

1 参考文献
【官方指引】https://qwen.readthedocs.io/en/latest/
【ModelScope训练】https://modelscope.cn/docs/%E4%BD%BF%E7%94%A8Tuners
【CUDA下载安装教程】https://blog.csdn.net/changyana/article/details/135876568
【安装PyTorch】https://pytorch.org/
【安装Ollama】https://ollama.com/download
2 基础环境
2.1 安装CUDA
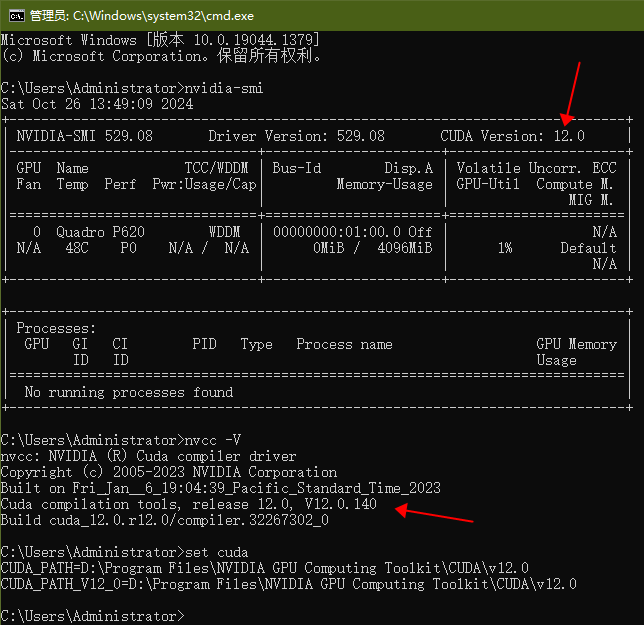
【查看显卡驱动】nvidia-smi
【验证CUDA安装】nvcc -V
首先查看NVIDIA显卡对应的CUDA版本号,然后根据此版本号下载对应版本的Toolkit(安装完Toolkit就会有nvcc)
CUDA Toolkit Archive:https://developer.nvidia.com/cuda-toolkit-archive
2.2 安装cuDNN
cuDNN(CUDA Deep Neural Network library) 是由 NVIDIA 提供的一个用于深度神经网络的 GPU 加速库。
cuDNN 不是 CUDA Toolkit 的直接组成部分,但它依赖于 CUDA Toolkit 提供的基础架构来运行。为了使用 cuDNN,需要先安装兼容版本的 CUDA Toolkit。因为 cuDNN 利用了 CUDA 的核心功能来执行深度学习运算,并且需要与特定版本的 CUDA 兼容才能正常工作。
【安装cuDNN】https://developer.nvidia.com/rdp/cudnn-archive
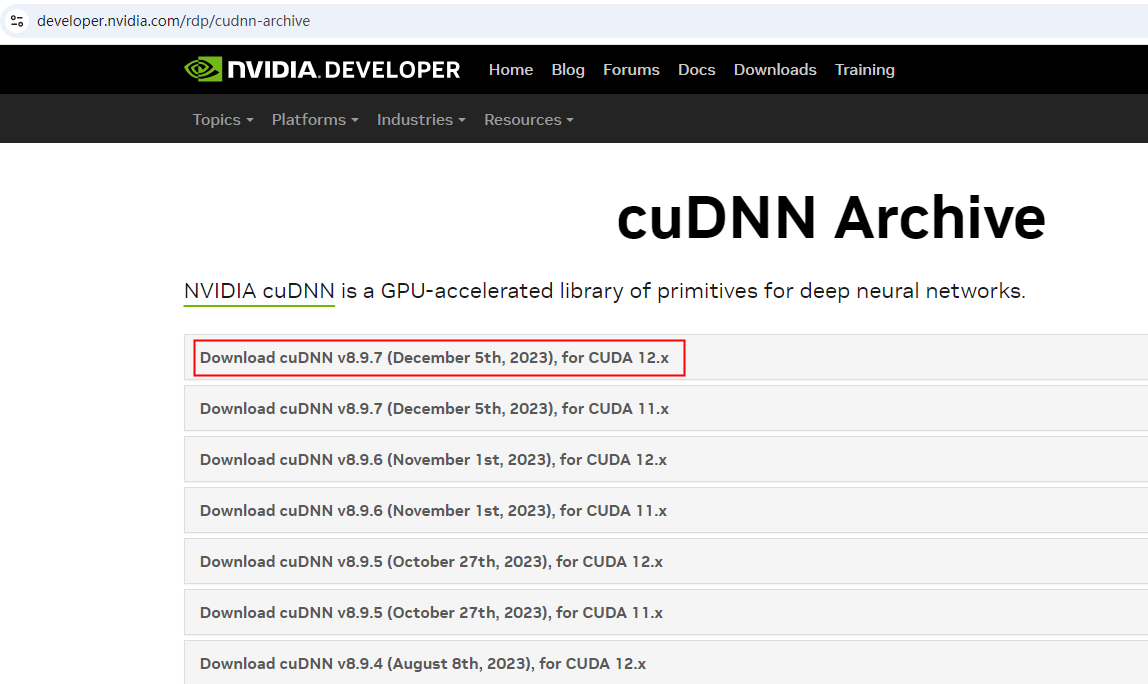
把下载的cudnn压缩包进行解压,在cudnn的文件夹下,把bin,include,lib文件夹下的内容对应拷贝到cuda相应的bin,include,lib下即可,最后安装完成。
2.3 安装PyTorch
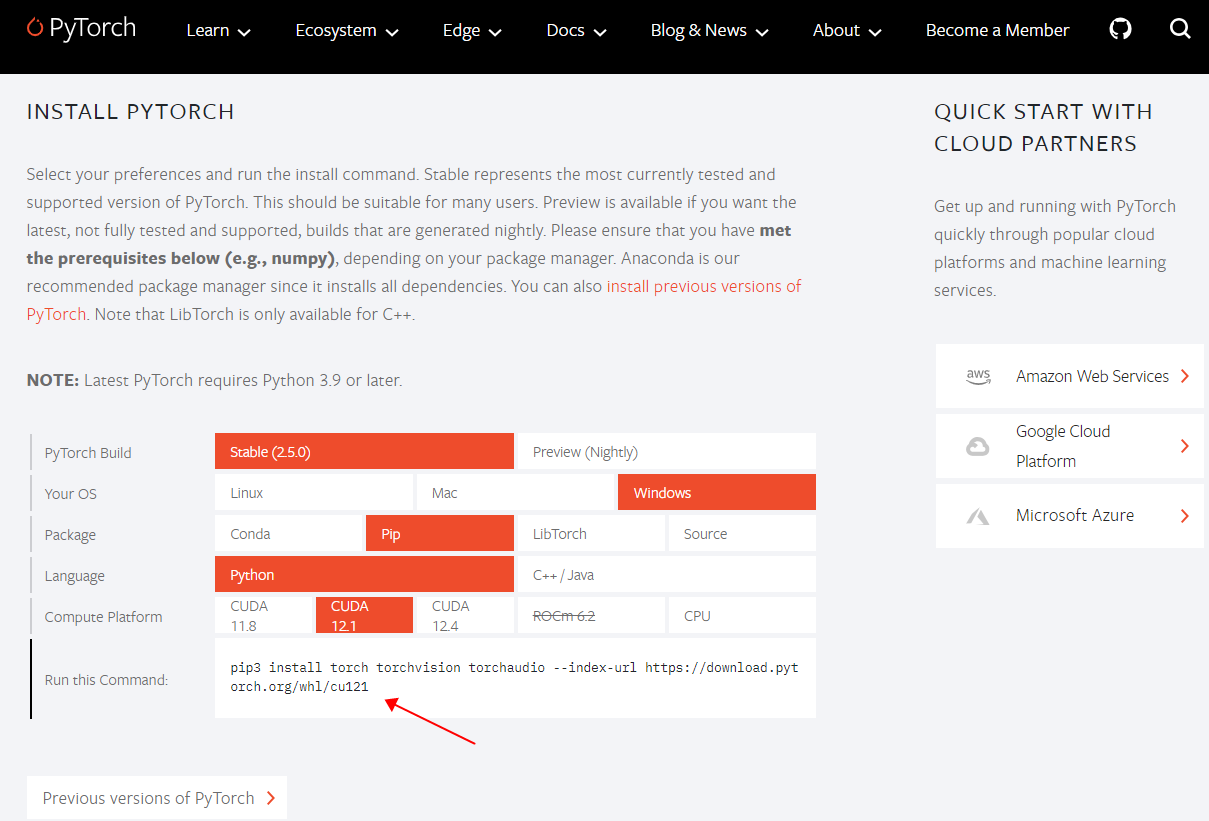
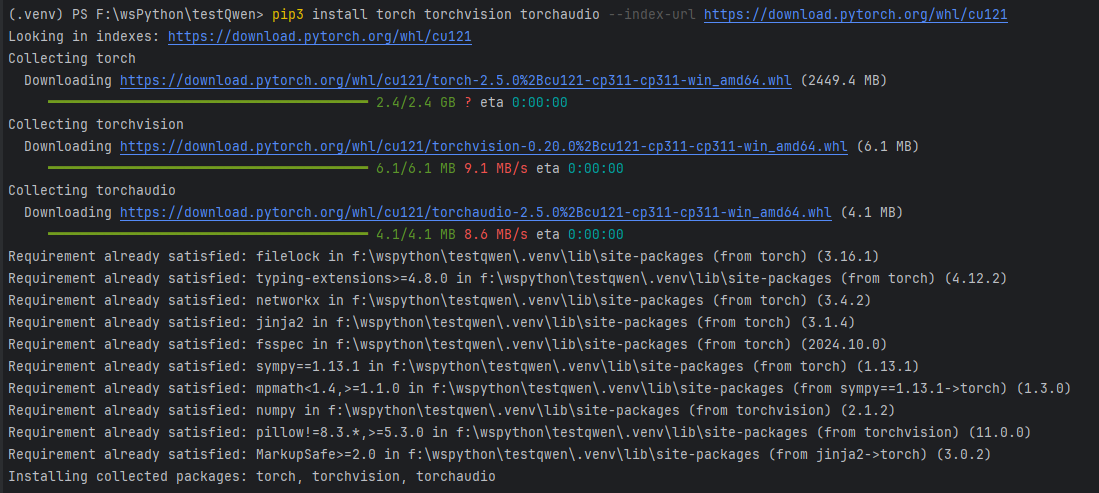
# 验证PyTorch是否与CUDA兼容 import torch print(torch.__version__) print(torch.cuda.is_available()) # 如果没有按照上述的命令安装torch则很可能因版本不匹配而显示False
3 通过Ollama调用模型
Ollama是一种比较简单方便的本地运行方案。通过Ollama官网直接安装,可搜索支持的大模型:https://ollama.com/search?q=qwen
4 Qwen官方指引
Qwen官方指南详细说明了支持的各种方案,比查看各种网络博客说明更清晰。

5 自定义训练
5.1 参考ModelScope指引
# 自定义ModelScope模型缓存路径
export MODELSCOPE_CACHE=/Users/kuliuheng/workspace/aiWorkspace/Qwen


