十九、Flink状态编程之状态持久化和状态后端
简介
在Flink的状态管理机制中,很重要的一个功能就是对状态进行持久化(persistence)保存,这样就可以在发生故障后进行重启恢复。Flink对状态进行持久化的方式,就是将当前所有分布式状态进行“快照”保存,写入一个“检查点”(checkpoint)或者保存点(savepoint)保存到外部存储系统中。具体的存储介质,一般是分布式文件系统(distributedfilesystem)。
一、检查点(CheckPoint)
有状态流应用中的检查点(checkpoint),其实就是所有任务的状态在某个时间点的一个快照(一份拷贝)。简单来讲,就是一次“存盘”,让之前处理数据的进度不要丢掉。在一个流应用程序运行时,Flink会定期保存检查点,在检查点中会记录每个算子的id和状态;如果发生故障,Flink就会用最近一次成功保存的检查点来恢复应用的状态,重新启动处理流程,就如同“读档”一样。
如果保存检查点之后又处理了一些数据,然后发生了故障,那么重启恢复状态之后这些数据带来的状态改变会丢失。为了让最终处理结果正确,我们还需要让源(Source)算子重新读取这些数据,再次处理一遍。这就需要流的数据源具有“数据重放”的能力,一个典型的例子就是Kafka,我们可以通过保存消费数据的偏移量、故障重启后重新提交来实现数据的重放。这是对“至少一次”(atleastonce)状态一致性的保证,如果希望实现“精确一次”(exactlyonce)的一致性,还需要数据写入外部系统时的相关保证。关于这部分内容会在后续继续讨论。
默认情况下,检查点是被禁用的,需要在代码中手动开启。直接调用执行环境的.enableCheckpointing()方法就可以开启检查点。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getEnvironment();
env.enableCheckpointing(1000);
这里传入的参数是检查点的间隔时间,单位为毫秒。关于检查点的详细配置,可以参考之前内容。
除了检查点之外,Flink 还提供了“保存点”(savepoint)的功能。保存点在原理和形式上 跟检查点完全一样,也是状态持久化保存的一个快照;区别在于,保存点是自定义的镜像保存,所以不会由 Flink 自动创建,而需要用户手动触发。这在有计划地停止、重启应用时非常有用。
二、 状态后端(StateBackends)
检查点的保存离不开JobManager和TaskManager,以及外部存储系统的协调。在应用进行检查点保存时,首先会由JobManager向所有TaskManager发出触发检查点的命令;TaskManger收到之后,将当前任务的所有状态进行快照保存,持久化到远程的存储介质中;完成之后向JobManager返回确认信息。这个过程是分布式的,当JobManger收到所有TaskManager的返回信息后,就会确认当前检查点成功保存,如图所示。而这一切工作的协调,就需要一个“专职人员”来完成。
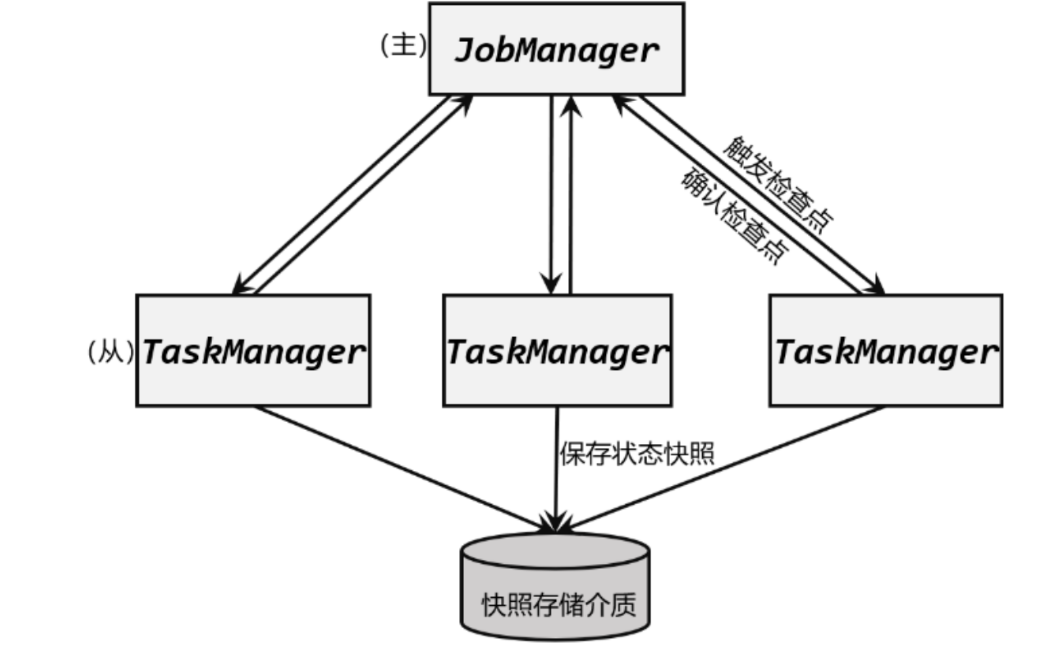
在Flink中,状态的存储、访问以及维护,都是由一个可插拔的组件决定的,这个组件就叫作状态后端(statebackend)。状态后端主要负责两件事:一是本地的状态管理,二是将检查点(checkpoint)写入远程的持久化存储。
1.状态后端的分类
状态后端是一个“开箱即用”的组件,可以在不改变应用程序逻辑的情况下独立配置。Flink中提供了两类不同的状态后端,一种是“哈希表状态后端”(HashMapStateBackend),另一种是“内嵌RocksDB状态后端”(EmbeddedRocksDBStateBackend)。如果没有特别配置,系统默认的状态后端是HashMapStateBackend。
<1> 哈希表状态后端(HashMapStateBackend)
这种方式就是之前所说的,把状态存放在内存里。具体实现上,哈希表状态后端在内部会直接把状态当作对象(objects),保存在Taskmanager的JVM堆(heap)上。普通的状态,以及窗口中收集的数据和触发器(triggers),都会以键值对(key-value)的形式存储起来,所以底层是一个哈希表(HashMap),这种状态后端也因此得名。
对于检查点的保存,一般是放在持久化的分布式文件系统(filesystem)中,也可以通过配置“检查点存储”(CheckpointStorage)来另外指定。
HashMapStateBackend是将本地状态全部放入内存的,这样可以获得最快的读写速度,使计算性能达到最佳;代价则是内存的占用。它适用于具有大状态、长窗口、大键值状态的作业,对所有高可用性设置也是有效的。
<2> 内嵌 RocksDB 状态后端(EmbeddedRocksDBStateBackend)
RocksDB是一种内嵌的key-value存储介质,可以把数据持久化到本地硬盘。配置EmbeddedRocksDBStateBackend后,会将处理中的数据全部放入RocksDB数据库中,RocksDB默认存储在TaskManager的本地数据目录里。
