redis源码--字典
一, 图解
字典的实现
Redis的字典使用哈希表作为底层实现,一个哈希表里面可以有多个哈希表节点,而每个哈希表节点就保存了字典中的一个键值对。
接下来分别介绍Redis的哈希表、哈希表节点以及字典的实现。
哈希表
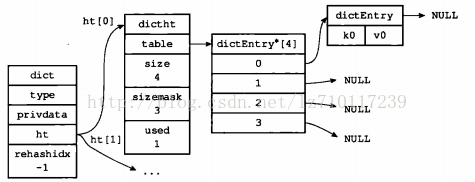
Redis字典所使用的哈希表由dict.h/dictht结构定义:
/*
* 哈希表
*
* 每个字典都使用两个哈希表,从而实现渐进式 rehash 。
*/
typedef struct dictht {
// 哈希表数组
dictEntry **table;
// 哈希表大小
unsigned long size;
// 哈希表大小掩码,用于计算索引值
// 总是等于 size - 1
unsigned long sizemask;
// 该哈希表已有节点的数量
unsigned long used;
} dictht;
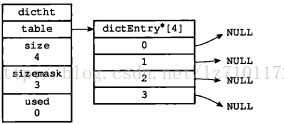
table属性是一个数组,数组中的每个元素都是一个指向dict.h/dicEntry结构的指针,每个dictEntry结构保存着一个键值对。size属性记录了哈希表的大小,也即是table数组的大小,而used属性则记录了哈希表目前已有节点(键值对)的数量。sizemask属性的值总是等于size-1,这个属性和哈希值一起决定一个键应该被放到table数组的哪个索引上面。下图展示了一个大小为4的空哈希表:
哈希表节点
哈希表节点使用dictEntry结构表示,每个dictEntry结构都保存着一个键值对:
/*
* 哈希表节点
*/
typedef struct dictEntry {
// 键
void *key;
// 值
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
// 指向下个哈希表节点,形成链表
struct dictEntry *next;
} dictEntry;key属性保存着键值对中的键,而v属性则保存着键值对中的值,其中键值对的值可以是一个指针,或者是一个unit64_t整数,又或者是一个int64_t整数。
netx属性是指向另一个哈希表节点的指针,这个指针可以将多个哈希值相同的键值对连接在一起,以此来解决键冲突(collision)的问题。
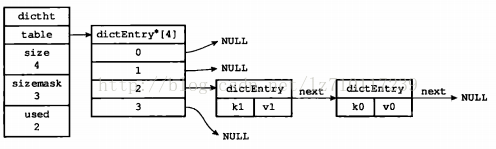
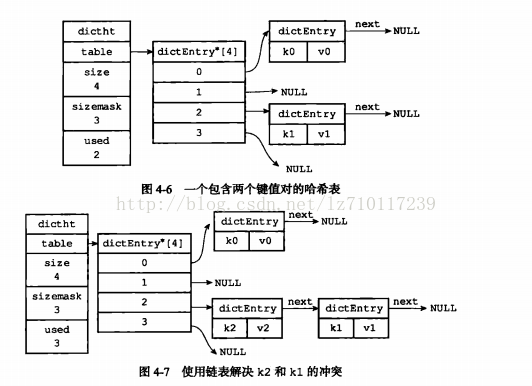
举个例子,下图就展示了如何通过next指针,将两个索引值相同的键K1和K0连接在一起。
字典
Redis中的字典由dict.h/dict结构表示:
/*
* 字典
*/
typedef struct dict {
// 类型特定函数
dictType *type;
// 私有数据
void *privdata;
// 哈希表
dictht ht[2];
// rehash 索引
// 当 rehash 不在进行时,值为 -1
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
// 目前正在运行的安全迭代器的数量
int iterators; /* number of iterators currently running */
} dict;type属性和privdata属性是针对不同类型的键值对,为创建多态字典而设置的:
- type属性是一个指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定类型键值对的函数,Redis会为用途不同的字典设置不同的类型特定函数。
- 而privdata属性则保存了需要传给那些类型特定函数的可选参数。
/*
* 字典类型特定函数
*/
typedef struct dictType {
// 计算哈希值的函数
unsigned int (*hashFunction)(const void *key);
// 复制键的函数
void *(*keyDup)(void *privdata, const void *key);
// 复制值的函数
void *(*valDup)(void *privdata, const void *obj);
// 对比键的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
// 销毁键的函数
void (*keyDestructor)(void *privdata, void *key);
// 销毁值的函数
void (*valDestructor)(void *privdata, void *obj);