1 # A100 18G memory 2 from swift import Seq2SeqTrainer, Seq2SeqTrainingArguments 3 from modelscope import MsDataset, AutoTokenizer 4 from modelscope import AutoModelForCausalLM 5 from swift import Swift, LoraConfig 6 from swift.llm import get_template, TemplateType 7 import torch 8 9 pretrained_model = 'qwen/Qwen2.5-0.5B-Instruct' 10 11 12 def encode(example): 13 inst, inp, output = example['instruction'], example.get('input', None), example['output'] 14 if output is None: 15 return {} 16 if inp is None or len(inp) == 0: 17 q = inst 18 else: 19 q = f'{inst}\n{inp}' 20 example, kwargs = template.encode({'query': q, 'response': output}) 21 return example 22 23 24 if __name__ == '__main__': 25 # 拉起模型 26 model = AutoModelForCausalLM.from_pretrained(pretrained_model, torch_dtype=torch.bfloat16, device_map='auto', trust_remote_code=True) 27 lora_config = LoraConfig( 28 r=8, 29 bias='none', 30 task_type="CAUSAL_LM", 31 target_modules=["q_proj", "k_proj", "v_proj", "o_proj"], 32 lora_alpha=32, 33 lora_dropout=0.05) 34 model = Swift.prepare_model(model, lora_config) 35 tokenizer = AutoTokenizer.from_pretrained(pretrained_model, trust_remote_code=True) 36 dataset = MsDataset.load('AI-ModelScope/alpaca-gpt4-data-en', split='train') 37 template = get_template(TemplateType.chatglm3, tokenizer, max_length=1024) 38 39 dataset = dataset.map(encode).filter(lambda e: e.get('input_ids')) 40 dataset = dataset.train_test_split(test_size=0.001) 41 42 train_dataset, val_dataset = dataset['train'], dataset['test'] 43 44 train_args = Seq2SeqTrainingArguments( 45 output_dir='output', 46 learning_rate=1e-4, 47 num_train_epochs=2, 48 eval_steps=500, 49 save_steps=500, 50 evaluation_strategy='steps', 51 save_strategy='steps', 52 dataloader_num_workers=4, 53 per_device_train_batch_size=1, 54 gradient_accumulation_steps=16, 55 logging_steps=10, 56 ) 57 58 trainer = Seq2SeqTrainer( 59 model=model, 60 args=train_args, 61 data_collator=template.data_collator, 62 train_dataset=train_dataset, 63 eval_dataset=val_dataset, 64 tokenizer=tokenizer) 65 66 trainer.train()
(1)官方示例代码中没有写 __main__ 主函数入口,实际运行时发现会报错提示说:子线程在主线程尚未完成初始化之前就运行了。 所以这里就补齐了一个主函数入口
(2)官方代码中没有针对 'qwen/Qwen2.5-0.5B-Instruct' 模型代码,运行时target_modules会提示错误,需要指定模型中实际存在的模块名才行。这里有个技巧,通过打印模型信息可以看到实际的层级结构:
from modelscope import AutoModelForCausalLM model_name = 'qwen/Qwen2.5-0.5B-Instruct' model = AutoModelForCausalLM.from_pretrained(model_name) print(model)
得到如下结果:
Qwen2ForCausalLM( (model): Qwen2Model( (embed_tokens): Embedding(151936, 896) (layers): ModuleList( (0-23): 24 x Qwen2DecoderLayer( (self_attn): Qwen2SdpaAttention( (q_proj): Linear(in_features=896, out_features=896, bias=True) (k_proj): Linear(in_features=896, out_features=128, bias=True) (v_proj): Linear(in_features=896, out_features=128, bias=True) (o_proj): Linear(in_features=896, out_features=896, bias=False) (rotary_emb): Qwen2RotaryEmbedding() ) (mlp): Qwen2MLP( (gate_proj): Linear(in_features=896, out_features=4864, bias=False) (up_proj): Linear(in_features=896, out_features