【网络】【TCP】TCP 连接,一端断电和进程崩溃有什么区别?
1 前言
这节我们来看个问题,就是 TCP 连接,一端断电和进程崩溃有什么区别?
这个属于 TCP 异常断开连接的场景,这部分内容在我的「图解网络」还没有详细介绍过,这次就乘着这次机会补一补。
这个问题有几个关键词:
- 没有开启 keepalive;
- 一直没有数据交互;
- 进程崩溃;
- 主机崩溃;
我们先来认识认识什么是 TCP keepalive 呢?
这东西其实就是 TCP 的保活机制,它的工作原理我之前的文章写过,这里就直接贴下以前的内容。

如果两端的 TCP 连接一直没有数据交互,达到了触发 TCP 保活机制的条件,那么内核里的 TCP 协议栈就会发送探测报文。
- 如果对端程序是正常工作的。当 TCP 保活的探测报文发送给对端, 对端会正常响应,这样 TCP 保活时间会被重置,等待下一个 TCP 保活时间的到来。
- 如果对端主机崩溃,或对端由于其他原因导致报文不可达。当 TCP 保活的探测报文发送给对端后,石沉大海,没有响应,连续几次,达到保活探测次数后,TCP 会报告该 TCP 连接已经死亡。
所以,TCP 保活机制可以在双方没有数据交互的情况,通过探测报文,来确定对方的 TCP 连接是否存活。
SO_KEEPALIVE 选项才能够生效,如果没有设置,那么就无法使用 TCP 保活机制。2 主机崩溃
知道了 TCP keepalive 作用,我们再回过头看题目中的「主机崩溃」这种情况。
在没有开启 TCP keepalive,且双方一直没有数据交互的情况下,如果客户端的「主机崩溃」了,会发生什么。
客户端主机崩溃了,服务端是无法感知到的,在加上服务端没有开启 TCP keepalive,又没有数据交互的情况下,服务端的 TCP 连接将会一直处于 ESTABLISHED 连接状态,直到服务端重启进程。
所以,我们可以得知一个点,在没有使用 TCP 保活机制且双方不传输数据的情况下,一方的 TCP 连接处在 ESTABLISHED 状态,并不代表另一方的连接还一定正常。
3 进程崩溃
那题目中的「进程崩溃」的情况呢?
TCP 的连接信息是由内核维护的,所以当服务端的进程崩溃后,内核需要回收该进程的所有 TCP 连接资源,于是内核会发送第一次挥手 FIN 报文,后续的挥手过程也都是在内核完成,并不需要进程的参与,所以即使服务端的进程退出了,还是能与客户端完成 TCP四次挥手的过程。
我自己做了实验,使用 kill -9 来模拟进程崩溃的情况,发现在 kill 掉进程后,服务端会发送 FIN 报文,与客户端进行四次挥手。
所以,即使没有开启 TCP keepalive,且双方也没有数据交互的情况下,如果其中一方的进程发生了崩溃,这个过程操作系统是可以感知的到的,于是就会发送 FIN 报文给对方,然后与对方进行 TCP 四次挥手。
4 有数据传输的场景
接下来我们看看在「有数据传输」的场景下的一些异常情况:
- 第一种,客户端主机宕机,又迅速重启,会发生什么?
- 第二种,客户端主机宕机,一直没有重启,会发生什么?
4.1 客户端主机宕机,又迅速重启
在客户端主机宕机后,服务端向客户端发送的报文会得不到任何的响应,在一定时长后,服务端就会触发超时重传机制,重传未得到响应的报文。
服务端重传报文的过程中,客户端主机重启完成后,客户端的内核就会接收重传的报文,然后根据报文的信息传递给对应的进程:
- 如果客户端主机上没有进程绑定该 TCP 报文的目标端口号,那么客户端内核就会回复 RST 报文,重置该 TCP 连接;
- 如果客户端主机上有进程绑定该 TCP 报文的目标端口号,由于客户端主机重启后,之前的 TCP 连接的数据结构已经丢失了,客户端内核里协议栈会发现找不到该 TCP 连接的 socket 结构体,于是就会回复 RST 报文,重置该 TCP 连接。
所以,只要有一方重启完成后,收到之前 TCP 连接的报文,都会回复 RST 报文,以断开连接。
4.2 客户端主机宕机,一直没有重启
这种情况,服务端超时重传报文的次数达到一定阈值后,内核就会判定出该 TCP 有问题,然后通过 Socket 接口告诉应用程序该 TCP 连接出问题了,于是服务端的 TCP 连接就会断开。
那 TCP 的数据报文具体重传几次呢?