} dictType;ht属性是一个包含两个项的数组,数组中的每个项都是一个dictht哈希表,一般情况下,字典只使用ht[0]哈希表,ht[1]哈希表只会在对ht[0]哈希表进行rehash时使用。
除了ht[1]之外,另一个和rehash有关的属性就是rehashidx,它记录了rehash目前的进度,如果目前没有在进行rehash,那么它的值为-1.。
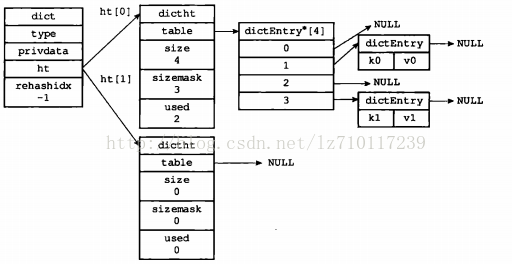
下图展示了普通状态下(没有进行rehash)的字典。
哈希算法
当要将一个新的键值对添加到字典里面时,程序需要先根据键值对的键计算出哈希值和索引值,然后再根据索引值,将包含新键值对的哈希表节点放到哈希表数组的指定索引上面。Redis计算哈希值和索引值的方法如下;
#使用字典设置的哈希函数,计算键key的哈希值
hash = dict->type->hashFunction(key)
#使用哈希表的sizemask属性和哈希值,计算出索引值
#使用情况不同,ht[x]可以是ht[0]或者ht[1]
index = hash& dict->ht[x].sizemask;
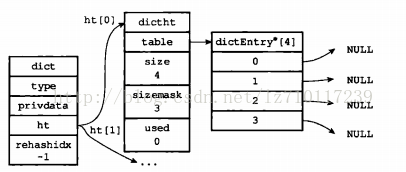
举个例子,对于图4-4所示的字典来说,如果我们要将一个键值对k0和v0添加到字典里面,那么程序会使用语句:
hash = dict->type->hashFunction(k0);
计算键K0的哈希值。
假设计算得出的哈希值为8,那么程序会继续使用语句:
index = hash&dict->ht[0].sizemask = 8&3 =0;
计算出键K0的索引值0,这表示包含键值对k0和v0的节点应该被放置到哈希表数组的索引0位置上,如下所示:
解决键冲突
当有两个或以上数量的键被分配到了哈希数组的同一个索引上面我们称这些键发生了冲突。
redis中用了dictEntry的next属性解决键冲突,如下所示:
rehash
随着操作的不断执行,哈希表保存的键值对会逐渐地增多或者减少,为了让哈希表的负载因子(load factor)维持在一个合理的范围内,当哈希表保存的键值对数量太多或者太少时,程序需要对哈希表的大小进行相应的扩展或者收缩。
扩展和收缩哈希表的工作可以通过执行rehash(重新散列)操作来完成,Redis对字典的哈希表执行rehash的步骤如下:
1)为字典的ht[1]哈希表分配空间,这个哈希表的空间大小取决于要执行的操作,以及ht[0]当前包含的键值对数量(也即是ht[0].used属性的值):
- 如果执行的是扩展操作,那么ht[1]的大小为第一个大于等于ht[0].的2倍
- 如果执行的是收缩操作,那么ht[1]的大小为第一个大于等于ht[0].used的2的n次幂。
2)将保存在ht[0]中的所有键值对rehash到ht[1]上面,rehash值的是重新计算键的哈希值和索引值,然后将键值对放置到ht[1]哈希表的指定位置上。
3)当ht[0]包含的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),释放ht[0],jiang ht【1】设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备。
举个例子,假设程序要多下表的ht[0]进行扩展操作,那么程序将执行以下步骤:
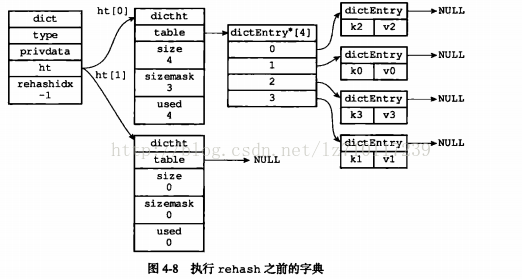
1)ht[0].used当前的值为4,负载因子为1,图4-9展示了ht[1]在分配空间之后,字典的样子。
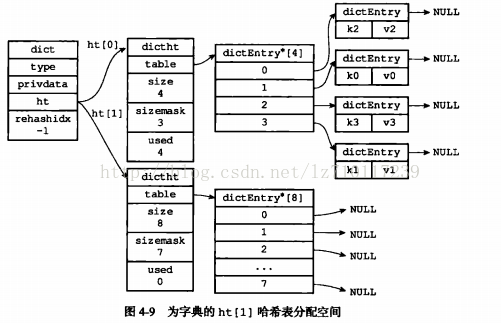
2)将ht[0]包含的两个键值对都rehash到ht[1],如图4-10所示。
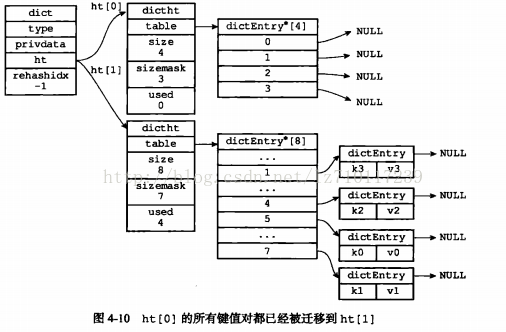
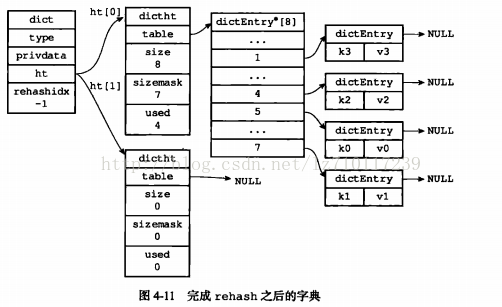
3)释放ht[0],并将ht[1]设置为ht[0],然后为ht[1]分配一个空白哈希表,如图4-1·1所示。至此,哈希表的扩展操作执行完毕,程序成功即将哈希表的大小从原来的4改成了现在的8.
二 , 代码实现
字典的Rehash操作
本来是想在最后介绍rehash的,结果发现在字典的基本操作中处处涉及到rehash,所以想想还是将rehash挪到前面好了
Redis会在两种情况对字典进行rehash操作
字典中哈希节点数量过多,导致在同一个下标下查找某个键的时间边长,需要扩大字典容量
字典中哈希节点数量过少,导致很多位置处于空缺,占用大量空缺内存,需要缩小字典容量
哈希表的扩充
