
软工第二次作业——数独生成器
数独代码点这里
一、阅读《构建之法》前三章
大致浏览了一下第一章,第一章通常只是介绍一下,本书的结构,以及软件工程的概念。
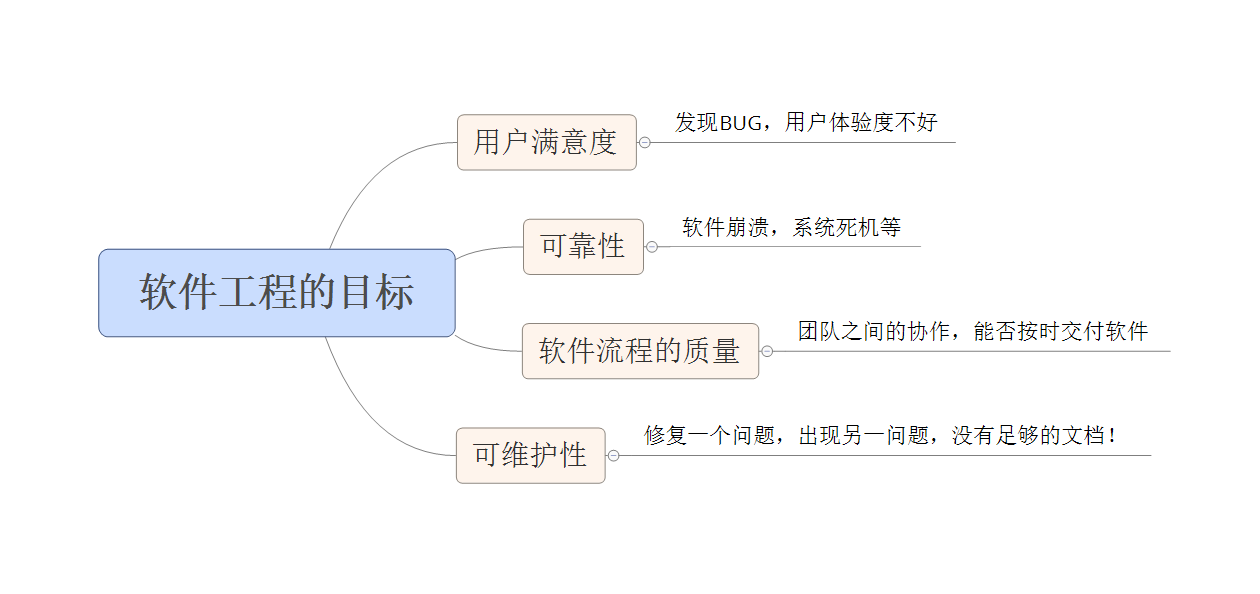
期中我认为比较重要的一点是:软件工程的目标:
第二章主要说的是对代码性能的测试,大概讲了有,单元测试,代码覆盖率。用了一个统计文本文件中最频繁出现的单词数,这个例子很简单,却非常的适合向读者讲述这个问题。
收获最大的一点:不要盲目的“改进”代码,最好在改进之前做一做本章的性能测试,找到花费时间最长的那一部分的函数,对其进行优化会比对排序这样的虽然改进后排序的效率提升,但是对项目的整体并没有太大的影响,从而做了无用功!!
第三章也稍微重点看了一下,本章主要说的是个人的开发流程,作者在里面给读者们用了各种的比喻,把一个软件开发团队,比喻成足球队,把之间的各个流程都进行了相对应的阐述,非常的易于理解。
保存了书中的对个人能力的一张进阶图,非常有帮助!

二、 个人PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 30 |
| · Estimate | · 估计这个任务需要多少时间 | 180 | 360 |
| Development | 开发 | 40 | 40 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 25 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 (和同事审核设计文档) | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 15 | 20 |
| · Design | · 具体设计 | 30 | 60 |
| · Coding | · 具体编码 | 30 | 50 |
| · Code Review | · 代码复审 | 20 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 60 |
| Reporting | 报告 | 10 | 8 |
| · Test Report | · 测试报告 | 10 | 5 |
| · Size Measurement | · 计算工作量 | 180 | 270 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 20 | 10 |
| 合计 | 645 | 988 |
三、代码作业
本次作业,是随机生成N个已解答完毕的数独棋盘。按照新增加的要求,我的棋盘的左上角是7.
示例结果:
7 1 2 3 4 5 6 8 9
3 4 5 6 8 9 1 2 7
6 8 9 1 2 7 3 4 5
1 2 3 7 5 4 9 6 8
9 7 8 2 6 1 4 5 3
4 5 6 8 9 3 2 7 1
2 3 1 5 7 6 8 9 4
5 6 4 9 1 8 7 3 2
8 9 7 4 3 2 5 1 6
解题思路
本体采用回溯法来生成数独棋盘,算法原理来自网上阅读。一开始想到用交叉变换来做,但是发现交叉变化所要做的分治会比较困难,之后网上搜索之后发现,回溯法生成的数独会比较快,也容易产生不同的解
找资料的过程也比较艰难,一开始用百度搜索,但是代码写的都不是很清楚,很难了解到回溯法的使用。最后向同学请教了如何使用谷歌搜索,体验之后才发现有时候英文的搜索会比中文的更加合适。
回溯法介绍(摘自CSDN博客):
回溯法有“通用的解题法”之称。用它可以系统地搜索一个问题的所有解或任一解。回溯法是一个既带有系统性又带有跳跃性的搜索算法。它在包含问题的所有解的解空间树中,按照深度优先的策略,从根节点出发搜索解空间树。算法搜索至解空间树的任一节点时,总是先判断该节点是否肯定不包含问题的解。如果肯定不包含,则跳过对以该节点为根的子树的系统搜索,逐层向其祖先节点回溯。否则,进入该子树,继续按深度优先的策略进行搜索。回溯法在用来求问题的所有解时,要回溯到根,且根节点的所有子树都已被搜索遍才结束。而回溯法在用来求问题的任一解时,只要搜索到问题的一个解就可结束。这种以深度优先的方式系统地搜索问题的解算法称为回溯法,它适用于解一些组合数较大的问题。
代码设计
主要有以下几个函数:
- addelement 向数组中加入元素
- recoverElement 回溯查找函数
- Init 初始化数组
- F——Best 找到最优的解
- check_resultShudu 检测数独代码
- Solve 解数独,采用递归调用回溯
代码说明
关键代码
solveSHudu 判断是否需要回溯,填完一个数字之后,递归进行此操作
bool SolveShudu()
{
int row,column;
if(!F_Best(row,column))
return true;
for(int i=1;i<10;++i)
{
if(!candidate[row][column].test(i))
continue;
AddElement(row,column,i);
if(SolveShudu())
{
if(currentIndex==80 && check_resultShudu())
{
cout<<endl<<"Result:"<<++resultNum<<endl;
printResult();
if(resultNum>=maxNum)
return false;
}
}
else
return false;
RecoverElement(row,column,i);
}
return true;
}
代码的运行结果图
- 分别输入纯数字,非纯数字的运行结果

