

【工具使用】【Shell脚本】【gitlab】【最终篇】获取当前用户页面上可以看到的所有仓库代码以及拉推新仓库
1 前言
前边我写过 【工具使用】【Shell脚本】【gitlab】下拉所有的仓库代码并指定分支推送给客户仓库 以及 【工具使用】【Shell脚本】【gitlab】下拉所有的仓库代码,其中都有一个获取所有的仓库代码并且上一篇拉下所有的仓库并推送给客户仓库里唯一剩下的问题就是获取所有的仓库感觉不全,比如页面上的跟接口里的返回的不一样,有的页面上看不到的接口里却有返回。嘿嘿,经过我翻官网的 API 说明以及它的源码(源码是 Ruby + Go 写的,Go我还能看懂,Ruby 实在没看懂没观察到什么)下边会说解决办法,最终是得到页面上能看到多少仓库接口就能获取到多少仓库,本节我们采用问答的形式,描述一下过程,最后我会贴一个完整的获取所有仓库的脚本。
参考:Gitlab API 文档、Gitlab Projects API 文档、Gitlab Projects 源码
Gitlab 版本:13.12.15
Projects 接口参数:

2 问答
我们先看下之前脚本请求的路径:/api/v4/projects?per_page=9999
为什么上边的这个获取不到所有的仓库?
这个我看文档里说了,针对 API 的分页接口,默认分页大小为 20 最大是 100,所以即使你设置 9999 也只会最多返回 100 个,所以当你的仓库比较多的时候,其实只拿到了一页的数据。
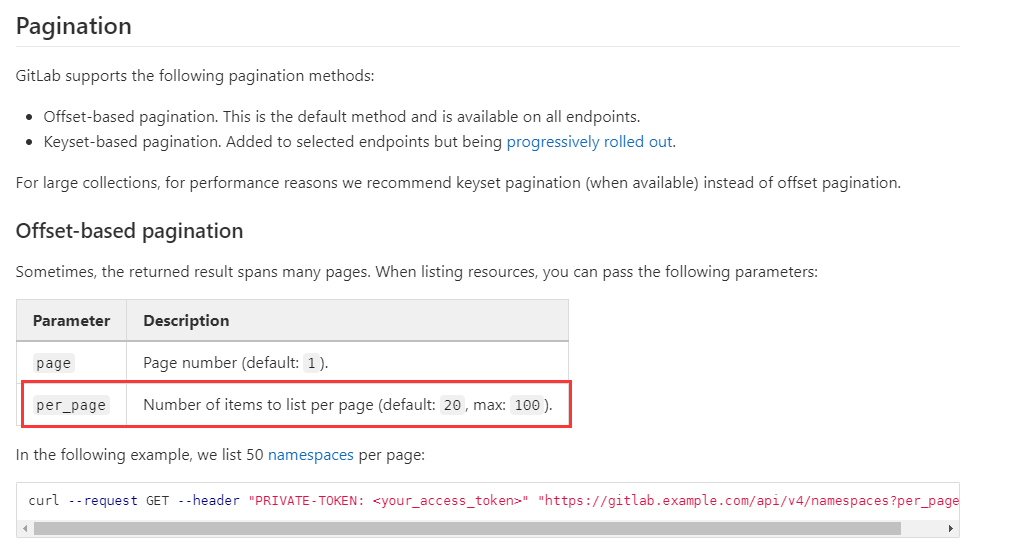
为什么页面上我没看到某个仓库,但是接口里边却返回了这个仓库呢?或者为什么接口返回的仓库要比页面上多呢?

这个我首先看一看它页面的请求,想从请求中发现他请求的参数是不是跟我的有一些不一样,我拿着页面的请求参数试了一下,其实不行。

那我就想是不是他代码里做了什么处理呢?然后我就想去翻他背后的源码,大概位置倒是能找到,但是奈何 Ruby 这语言看不太懂,比如一些方法从哪引进来的呢?这着实有点头疼,这条路或许能走通,但是很耗时间还不一定能找到。

然后我就简单的比较了一下页面上看不到的某个仓库,但是接口却返回了某个仓库的数据,我就对两个数据的 JSON 进行了一下比较,嘿嘿发现了一点端倪:

就是这个 visibility 接口里会返回公共的仓库,所以说页面上看不到,接口里却返回的比较多,再看接口的文档也确实有这个参数:

然后我就把路径后边拼上 /api/v4/projects?per_page=9999&visibility=private,看效果,接口和页面上能看到的仓库数量就一致了。

这也是一种办法,通过比较结果数据去找原因。
最后出于强迫症的我,还想再追求一下页面的仓库顺序和接口返回的顺序一致,这个怎么做呢?
这个看接口文档有排序字段以及排序方式,这个我就是尝试,一个个试,最后发现页面的排序是根据 path 以及 asc 升序来做的,感兴趣的可以自己试试。
api/v4/projects?per_page=9999&visibility=private&sort=asc&order_by=path

好啦,到这里这个接口的数量跟页面一致以及顺序性就都差不多了。
3 完整脚本
接口是分页,那么要想获取所有的仓库信息的话,有两种:
- 官网或者一些博客说的是根据响应头里的总页数,然后遍历去获取,这个我试了,不好使没用。

