StreamExecutionEnvironment)传入,就可以创建出对应的流式表环境了。
3.创建表
表(Table)是关系型数据库中数据存储的基本形式,也是SQL执行的基本对象。Flink中的表概念也并不特殊,是由多个“行”数据构成的,每个行(Row)又可以有定义好的多个列(Column)字段;整体来看,表就是固定类型的数据组成的二维矩阵。
为了方便地查询表,表环境中会维护一个目录(Catalog)和表的对应关系。所以表都是通过Catalog来进行注册创建的。表在环境中有一个唯一的ID,由三部分组成:目录(catalog)名,数据库(database)名,以及表名。在默认情况下,目录名为default_catalog,数据库名为default_database。所以如果我们直接创建一个叫作MyTable的表,它的ID就是:
default_catalog.default_database.MyTable
具体创建表的方式,有通过连接器(connector)和虚拟表(virtual tables)两种。
- 连接器表(Connector Tables)
最直观的创建表的方式,就是通过连接器(connector)连接到一个外部系统,然后定义出对应的表结构。例如可以连接到Kafka或者文件系统,将存储在这些外部系统的数据以“表”的形式定义出来,这样对表的读写就可以通过连接器转换成对外部系统的读写了。在表环境中读取这张表时,连接器就会从外部系统读取数据并进行转换;而当向这张表写入数据,连接器就会将数据输出(Sink)到外部系统中。
在代码中,可以调用表环境的executeSql()方法,可以传入一个DDL作为参数执行SQL操作。这里传入一个CREATE语句进行表的创建,并通过WITH关键字指定连接到外部系统的连接器:
tableEnv.executeSql("CREATE [TEMPORARY] TABLE MyTable ... WITH ( 'connector'= ... )")
这里的 TEMPORARY 关键字可以省略。
这里没有定义Catalog和Database,所以都是默认的,表的完整ID就是default_catalog.default_database.MyTable。如果希望使用自定义的目录名和库名,可以在环境中进行设置:
tEnv.useCatalog("custom_catalog");
tEnv.useDatabase("custom_database");
这样创建的表完整ID就变成了custom_catalog.custom_database.MyTable。之后在表环境中创建的所有表,ID也会都以custom_catalog.custom_database作为前缀。
-
虚拟表(Virtual Tables)
在环境中注册之后,就可以在SQL中直接使用这张表进行查询转换了。
Table newTable = tableEnv.sqlQuery("SELECT ... FROM MyTable... ");
这里调用了表环境的sqlQuery()方法,直接传入一条SQL语句作为参数执行查询,得到的结果是一个Table对象。Table是TableAPI中提供的核心接口类,就代表了一个Java中定义的表实例。
得到的newTable是一个中间转换结果,如果之后又希望直接使用这个表执行SQL,又该怎么做呢?由于newTable是一个Table对象,并没有在表环境中注册;所以还需要将这个中间结果表注册到环境中,才能在SQL中使用:
tableEnv.createTemporaryView("NewTable", newTable);
可以发现,这里的注册其实是创建了一个“虚拟表”(VirtualTable)。这个概念与SQL语法中的视图(View)非常类似,所以调用的方法也叫作创建“虚拟视图”(createTemporaryView)。视图之所以是“虚拟”的,是因为并不会直接保存这个表的内容,并没有“实体”;只是在用到这张表的时候,会将它对应的查询语句嵌入到SQL中。
注册为虚拟表之后,就可以在SQL中直接使用NewTable进行查询转换了。不难看到,通过虚拟表可以非常方便地让SQL分步骤执行得到中间结果,这为代码编写提供了很大的便利。
另,虚拟表也可以在TableAPI和SQL之间进行自由切换。一个Java中的Table对象可以直接调用TableAPI中定义好的查询转换方法,得到一个中间结果表;这跟对注册好的表直接执行SQL结果是一样的。具体见下节。
4.表的查询
创建好了表,接下来自然就是对表进行查询转换了。对一个表的查询(Query)操作,就对应着流数据的转换(Transform)处理。
Flink提供了两种查询方式:SQL和TableAPI。
- 执行 SQL 进行查询
基于表执行SQL语句,是最熟悉的查询方式。Flink基于ApacheCalcite来提供对SQL的支持,Calcite是一个为不同的计算平台提供标准SQL查询的底层工具,很多大数据框架比如ApacheHive、ApacheKylin中的SQL支持都是通过集成Calcite来实现的。
在代码中,只要调用表环境的sqlQuery()方法,传入一个字符串形式的SQL查询语句就可以了。执行得到的结果,是一个Table对象。
// 创建表环境
TableEnvironment tableEnv = ...;
// 创建表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
// 查询用户 Alice 的点击事件,并提取表中前两个字段