当为键计算哈希值时,会判断是否需要对字典进行扩充,判断函数是_dictExpandIfNeeded,判断的依据是
字典中哈希节点个数大于哈希表大小
哈希节点个数 / 哈希表大小 > 负载因子
函数定义如下
//dict.c
/* 判断是否需要对字典执行扩充操作,如果需要,扩充 */
static int _dictExpandIfNeeded(dict *d)
{
/* 如果此时正在进行rehash操作,则不进行扩充 */
if (dictIsRehashing(d)) return DICT_OK;
/* 如果哈希表容量为0,代表此时是初始化,创建默认大小的哈希表 */
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* 负载因子,如果字典中的节点数量 / 字典大小 > 负载因子,就需要对字典进行扩充 */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}rehash的意思是进行重新映射,此时就需要使用ht[1],即第二个哈希表(字典中包含两个哈希表,第二个用于rehash操作,上面提到过)
rehash的方法是先确定扩充或缩小的哈希表大小,然后为ht[1]申请内存空间,最后将rehashidx设置成0,标志着开始执行rehash操作
这些操作在dictExpand函数中执行
//dict.c
/* 扩充字典的哈希表,扩充的主要目的是用于rehash */
int dictExpand(dict *d, unsigned long size)
{
/* 新的哈希表 */
dictht n; /* the new hash table */
/* _dictNextPower函数返回第一个大于size的2的幂次方,Redis保证哈希表的大小永远是2的幂次方 */
unsigned long realsize = _dictNextPower(size);
/* rehash的过程中不能进行扩充操作 */
/* 扩充后的大小小于原有哈希节点时报错,说明size太小 */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* 大小没有改变,返回 */
if (realsize == d->ht[0].size) return DICT_ERR;
/* 设置新的哈希表属性,分配空间 */
n.size = realsize;
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* 如果以前的哈希表为空,那么就直接使用新哈希表即可,不需要进行数据移动 */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* 令第二个哈希表使用新的哈希表 */
d->ht[1] = n;
/* rehashidx设置为0,标志开始rehash操作 */
d->rehashidx = 0;
return DICT_OK;
}
这个函数并没有直接调用rehash函数,而是仅仅将rehashidx赋值为0,标志着当前处于rehash状态。每当对数据库进行增删改查时,都会先判断当前是否处于rehash状态,如果是,那么就执行一次rehash,这样的好处是将rehash带来的时间空间消耗分摊给了每一个对数据库的操作。而如果采用直接将全部的数据rehash到ht[1],那么当数据量很大时,rehash执行时间会很长,服务器很可能被阻塞。
需要注意的是为ht[1]申请的新大小而不是ht[0],这是Redis进行rehash的策略,即将ht[0]中的每个键值对重新计算其哈希值,然后添加到ht[1]中,当ht[0]中所有数据都已经添加到ht[1]时,将ht[1]作为ht[0]使用
Rehash操作
什么时候进行rehash操作呢,当对数据库进行增删改查时,会首先判断当前是否处在rehash状态
/* 判断是否正在进行rehash操作(rehashidx != -1) */
/* 如果正在进行rehash,那么每次对数据库的增删改查都会进行一遍rehash操作
* 这样可以将rehash的执行时间分摊到每一个对数据库的操作上 */
if (dictIsRehashing(d)) _dictRehashStep(d);
dictIsRehashing是个宏定义,仅仅是判断rehashidx是否为-1,这就是上面为什么将rehashidx设置为0就代表开启rehash操作
//dict.h
#define dictIsRehashing(d) ((d)->rehashidx != -1)
当Redis发现此时正处于rehash操作时,会执行rehash函数。不过Redis不是一次将ht[0]中所有的数据全部移动到ht[1],而是仅仅移动一小部分。Redis采用N步渐进式执行rehash操作,即每次移动ht[0]N个下标的数据到ht[1]中
