
Java使用ffmpeg打开流时挂在avformat_open_input的native代码上
前情提要
在我所负责的一个Java项目里面有通过使用ffmpeg开源库来打开实时流截帧并上传图片的业务流程。
然后这个服务在几个地方的服务器上能正常使用,但是在W地服务器上会间歇性出现服务异常。
服务异常最直观的表现就是不再有实时流的图片上传更新,重启服务后又能恢复更新,但是一段时间(不固定)后又停止更新了。
然后定位过程中发现Java层的线程挂(hang)在avformat_open_input的native代码上了。
环境
先讲一下我使用的环境:Linux,JDK8,ffmpeg相关的开源库主要是org.bytedeco.javacv-1.5.2,实时流的协议是HLS(问题的根因对于其它实时流协议应该也有参考意义)。
问题关键点
接着讲一下发生问题时,程序反馈出来的几个关键点:
1、在打印出类似“开始打开流”的业务日志后再无输出(也有发现会隔几小时后突然打印一句“无法大概xxx流”的日志)。
2、控制台不断输出如下日志(后面分析可知,这里实际上是在解析playlist,也就是HLS协议内的东西了,可以看到下面有在打开.m3u8文件,也有在打开.ts)。
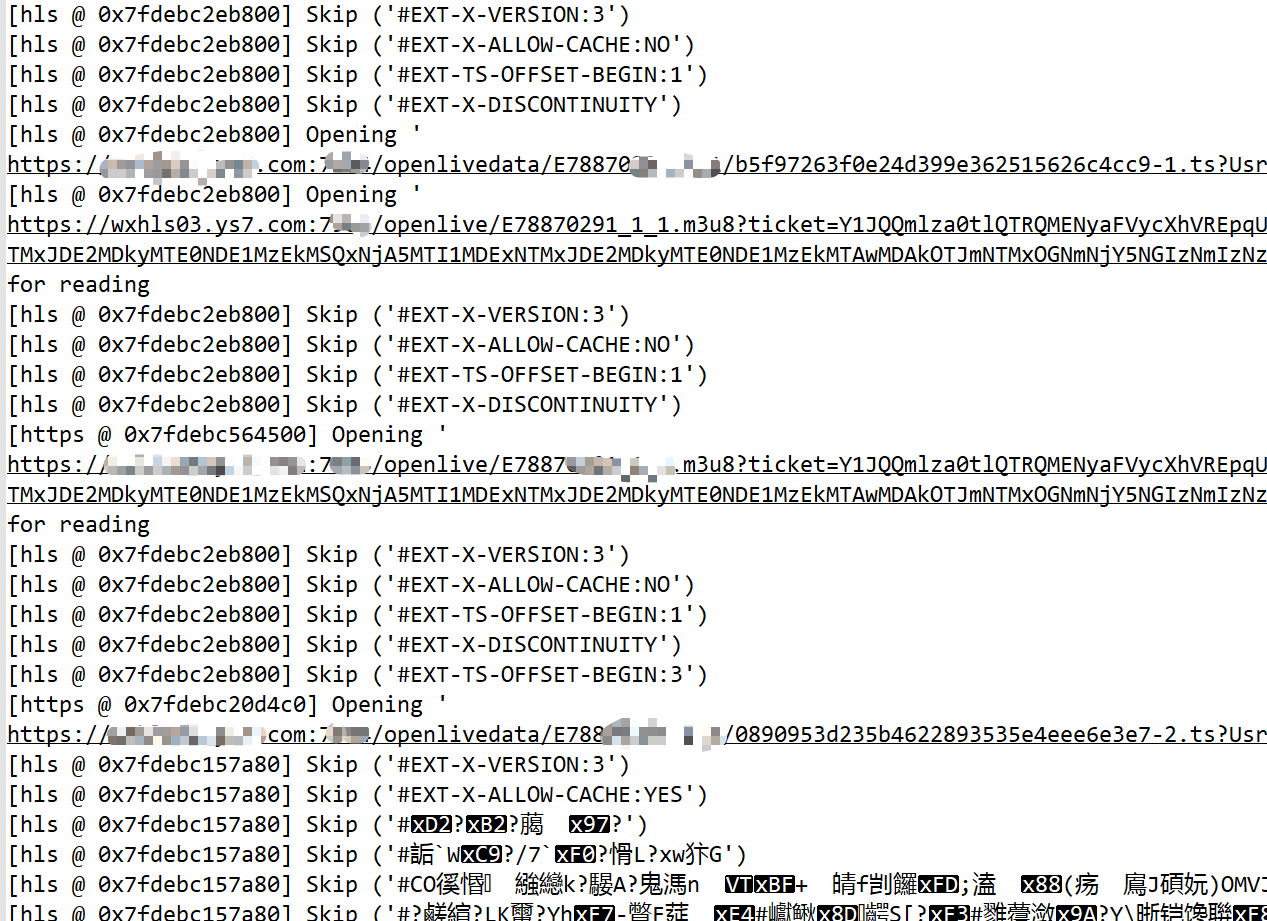
3、通过jstack查看我们的服务,发现我们的线程挂(hang)在avformat_open_input的native方法上,而且此时的线程是RUNNABLE状态(也就是说并不是等待的状态)。