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
目前Flink支持标准SQL中的绝大部分用法,并提供了丰富的计算函数。这样可以把已有的技术迁移过来,像在MySQL、Hive中那样直接通过编写SQL实现自己的处理需求,从而大大降低了Flink上手的难度。
例如,可以通过 GROUP BY 关键字定义分组聚合,调用 COUNT()、SUM()这样的 函数来进行统计计算:
Table urlCountTable = tableEnv.sqlQuery(
"SELECT user, COUNT(url) " +
"FROM EventTable " +
"GROUP BY user "
);
上面的例子得到的是一个新的Table对象,可以再次将它注册为虚拟表继续在SQL中调用。另外,我们也可以直接将查询的结果写入到已经注册的表中,这需要调用表环境的executeSql()方法来执行DDL,传入的是一个INSERT语句:
// 注册表
tableEnv.executeSql("CREATE TABLE EventTable ... WITH ( 'connector' = ... )");
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 将查询结果输出到 OutputTable 中
tableEnv.executeSql (
"INSERT INTO OutputTable " +
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
- 调用 Table API 进行查询
另外一种查询方式就是调用TableAPI。这是嵌入在Java和Scala语言内的查询API,核心就是Table接口类,通过一步步链式调用Table的方法,就可以定义出所有的查询转换操作。每一步方法调用的返回结果,都是一个Table。
由于TableAPI是基于Table的Java实例进行调用的,首先要得到表的Java对象。基于环境中已注册的表,可以通过表环境的from()方法非常容易地得到一个Table对象:
Table eventTable = tableEnv.from("EventTable");
传入的参数就是注册好的表名。注意这里eventTable是一个Table对象,而EventTable是在环境中注册的表名。得到Table对象之后,就可以调用API进行各种转换操作了,得到的是一个新的Table对象:
Table maryClickTable = eventTable
.where($("user").isEqual("Alice"))
.select($("url"), $("user"));
这里每个方法的参数都是一个“表达式”(Expression),用方法调用的形式直观地说明了想要表达的内容;“$”符号用来指定表中的一个字段。上面的代码和直接执行SQL是等效的。
TableAPI是嵌入编程语言中的DSL,SQL中的很多特性和功能必须要有对应的实现才可以使用,因此跟直接写SQL比起来肯定就要麻烦一些。目前TableAPI支持的功能相对更少,可以预见未来Flink社区也会以扩展SQL为主,为大家提供更加通用的接口方式;所以我们接下来也会以介绍SQL为主,简略地提及TableAPI。
- 两种 API 的结合使用
可以发现,无论是调用TableAPI还是执行SQL,得到的结果都是一个Table对象;所以这两种API的查询可以很方便地结合在一起。
(1)无论是那种方式得到的Table对象,都可以继续调用TableAPI进行查询转换;
(2)如果想要对一个表执行SQL操作(用FROM关键字引用),必须先在环境中对它进行注册。所以可以通过创建虚拟表的方式实现两者的转换:
tableEnv.createTemporaryView("MyTable", myTable);
注意:这里的第一个参数"MyTable"是注册的表名,而第二个参数myTable是Java中的Table对象。
另外要说明的是,在2.1.2小节的简单示例中,没有将Table对象注册为虚拟表就直接在SQL中使用了:
Table clickTable = tableEnvironment.sqlQuery("select url, user from " + eventTable);
这其实是一种简略的写法,将Table对象名eventTable直接以字符串拼接的形式添加到SQL语句中,在解析时会自动注册一个同名的虚拟表到环境中,这样就省略了创建虚拟视图的步骤。
两种API殊途同归,实际应用中可以按照自己的习惯任意选择。不过由于结合使用容易引起混淆,而TableAPI功能相对较少、通用性较差,所以企业项目中往往会直接选择SQL的方式来实现需求。
5.输出表
表的创建和查询,就对应着流处理中的读取数据源(Source)和转换(Transform);而最后一个步骤Sink,也就是将结果数据输出到外部系统,就对应着表的输出操作。
在代码上,输出一张表最直接的方法,就是调用Table的方法executeInsert()方法将一个Table写入到注册过的表中,方法传入的参数就是注册的表名。
// 注册表,用于输出数据到外部系统
tableEnv.executeSql("CREATE TABLE OutputTable ... WITH ( 'connector' = ... )");
// 经过查询转换,得到结果表
Table result = ...