在 Linux 系统中,提供一个叫 tcp_retries2 配置项,默认值是 15,如下图:

这个内核参数是控制,在 TCP 连接建立的情况下,超时重传的最大次数。
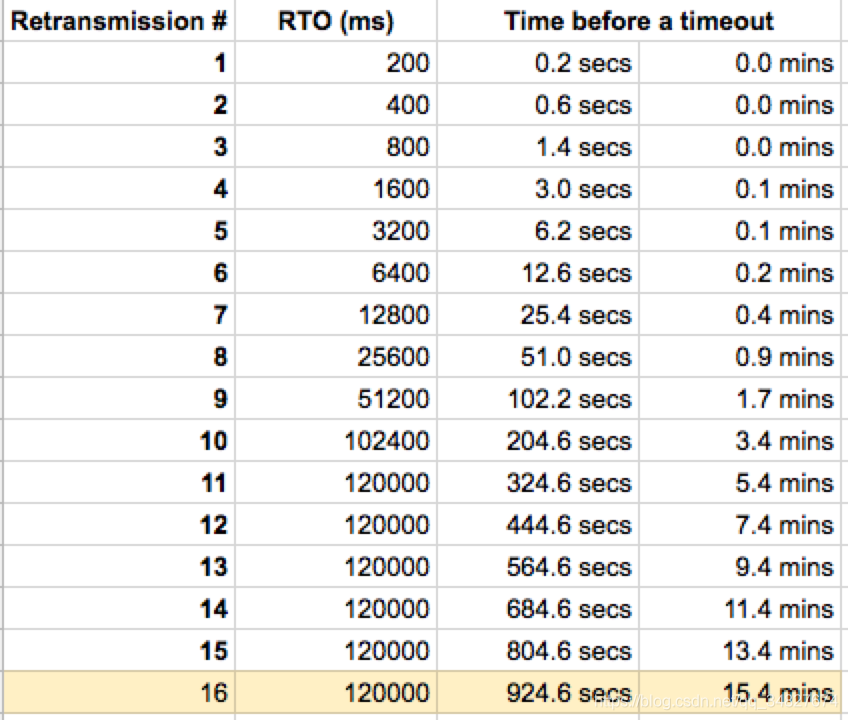
不过 tcp_retries2 设置了 15 次,并不代表 TCP 超时重传了 15 次才会通知应用程序终止该 TCP 连接,内核会根据 tcp_retries2 设置的值,计算出一个 timeout(如果 tcp_retries2 =15,那么计算得到的 timeout = 924600 ms),如果重传间隔超过这个 timeout,则认为超过了阈值,就会停止重传,然后就会断开 TCP 连接。
在发生超时重传的过程中,每一轮的超时时间(RTO)都是倍数增长的,比如如果第一轮 RTO 是 200 毫秒,那么第二轮 RTO 是 400 毫秒,第三轮 RTO 是 800 毫秒,以此类推。
而 RTO 是基于 RTT(一个包的往返时间) 来计算的,如果 RTT 较大,那么计算出来的 RTO 就越大,那么经过几轮重传后,很快就达到了上面的 timeout 值了。
举个例子,如果 tcp_retries2 =15,那么计算得到的 timeout = 924600 ms,如果重传总间隔时长达到了 timeout 就会停止重传,然后就会断开 TCP 连接:
- 如果 RTT 比较小,那么 RTO 初始值就约等于下限 200ms,也就是第一轮的超时时间是 200 毫秒,由于 timeout 总时长是 924600 ms,表现出来的现象刚好就是重传了 15 次,超过了 timeout 值,从而断开 TCP 连接
- 如果 RTT 比较大,假设 RTO 初始值计算得到的是 1000 ms,也就是第一轮的超时时间是 1 秒,那么根本不需要重传 15 次,重传总间隔就会超过 924600 ms。
最小 RTO 和最大 RTO 是在 Linux 内核中定义好了:
#define TCP_RTO_MAX ((unsigned)(120*HZ)) #define TCP_RTO_MIN ((unsigned)(HZ/5))
Linux 2.6+ 使用 1000 毫秒的 HZ,因此TCP_RTO_MIN约为 200 毫秒,TCP_RTO_MAX约为 120 秒。
如果tcp_retries设置为15,且 RTT 比较小,那么 RTO 初始值就约等于下限 200ms,这意味着它需要 924.6 秒才能将断开的 TCP 连接通知给上层(即应用程序),每一轮的 RTO 增长关系如下表格:
5 小结
如果「客户端进程崩溃」,客户端的进程在发生崩溃的时候,内核会发送 FIN 报文,与服务端进行四次挥手。
但是,「客户端主机宕机」,那么是不会发生四次挥手的,具体后续会发生什么?还要看服务端会不会发送数据?
- 如果服务端会发送数据,由于客户端已经不存在,收不到数据报文的响应报文,服务端的数据报文会超时重传,当重传总间隔时长达到一定阈值(内核会根据 tcp_retries2 设置的值计算出一个阈值)后,会断开 TCP 连接;
- 如果服务端一直不会发送数据,再看服务端有没有开启 TCP keepalive 机制?
- 如果有开启,服务端在一段时间没有进行数据交互时,会触发 TCP keepalive 机制,探测对方是否存在,如果探测到对方已经消亡,则会断开自身的 TCP 连接;
- 如果没有开启,服务端的 TCP 连接会一直存在,并且一直保持在 ESTABLISHED 状态。
最后说句,TCP 牛逼,啥异常都考虑到了,好啦,本节我们就看到这里哈,有理解不对的地方欢迎指正哈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号