rehash函数由dictRehash完成,这个函数虽然长了点,但是还是蛮好理解的
其中需要注意的是rehashidx记录着当前rehash的进度,即从哈希表ht[0]的rehashidx位置开始移动数据到ht[1]中(每次移动完成后都会更改rehashidx)
rehash的步骤是先获取ht[0]中rehashidx位置的哈希节点链表,将这个链表中所有哈希节点代表的键值对重新计算哈希值,添加到ht[1]中,然后从ht[0]中删除
每步移动一个下标下的整个链表,总共执行n步
如果已经将ht[0]的所有数据移动到ht[1]中,就释放ht[0],将ht[1]作为ht[0],然后重置ht[1],将rehashidx设置为-1标志不再执行rehash操作
//dict.c
/*
* 将第一个哈希表的键值对重新求哈希值后添加到第二个哈希表
*/
int dictRehash(dict *d, int n) {
int empty_visits = n*10; /* Max number of empty buckets to visit. */
/* 没有进行rehash操作,返回 */
if (!dictIsRehashing(d)) return 0;
/* n步渐进式的rehash操作,每次移动rehashidx索引下的键值到新表 */
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long)d->rehashidx);
/* 找到下一个存在哈希节点的索引 */
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
/* 如果遇到一定数量的空位置,就返回 */
if (--empty_visits == 0) return 1;
}
/* 获取这个索引下的哈希节点链表头 */
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while(de) {
unsigned int h;
/* 保存相同索引下的下一个哈希节点 */
nextde = de->next;
/* Get the index in the new hash table */
/* dictHashKey调用hasFunction,计算哈希值,与掩码与运算计算下标值 */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
/* h是rehash后的索引,将当前哈希节点保存在第二个哈希表的对应索引上 */
de->next = d->ht[1].table[h];
/* 记录对应索引的哈希节点表头 */
d->ht[1].table[h] = de;
/* 第一个哈希表的节点数减一 */
d->ht[0].used--;
/* 第二个哈希表的节点数加一 */
d->ht[1].used++;
/* 对下一个哈希节点进行处理 */
de = nextde;
}
/* 将当前索引下的所有哈希节点从第一个哈希表中删掉 */
d->ht[0].table[d->rehashidx] = NULL;
/* 处理下一个索引 */
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
/* 如果第一个哈希表已经全部转移到第二个上,就说明rehash操作完成,将第二个作为第一个 */
if (d->ht[0].used == 0) {
/* 释放第一个哈希表 */
zfree(d->ht[0].table);
/* 第二个哈希表作为第一个哈希表 */
d->ht[0] = d->ht[1];
/* 重置第二个哈希表,以用于下次rehash */
_dictReset(&d->ht[1]);
/* rehashidx设置为-1,表示没有在进行rehash操作 */
d->rehashidx = -1;
/* 返回0表示rehash完成 */
return 0;
}
/* More to rehash... */
/* 返回1表示rehash没有完成,还需要继续 */
return 1;
}每次对数据库进行增删改查时,如果当前处于rehash状态,就执行一步rehash函数(n=1)
//dict.c
/* 执行一步rehash */
static void _dictRehashStep(dict *d) {
/* 执行一次rehash */
if (d->iterators == 0) dictRehash(d,1);
}
另外,当处于rehash状态时,数据库的操作会有些不同