解决问题的历程
在我看到线程是挂(hang)在Native方法里的时候是懵逼的,毕竟Native方法代表的是底层C语言实现的逻辑。
我先后在百度、谷歌、StackOverflow和javacv的Github issue里面翻了很多相关的挂住的问题,但分析后发现基本上和我的问题不是很相关,这导致我前期一直在跟javacv的一些“超时”设置在打交道。
期间我也尝试抓包看内容,但不幸的是它用的https,这导致我可能一开始就忽略了一些信息(后来发现这里换成http能用,参考萤石的文档发现改成rtmp的协议链接也能用)。
多方尝试无果后,我最终想了想感觉只能去下载ffmpeg的源码跟着逻辑来理思路了。
在我下了源码跟着看了一段时间后,我就发现ffmpeg里面hls协议的一段处理逻辑和我遇到的现象比较吻合,结合我正好用http的方式抓到数据包得出了初步的结论。
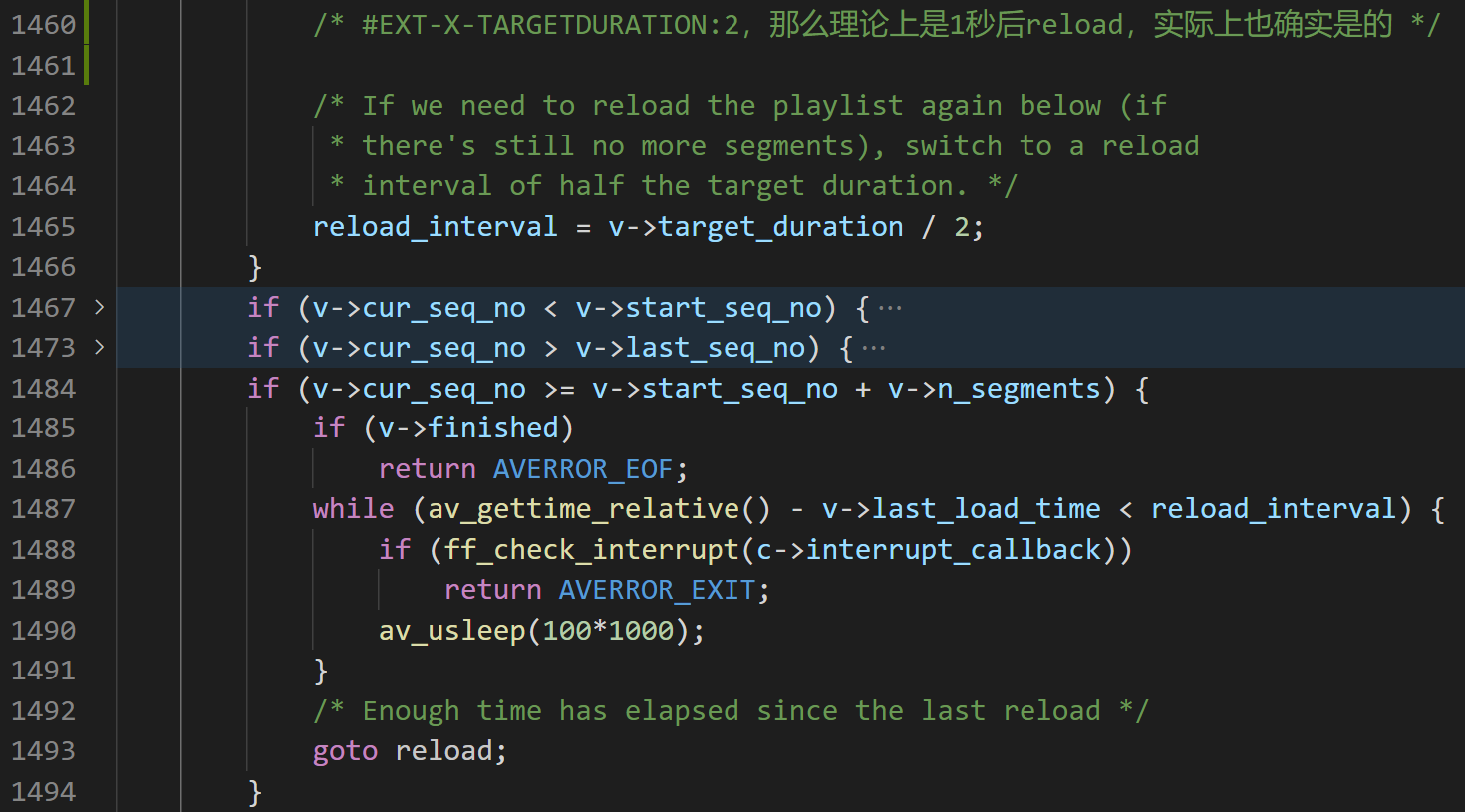
以下代码是hls.c文件里的read_data方法,截图里的中文是我查阅逻辑时写下的部分翻译和注释。
第1442行可以看到正在计算一个reload_interval(重加载间隔)的数值,这个数值取得是HLS协议头里面的数值,在这个流里要么是#EXT-X-TARGETDURATION的2,要么是#EXTINF的2.4,两个数值的单位都是秒。
第1451行在当前实时流的HLS协议内容情况下是必然会进去的,而且在两次加载的间隔大于reload_interval的时候会重新解析palylist(怀疑这里引起的上文关键点2)。这之后1465行又重新计算了reload_interval的值为1秒。
第1487行又会因为和下一次reload时间间隔太短而进行自旋,自旋时长就是reload_interval,之后在1493行跳转reload。