- 根据响应结果为空,结束获取,也就是我每次就获取100个 直到接口返回的为空,那就说明没有了,就结束掉。
所以我这里的脚本是根据第二种方式写的。

#!/bin/bash # 仓库地址 GIT_HOST="xxxx" # 仓库Token GIT_ACCESS_TOKEN="xxx" # 获取所有的项目信息 # 分页信息 每次获取100个 page=1 per_page=100 # 一直获取 while : ; do # 获取数据 echo "获取第 $page 页数据" url="$GIT_HOST/api/v4/projects?page=${page}&per_page=${per_page}&visibility=private&order_by=path&sort=asc" response=$(curl -H "PRIVATE-TOKEN:$GIT_ACCESS_TOKEN" -H "Content-Type: application/json" "${url}") # 没有数据的话默认会返回 [] 所以我们这里直接判断长度小于等于2 就说明没有了 if [ ${#response} -le 2 ]; then echo "没有更多了,结束" break fi # 处理返回的 JSON 数据 part_json=$(echo "${response}" | jq 'map({id, name, path_with_namespace, ssh_url_to_repo})') # 我们这里就简单打印一下 echo $part_json | jq -r '.[] | [.id, .name] | @tsv' | while IFS=$'\t' read -r id name; do echo "id: $id, name: $name" done # 页数++ : $((page++)) done
打印仓库id 名称的信息我抹掉了哈,执行效果:
再贴一个拉推仓库的,大家可以试试:
#!/bin/bash # 仓库地址 GIT_HOST="xxx" # 仓库Token GIT_ACCESS_TOKEN="xxx" # 新旧仓库 SSH 前缀 GIT_OLD_SSH_PREFIX="ssh://git@xxx:23" GIT_NEW_SSH_PREFIX="git@xxxx/x/xx" # 获取所有的项目信息 # 分页信息 每次获取100个 page=1 per_page=100 # 总仓库数 total=0 # 一直获取 while : ; do # 获取数据并存储到 data.json 中 echo "获取第 $page 页数据" url="$GIT_HOST/api/v4/projects?page=${page}&per_page=${per_page}&visibility=private&order_by=path&sort=asc" curl -H "PRIVATE-TOKEN:$GIT_ACCESS_TOKEN" -H "Content-Type: application/json" "${url}" > data.json # 提取每个仓库的 ssh地址 ssh_url_to_repo part_projects=$(cat data.json | jq '.[].ssh_url_to_repo') # 处理返回的 JSON 数据 仅获取 id, name, path_with_namespace, ssh_url_to_repo 四个属性 # 暂时不用,发现这样后续不好处理 # part_json=$(echo "${response}" | jq 'map({id, name, path_with_namespace, ssh_url_to_repo})') # 没有数据的话默认会返回 [] 所以我们这里直接判断长度小于等于2 就说明没有了 if [ ${#part_projects} -le 2 ]; then echo "没有更多了,结束" break fi # 遍历处理 for project in $part_projects do # 仓库计数器++ ((total++)) # 去掉双引号 project=`echo $project | sed -e 's/"//g'` echo "$total-ssh地址:$project" # 可以根据路径这里加一些筛选 # 比如不是 $GIT_OLD_SSH_PREFIX/xx 前缀开头的 if [[ $project != $GIT_OLD_SSH_PREFIX/xx* ]]; then echo "$total-$project 路径不符合过滤掉" continue fi # 截取最后文件名 比如 ssh://git@xxx:23/xx/abc.git 得到 abc file_name=$(basename "$project" .git) echo "$total-文件名:$file_name" # 可以根据名字这里加一些筛选 # 比如名称中不包含 adapter 的 if [[ $file_name != *adapter* ]]; then echo "$total-$file_name 名称不符合过滤掉" continue fi # 先删除再拉取仓库 rm -rf $project git clone $project # 进入仓库 cd $file_name # 添加新的远程仓库 new_origin=`echo $GIT_NEW_SSH_PREFIX/$file_name.git` echo "$total-新仓库ssh地址:$new_origin" git remote add new_origin $new_origin # 获取指定分支并推送 # master 分支 if git branch -r | grep -q 'origin/master'; then echo "$total-存在 master 分支" git checkout master git push new_origin echo "$total-已推送新仓库 master 分支" fi # test 分支 if git branch -r | grep -q 'origin/test'; then echo "$total-存在 test 分支" git checkout test git push new_origin echo "$total-已推送新仓库 test 分支" fi # 回退上一级目录 cd .. # 删除本地仓库文件 rm -rf $project # !!!先测试一个,可以的话再注释掉这个 break break done # 页数++ 继续拉取下一页 ((page++)) done # 打印 echo "总共获取到: $total 个仓库"
4 小结
技术没有捷径,不会就多尝试哈,有理解不对的地方欢迎指正。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享4款.NET开源、免费、实用的商城系统
· 全程不用写代码,我用AI程序员写了一个飞机大战
· Obsidian + DeepSeek:免费 AI 助力你的知识管理,让你的笔记飞起来!
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了