正确输入的结果:

错误输入的结果:

除了以上的运行结果,最后测试了1000组,一万组的数据,都能够正常的运行。
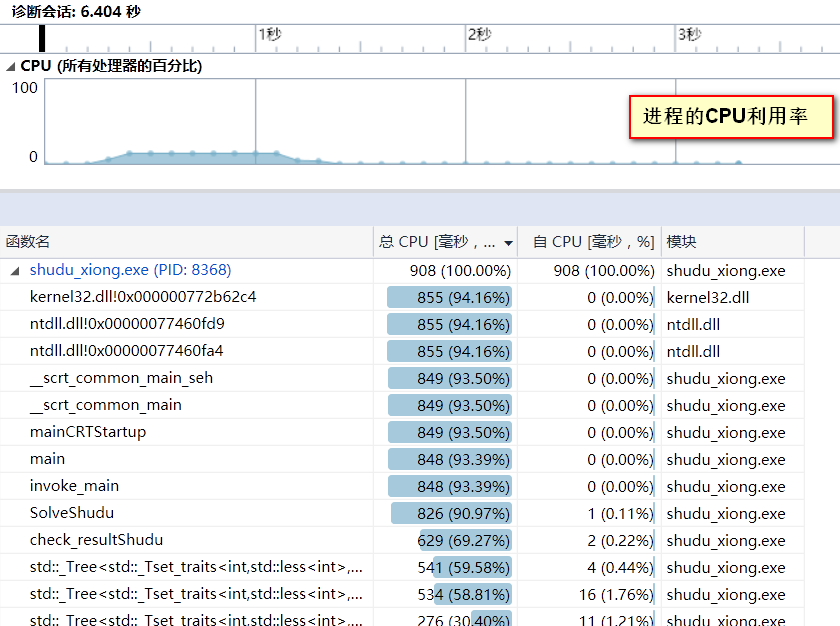
性能分析:
CPU利用率
-
生成100个数独的cpu利用率
-
生成1000个数独的cpu利用率

四、中途遇到的困难
1. 读取命令行参数。
这个问题一开始没有注意到,到了最后一天才知道,不使用控制台进行输入,而是直接用控制台运行带命令行参数的方法来执行。一开始并不知道如何增加命令行参数,最后向同学请教了一下,告诉我要去搜索一下argv argc,我新建了一个小的本地测试项目,花了大约一个小时的时间掌握了读取命令行参数
2. git push 没有把BIN文件夹的exe文件提交上去。
这个问题是在最后写博客贴代码项目的时候发现的,bin文件夹里面有两个文件,一个exe。一个txt,但是之后txt提交上去了,这点让人匪夷所思。多次git重复操作之后发现并没有上传成功。最后通过网页端,直接拖拽上传,把exe文件上传到github上面。
3. 识别非法输入。
一开始识别非法输入,是采取网上的现成代码isnum,对纯数字,纯字母的效果比较好,但是,测到一组混合数字字母的字符串的时候如:123afa,会把这个非纯数字当成123,最后过段放弃使用这个代码。
** 用最基本的遍历判断是否是非法字符**,最后通过基本的遍历,然后通过math函数中的atoi函数把字符串数组转换为数值。
4.文件输入输出
一开是没有用vs敲,先用了以前的dev编译环境来编程。一开始用的是freopen来写入文件,最后发现vs运行调试的时候报错了,要我使用更加安全的freopen_s函数来写入文件。这个的网上教程也是写的非常的生涩,最后找了同学支招,叫我去网上搜索ofstream文件输出流,把文件定向输出到txt中。