=4864, bias=False) (down_proj): Linear(in_features=4864, out_features=896, bias=False) (act_fn): SiLU() ) (input_layernorm): Qwen2RMSNorm((896,), eps=1e-06) (post_attention_layernorm): Qwen2RMSNorm((896,), eps=1e-06) ) ) (norm): Qwen2RMSNorm((896,), eps=1e-06) (rotary_emb): Qwen2RotaryEmbedding() ) (lm_head): Linear(in_features=896, out_features=151936, bias=False) )
调整目标模块名之后,代码能够跑起来了,但Mac Apple M3笔记本上跑,的确是速度太慢了点:
[INFO:swift] Successfully registered `/Users/kuliuheng/workspace/aiWorkspace/Qwen/testMS/.venv/lib/python3.10/site-packages/swift/llm/data/dataset_info.json` [INFO:swift] No vLLM installed, if you are using vLLM, you will get `ImportError: cannot import name 'get_vllm_engine' from 'swift.llm'` [INFO:swift] No LMDeploy installed, if you are using LMDeploy, you will get `ImportError: cannot import name 'prepare_lmdeploy_engine_template' from 'swift.llm'` Train: 0%| | 10/6492 [03:27<42:38:59, 23.69s/it]{'loss': 20.66802063, 'acc': 0.66078668, 'grad_norm': 30.34488869, 'learning_rate': 9.985e-05, 'memory(GiB)': 0, 'train_speed(iter/s)': 0.048214, 'epoch': 0.0, 'global_step/max_steps': '10/6492', 'percentage': '0.15%', 'elapsed_time': '3m 27s', 'remaining_time': '1d 13h 21m 21s'} Train: 0%| | 20/6492 [23:05<477:25:15, 265.56s/it]{'loss': 21.01838379, 'acc': 0.66624489, 'grad_norm': 23.78275299, 'learning_rate': 9.969e-05, 'memory(GiB)': 0, 'train_speed(iter/s)': 0.014436, 'epoch': 0.01, 'global_step/max_steps': '20/6492', 'percentage': '0.31%', 