与HashMapStateBackend直接在堆内存中存储对象不同,这种方式下状态主要是放在RocksDB中的。数据被存储为序列化的字节数组(ByteArrays),读写操作需要序列化/反序列化,因此状态的访问性能要差一些。另外,因为做了序列化,key的比较也会按照字节进行,而不是直接调用.hashCode()和.equals()方法。
对于检查点,同样会写入到远程的持久化文件系统中。
EmbeddedRocksDBStateBackend始终执行的是异步快照,也就是不会因为保存检查点而阻塞数据的处理;而且它还提供了增量式保存检查点的机制,这在很多情况下可以大大提升保存效率。
由于它会把状态数据落盘,而且支持增量化的检查点,所以在状态非常大、窗口非常长、键/值状态很大的应用场景中是一个好选择,同样对所有高可用性设置有效。
2.如何选择正确的状态后端
HashMap和RocksDB两种状态后端最大的区别,就在于本地状态存放在哪里:前者是内存,后者是RocksDB。在实际应用中,选择那种状态后端,主要是需要根据业务需求在处理性能和应用的扩展性上做一个选择。
HashMapStateBackend是内存计算,读写速度非常快;但是,状态的大小会受到集群可用内存的限制,如果应用的状态随着时间不停地增长,就会耗尽内存资源。
而RocksDB是硬盘存储 所以可以根据可用的磁盘空间进行扩展,而且是唯一支持增量检查点的状态后端,所以它非常适合于超级海量状态的存储。不过由于每个状态的读写都需要做序列化/反序列化,而且可能需要直接从磁盘读取数据,这就会导致性能的降低,平均读写性能要比HashMapStateBackend慢一个数量级。
可以发现,实际应用就是权衡利弊后的取舍。最理想的当然是处理速度快且内存不受限制可以处理海量状态,那就需要非常大的内存资源了,这会导致成本超出项目预算。比起花更多的钱,稍慢的处理速度或者稍小的处理规模,老板可能更容易接受一点。
3.状态后端的配置
在不做配置的时候,应用程序使用的默认状态后端是由集群配置文件flink-conf.yaml中指定的,配置的键名称为state.backend。这个默认配置对集群上运行的所有作业都有效,可以通过更改配置值来改变默认的状态后端。另外,还可以在代码中为当前作业单独配置状态后端,这个配置会覆盖掉集群配置文件的默认值。
<1> 配置默认的状态后端
在flink-conf.yaml中,可以使用state.backend来配置默认状态后端。
配置项的可能值为hashmap,这样配置的就是HashMapStateBackend;也可以是rocksdb,
这样配置的就是EmbeddedRocksDBStateBackend。另外,也可以是一个实现了状态后端工厂StateBackendFactory的类的完全限定类名。
下面是一个配置HashMapStateBackend的例子:
# 默认状态后端
state.backend: hashmap
# 存放检查点的文件路径
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
emsp; 这里的state.checkpoints.dir配置项,定义了状态后端将检查点和元数据写入的目录
<2>为每个作业(Per-job)单独配置状态后端
每个作业独立的状态后端,可以在代码中,基于作业的执行环境直接设置。代码如下:
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new HashMapStateBackend());
上面代码设置的是 HashMapStateBackend,如果想要设置 EmbeddedRocksDBStateBackend, 可以用下面的配置方式:
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new EmbeddedRocksDBStateBackend());v
需要注意,如果想在IDE中使用EmbeddedRocksDBStateBackend,需要为Flink项目添加依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId>
<version>1.13.0</version>
</dependency>
而由于Flink发行版中默认就包含了RocksDB,所以只要我们的代码中没有使用RocksDB的相关内容,就不需要引入这个依赖。即使我们在flink-conf.yaml配置文件中设定了state.backend为rocksdb,也可以直接正常运行,并且使用RocksDB作为状态后端。
Flink状态编程总结
有状态的流处理是Flink的本质,所以状态可以说是Flink中最为重要的概念。之前聚合算子、窗口算子中已经提到了状态的概念,而通过本章的学习,对整个Flink的状态管理机制和状态编程的方式都有了非常详尽的了解
本章从状态的概念和分类出发,详细介绍了Flink中的按键分区状态(KeyedState)和算子状态(OperatorState)的特点和用法,并对广播状态(BroadcastState)做了进一步的展开说明。最后,还介绍了状态的持久化和状态后端,引出了检查点(checkpoint)的概念。检查点是一个非常重要的概念,是Flink容错机制的核心,将在下一章继续进行详细的讨论。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号