然后我们再看一下抓包的内容,可以看到在序号29的请求发出后到序号31收到回复之间间隔了差不多1.44秒,之后序号31和序号54的再一次请求之间隔了差不多1秒,我大胆猜测这个1秒也就是上文的reload_interval。
除了这一组报文,其实后面的连续报文情况和这一组基本一致。虽然这里的1.44秒明显小于协议中取到reload_interval的2秒或是2.4秒,但是这一组报文实际上是发生问题之后的报文,也就说这里的reload_interval已经是1秒了。
按照这种猜测继续推断的话,那么也就是发生问题时出现了两个请求之间的间隔大于2秒或是2.4秒,然后触发reload并更新reload_interval为1秒,这时后续的请求间隔导致这个reload在一直循环,直到第1447行的判断成立退出。

考虑到HLS是一种实时流,那么这种流的协议肯定是要保证客户端获取到的视频流是实时的,或是接近实时的(延时很大的直播也就没用户体验了)。既然需要接近实时的,那么在获取到playlist里存的是延迟很大的视频帧时肯定是直接丢弃然后获取最新的视频帧了。
在以上的推论下,那么我认为导致ffmpeg解析hls流时出问题的原因有2种可能
- 服务端压力大,回复请求慢,导致获取到过期的playlist
- 服务器所在网络有问题,导致延迟收到了playlist
之后我又发现报文中存在大量的这个报文异常,那么这时我基本确定是因为服务器所在的网络有问题了。

优化措施
根本原因是网络的话,那么肯定首要的是优化网络咯,但是在网络还没优化好之前我也摸索到一个缓解异常的手段(效果不算好,毕竟网络太差什么优化都是徒劳吧)。
这个手段就是设置最大的reload次数,也就是第1447行的max_reload的值。这个值在ffmpeg源码中默认是1000,然后这个值也能被Java层传入的值给覆盖(具体覆盖的逻辑不贴了),如图二的第二行,设置这个值后会改善关键点1的隔几个小时变为几分钟。
图2的第三行是为了减少异常情况下控制台输出的过多日志,也就是类似关键点2中的那个“Skip xxx”的日志。


结论
在通过ffmpeg获取HLS流(其它实时流估计也有可能差不多)时,如果网络环境很差,那么可能会导致Java层的线程挂(hang)在avformat_open_input的native代码上。
参考文章
感想
工作了好几年,这还是第一次被逼到要去翻看底层源代码才能解决问题,虽然看C语言还是有点吃力和难受,不过这次体验还是很不错的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号