'elapsed_time': '23m 5s', 'remaining_time': '5d 4h 31m 21s'} Train: 0%| | 30/6492 [29:48<66:31:55, 37.07s/it]{'loss': 20.372052, 'acc': 0.67057648, 'grad_norm': 38.68712616, 'learning_rate': 9.954e-05, 'memory(GiB)': 0, 'train_speed(iter/s)': 0.016769, 'epoch': 0.01, 'global_step/max_steps': '30/6492', 'percentage': '0.46%', 'elapsed_time': '29m 48s', 'remaining_time': '4d 11h 2m 20s'} Train: 1%| | 40/6492 [36:00<62:35:16, 34.92s/it]{'loss': 20.92590179, 'acc': 0.66806035, 'grad_norm': 38.17282486, 'learning_rate': 9.938e-05, 'memory(GiB)': 0, 'train_speed(iter/s)': 0.018514, 'epoch': 0.01, 'global_step/max_steps': '40/6492', 'percentage': '0.62%', 'elapsed_time': '36m 0s', 'remaining_time': '4d 0h 48m 3s'} Train: 1%| | 50/6492 [42:23<60:03:47, 33.57s/it]{'loss': 19.25114594, 'acc': 0.68523092, 'grad_norm': 37.24295807, 'learning_rate': 9.923e-05, 'memory(GiB)': 0, 'train_speed(iter/s)': 0.01966, 'epoch': 0.02, 'global_step/max_steps': '50/6492', 'percentage': '0.77%', 'elapsed_time': '42m 23s', 'remaining_time': '3d 19h 1m 0s'} Train: 1%| | 60/6492 [47:45<54:01:41, 30.24s/it]{'loss': 19.54689178, 'acc': 0.69552717, 'grad_norm': 27.87804794, 'learning_rate': 9.908e-05, 'memory(GiB)': 0, 'train_speed(iter/s)': 0.020941, 'epoch': 0.02, 'global_step/max_steps': '60/6492', 'percentage': '0.92%', 'elapsed_time': '47m 45s', 'remaining_time': '3d 13h 19m 3s'} Train: 1%| | 65/6492 [50:38<64:46:05, 36.28s/it]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号