对数据库的添加操作会添加到ht[1]中而不再添加到ht[0],因为ht[0]中的键值对迟早要添加到ht[1]中,还不如直接添加到ht[1]中。这样带来的另一个好处是ht[0]的数量不会增加,可以保证rehash早晚可以完成
对数据库的查找操作会从ht[0]和ht[1]两个哈希表中查找,因为ht[0]中的键值对已经有一部分放到ht[1]中了
此外,Redis还提供了另一种rehash策略,即每次rehash一定时间,也比较好理解
//dict.c
/* 执行ms毫秒的rehash操作 */
int dictRehashMilliseconds(dict *d, int ms) {
/* 保存开始时的时间 */
long long start = timeInMilliseconds();
int rehashes = 0;
/* 每次rehash执行100步 */
while(dictRehash(d,100)) {
rehashes += 100;
/* 判断时间是否到达 */
if (timeInMilliseconds()-start > ms) break;
}
/* 返回rehash了多少步 */
return rehashes;
}字典的基本操作
字典的操作比较多,以增删改查为例
添加键值对
添加键值对操作是由dictAdd函数完成的,当在终端输入各种SET命令添加键值对时,最终也会调用这个函数
函数会先创建一个只有键没有值的哈希节点,然后为哈希节点设置值
/* 向字典中添加键值对 */
int dictAdd(dict *d, void *key, void *val)
{
/* 创建一个只有键没有值的哈希节点 */
dictEntry *entry = dictAddRaw(d,key);
if (!entry) return DICT_ERR;
/* 将值添加到创建的哈希节点中 */
dictSetVal(d, entry, val);
return DICT_OK;
}创建只有键没有值的操作由dictAddRaw函数完成,函数首先判断是否处于rehash状态,如果是,那么会执行一步rehash。同时如果处于rehash状态,那么会将键值对添加到ht[1]中而不是ht[0]
//dict.c
/* 向字典中添加一个只有key的键值对,如果正在进行rehash操作,则需要先执行rehash再添加 */
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
/* 判断是否正在进行rehash操作(rehashidx != -1) */
/* 如果正在进行rehash,那么每次对数据库的增删改查都会进行一遍rehash操作
* 这样可以将rehash的执行时间分摊到每一个对数据库的操作上 */
if (dictIsRehashing(d)) _dictRehashStep(d);
/* 计算键key在哈希表中的索引,如果哈希表中已存在相同的key,则返回 */
if ((index = _dictKeyIndex(d, key)) == -1)
return NULL;
/* 如果正在执行rehash,那么直接添加到第二个哈希表中 */
/* 因为rehash操作是将第一个哈希表重新映射到第二个哈希表中
* 那么就没必要再往第一个哈希表中添加,可以直接添加到第二个哈希表中
* 这样做的目的是保证在rehash的过程中第一个哈希表的节点数量是一直减少的 */
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0];
/* 申请节点 */
entry = zmalloc(sizeof(*entry));
/* 将为key创建的哈希节点添加到哈希表的相应索引下 */
entry->next = ht->table[index];
ht->table[index] = entry;
/* 节点数加一 */
ht->used++;
/* 设置节点的键为key */
dictSetKey(d, entry, key);
return entry;
}
删除键值对
删除键值对主要由dictGenericDelete函数完成,函数首先会判断是否处于rehash状态,如果是则执行一步rehash。然后在ht[0]和ht[1]中查找匹配的键值对,执行删除操作
//dict.c
/* 从字典中删除键key对应的键值对,nofree代表是否释放键值对的内存空间 */
static int dictGenericDelete(dict *d, const void *key, int nofree)
{
unsigned int h, idx;
dictEntry *he, *prevHe;
int table;
/* 字典为空,没有数据,直接返回 */