// 将结果表写入已注册的输出表中
result.executeInsert("OutputTable");
在底层,表的输出是通过将数据写入到TableSink来实现的。TableSink是TableAPI中提供的一个向外部系统写入数据的通用接口,可以支持不同的文件格式(比如CSV、Parquet)、存储数据库(比如JDBC、HBase、Elasticsearch)和消息队列(比如Kafka)。它有些类似于DataStreamAPI中调用addSink()方法时传入的SinkFunction,有不同的连接器对它进行了实现。关于不同外部系统的连接器,后续详细学习。
这里可以发现,环境中注册的“表”,其实在写入数据的时候就对应着一个TableSink。
6.表和流的转换
从创建表环境开始,历经表的创建、查询转换和输出,已经可以使用TableAPI和SQL进行完整的流处理了。不过在应用的开发过程中,测试业务逻辑一般不会直接将结果直接写入到外部系统,而是在本地控制台打印输出。对于DataStream这非常容易,直接调用print()方法就可以看到结果数据流的内容了;但对于Table就比较悲剧——它没有提供print()方法。这该怎么办呢?
在Flink中可以将Table再转换成DataStream,然后进行打印输出。这就涉及了表和流的转换
- 将表(Table)转换成流(DataStream)
(1)调用toDataStream()方法将一个Table对象转换成DataStream非常简单,只要直接调用表环境的方法toDataStream()就可以了。例如,可以将上节经查询转换得到的表maryClickTable转换成流打印输出,这代表了“Mary点击的url列表”:
Table aliceVisitTable = tableEnv.sqlQuery(
"SELECT user, url " +
"FROM EventTable " +
"WHERE user = 'Alice' "
);
// 将表转换成数据流
tableEnv.toDataStream(aliceVisitTable).print();
这里需要将要转换的Table对象作为参数传入。
(2)调用toChangelogStream()方法将maryClickTable转换成流打印输出是很简单的;然而,如果同样希望将“用户点击次数统计”表urlCountTable进行打印输出,就会抛出一个TableException异常:
Exception in thread "main" org.apache.flink.table.api.TableException: Table sink
'default_catalog.default_database.Unregistered_DataStream_Sink_1' doesn't
support consuming update changes ...
这表示当前的TableSink并不支持表的更新(update)操作。这是为什么?
因为print本身也可以看作一个Sink操作,所以这个异常就是说打印输出的Sink操作不支持对数据进行更新。具体来说,urlCountTable这个表中进行了分组聚合统计,所以表中的每一行是会“更新”的。也就是说,Alice的第一个点击事件到来,表中会有一行(Alice,1);第二个点击事件到来,这一行就要更新为(Alice,2)。但之前的(Alice,1)已经打印输出了,“覆水难收”,怎么能对它进行更改呢?所以就会抛出异常。
解决的思路是,对于这样有更新操作的表,不要试图直接把它转换成DataStream打印输出,而是记录一下它的“更新日志”(changelog)。这样一来,对于表的所有更新操作,就变成了一条更新日志的流,我们就可以转换成流打印输出了。
代码中需要调用的是表环境的 toChangelogStream()方法:
Table urlCountTable = tableEnv.sqlQuery(
"SELECT user, COUNT(url) " +
"FROM EventTable " +
"GROUP BY user "
);
// 将表转换成更新日志流
tableEnv.toDataStream(urlCountTable).print();
与“更新日志流”(ChangelogStreams)对应的,是那些只做了简单转换、没有进行聚合统计的表,例如前面提到的maryClickTable。它们的特点是数据只会插入、不会更新,所以也被叫作“仅插入流”(Insert-OnlyStreams)。
- 将流(DataStream)转换成表(Table)
(1)调用fromDataStream()方法想要将一个DataStream转换成表也很简单,可以通过调用表环境的fromDataStream()方法来实现,返回的就是一个Table对象。例如,可以直接将事件流eventStream转换成一个表:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env.addSource(...)
// 将数据流转换成表
Table eventTable = tableEnv.fromDataStream(eventStream);
由于流中的数据本身就是定义好的POJO类型Event,所以将流转换成表之后,每一行数据就对应着一个Event,而表中的列名就对应着Event中的属性。
另,还可以在fromDataStream()方法中增加参数,用来指定提取哪些属性作为表中的字段名,并可以任意指定位置:
//提取Event中的timestamp和url作为表中的列
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp"),$("url"));
需要注意,timestamp本身是SQL中的关键字,所以在定义表名、列名时要尽量避免。这时可以通过表达式的as()方法对字段进行重命名:
//将timestamp字段重命名为 ts
Table eventTable2 = tableEnv.fromDataStream(eventStream, $("timestamp").as("ts"),$("url"));
(2)调用 createTemporaryView()方法
调用fromDataStream()方法简单直观,可以直接实现DataStream到Table的转换;不过如果希望直接在SQL中引用这张表,就还需要调用表环境的createTemporaryView()方法来创建虚拟视图了。
对于这种场景,也有一种更简洁的调用方式。可以直接调用createTemporaryView()方法创建虚拟表,传入的两个参数,第一个依然是注册的表名,而第二个可以直接就是DataStream。之后仍旧可以传入多个参数,用来指定表中的字段
tableEnv.createTemporaryView("EventTable", eventStream,$("timestamp").as("ts"),$("url"));
这样,接下来就可以直接在SQL中引用表EventTable了。
(3)调用 fromChangelogStream ()方法
表环境还提供了一个方法fromChangelogStream(),可以将一个更新日志流转换成表。这个方法要求流中的数据类型只能是Row,而且每一个数据都需要指定当前行的更新类型(RowKind);所以一般是由连接器实现的,直接应用比较少见,可以查看官网的文档说明。
- 支持的数据类型
前面示例中的DataStream,流中的数据类型都是定义好的POJO类。如果DataStream中的类型是简单的基本类型,还可以直接转换成表吗?这就涉及了Table中支持的数据类型。
整体来看,DataStream中支持的数据类型,Table中也是都支持的,只不过在进行转换时需要注意一些细节。
(1)原子类型
在Flink中,基础数据类型(Integer、Double、String)和通用数据类型(也就是不可再拆分的数据类型)统一称作“原子类型”。原子类型的DataStream,转换之后就成了只有一列的Table,列字段(field)的数据类型可以由原子类型推断出。另外,还可以在fromDataStream()方法里增加参数,用来重新命名列字段。
StreamTableEnvironment tableEnv = ...;
DataStream<Long> stream = ...;
//将数据流转换成动态表,动态表只有一个字段,重命名为 myLong
Table table = tableEnv.fromDataStream(stream, $("myLong"));
(2)Tuple 类型
当原子类型不做重命名时,默认的字段名就是“f0”,容易想到,这其实就是将原子类型看作了一元组Tuple1的处理结果。
Table支持Flink中定义的元组类型Tuple,对应在表中字段名默认就是元组中元素的属性名f0、f1、f2...。所有字段都可以被重新排序,也可以提取其中的一部分字段。字段还可以通过调用表达式的as()方法来进行重命名。
StreamTableEnvironment tableEnv = ...;
DataStream<Tuple2<Long, Integer>> stream = ...;
// 将数据流转换成只包含 f1 字段的表
Table table = tableEnv.fromDataStream(stream, $("f1"));
// 将数据流转换成包含 f0 和 f1 字段的表,在表中 f0 和 f1 位置交换
Table table = tableEnv.fromDataStream(stream, $("f1"), $("f0"));
// 将 f1 字段命名为 myInt,f0 命名为 myLong
Table table = tableEnv.fromDataStream(stream, $("f1").as("myInt"),$("f0").as("myLong"));
(3)POJO 类型
Flink也支持多种数据类型组合成的“复合类型”,最典型的就是简单Java对象(POJO类型)。由于POJO中已经定义好了可读性强的字段名,这种类型的数据流转换成Table就显得无比顺畅了。
将POJO类型的DataStream转换成Table,如果不指定字段名称,就会直接使用原始POJO类型中的字段名称。POJO中的字段同样可以被重新排序、提却和重命名,这在之前的例子中已经有过体现。
StreamTableEnvironment tableEnv = ...;
DataStream<Event> stream = ...;
Table table = tableEnv.fromDataStream(stream);
Table table = tableEnv.fromDataStream(stream, $("user"));
Table table = tableEnv.fromDataStream(stream, $("user").as("myUser"),$("url").as("myUrl"));
(4)Row 类型
Flink中还定义了一个在关系型表中更加通用的数据类型——行(Row),它是Table中数据的基本组织形式。Row类型也是一种复合类型,它的长度固定,而且无法直接推断出每个字段的类型,所以在使用时必须指明具体的类型信息;在创建Table时调用的CREATE语句就会将所有的字段名称和类型指定,这在Flink中被称为表的“模式结构”(Schema)。除此之外,Row类型还附加了一个属性RowKind,用来表示当前行在更新操作中的类型。这样,Row就可以用来表示更新日志流(changelogstream)中的数据,从而架起了Flink中流和表的转换桥梁。
所以在更新日志流中,元素的类型必须是Row,而且需要调用ofKind()方法来指定更新类型。下面是一个具体的例子:
DataStream<Row> dataStream =
env.fromElements(
Row.ofKind(RowKind.INSERT, "Alice", 12),
Row.ofKind(RowKind.INSERT, "Bob", 5),
Row.ofKind(RowKind.UPDATE_BEFORE, "Alice", 12),
Row.ofKind(RowKind.UPDATE_AFTER, "Alice", 100));
// 将更新日志流转换为表
Table table = tableEnv.fromChangelogStream(dataStream);
- 综合应用示例
现在,可以将介绍过的所有API整合起来,写出一段完整的代码。同样还是用户的一组点击事件,可以查询出某个用户(例如Alice)点击的url列表,也可以统计出每个用户累计的点击次数,这可以用两句SQL来分别实现。具体代码如下:
package com.kunan.TableAPI;
import com.kunan.StreamAPI.Source.Event;
import org.apache.flink.client.program.StreamContextEnvironment;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.Table;
import org.apache.flink.table.api.bridge.java.StreamTableEnvironment;
public class TableToStreamExp {
public static void main(String[] args) throws Exception {
// 获取流环境
StreamExecutionEnvironment env = StreamContextEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 读取数据源
SingleOutputStreamOperator<Event> eventStream = env
.fromElements(
new Event("Alice", "./home", 1000L),
new Event("Bob", "./cart", 1000L),
new Event("Alice", "./prod?id=1", 5 * 1000L),
new Event("Cary", "./home", 60 * 1000L),
new Event("Bob", "./prod?id=3", 90 * 1000L),
new Event("Alice", "./prod?id=7", 105 * 1000L)
);
// 获取表环境
StreamTableEnvironment tableEnv = StreamTableEnvironment.create(env);
// 将数据流转换成表
tableEnv.createTemporaryView("EventTable", eventStream);
// 查询 Alice 的访问 url 列表
Table aliceVisitTable = tableEnv.sqlQuery("SELECT url, user FROM EventTable WHERE user = 'Alice'");
// 统计每个用户的点击次数
Table urlCountTable = tableEnv.sqlQuery("SELECT user, COUNT(url) FROM EventTable GROUP BY user");
// 将表转换成数据流,在控制台打印输出
tableEnv.toDataStream(aliceVisitTable).print("alice visit");
tableEnv.toChangelogStream(urlCountTable).print("count");
// 执行程序
env.execute();
}
}
用户Alice的点击url列表只需要一个简单的条件查询就可以得到,对应的表中只有插入操作,所以可以直接调用toDataStream()将它转换成数据流,然后打印输出。控制台输出的结果如下:
alice visit> +I[./home, Alice]
alice visit> +I[./prod?id=1, Alice]
alice visit> +I[./prod?id=7, Alice]
这里每条数据前缀的+I就是RowKind,表示INSERT(插入)。
而由于统计点击次数时用到了分组聚合,造成结果表中数据会有更新操作,所以在打印输出时需要将表urlCountTable转换成更新日志流(changelogstream)。控制台输出的结果如下:
count> +I[Alice, 1]
count> +I[Bob, 1]
count> -U[Alice, 1]
count> +U[Alice, 2]
count> +I[Cary, 1]
count> -U[Bob, 1]
count> +U[Bob, 2]
count> -U[Alice, 2]
count> +U[Alice, 3]
这里数据的前缀出现了+I、-U和+U三种RowKind,分别表示INSERT(插入)、UPDATE_BEFORE(更新前)和UPDATE_AFTER(更新后)。当收到每个用户的第一次点击事件时,会在表中插入一条数据,例如+I[Alice,1]、+I[Bob,1]。而之后每当用户增加一次点击事件,就会带来一次更新操作,更新日志流(changelogstream)中对应会出现两条数据,分别表示之前数据的失效和新数据的生效;例如当Alice的第二条点击数据到来时,会出现一个-U[Alice,1]和一个+U[Alice,2],表示Alice的点击个数从1变成了2。
这种表示更新日志的方式,有点像是声明“撤回”了之前的一条数据、再插入一条更新后的数据,所以也叫作“撤回流”(RetractStream)。关于表到流转换过程的编码方式,会在下节进行更深入的讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号