if (d->ht[0].size == 0) return DICT_ERR; /* d->ht[0].table is NULL */
/* 如果正处于rehash状态,那么执行一步rehash */
if (dictIsRehashing(d)) _dictRehashStep(d);
/* 计算键key的哈希值 */
h = dictHashKey(d, key);
/* 在ht[0]和ht[1]中寻找 */
for (table = 0; table <= 1; table++) {
/* 计算键key的索引下标(与掩码sizemask与运算) */
idx = h & d->ht[table].sizemask;
he = d->ht[table].table[idx];
prevHe = NULL;
while(he) {
/* 依次比较索引下标下的哈希节点,找到键相同的那个哈希节点 */
if (key==he->key || dictCompareKeys(d, key, he->key)) {
/* Unlink the element from the list */
/* 将哈希节点移除 */
if (prevHe)
prevHe->next = he->next;
else
d->ht[table].table[idx] = he->next;
/* 如果需要释放内存,则将键值对的内存空间释放 */
if (!nofree) {
dictFreeKey(d, he);
dictFreeVal(d, he);
}
/* 释放哈希节点的内存 */
zfree(he);
/* 节点个数减一 */
d->ht[table].used--;
return DICT_OK;
}
prevHe = he;
he = he->next;
}
/* 如果没有进行rehash,那么ht[1]中没有数据,不需要在ht[1]中寻找 */
if (!dictIsRehashing(d)) break;
}
return DICT_ERR; /* not found */
}
修改键值对
修改键值对由dictReplace函数完成,如果键不存在,则执行常规的添加操作,如果存在,则修改值。实际调用的还是添加操作,因为添加操作当键存在是会返回错误
//dict.c
/* 如果添加时对应的key已经存在,就替换 */
int dictReplace(dict *d, void *key, void *val)
{
dictEntry *entry, auxentry;
if (dictAdd(d, key, val) == DICT_OK)
return 1;
/* 到达这里表示键key在哈希表中已存在,从哈希表中找到该节点 */
entry = dictFind(d, key);
/* 保存以前的哈希节点,实际上是为了保存哈希节点值,因为需要释放值的内存 */
auxentry = *entry;
/* 将键key对应的节点值设置为val */
dictSetVal(d, entry, val);
/* 释放旧的哈希节点值 */
dictFreeVal(d, &auxentry);
return 0;
}
查找键值对
查找键值对由dictFind函数完成,首先根据键计算哈希值和下标,然后在对应位置查找是否有匹配的键,如果有则将哈希节点返回
//dict.c
/* 查找键为key的哈希节点 */
dictEntry *dictFind(dict *d, const void *key)
{
dictEntry *he;
unsigned int h, idx, table;
/* 字典为空 */
if (d->ht[0].used + d->ht[1].used == 0) return NULL; /* dict is empty */
/* 如果处于rehash状态,执行一步rehash */
if (dictIsRehashing(d)) _dictRehashStep(d);
/* 计算哈希值 */
h = dictHashKey(d, key);
/* 在ht[0]和ht[1]中搜索 */
for (table = 0; table <= 1; table++) {
/* 计算下标 */
idx = h & d->ht[table].sizemask;
/* 获得下标处的哈希节点链表头 */
he = d->ht[table].table[idx];
while(he) {
/* 寻找键与key相同的哈希节点 */
if (key==he->key || dictCompareKeys(d, key, he->key))
return he;
he = he->next;
}
/* 如果没有进行rehash,则没有必要在ht[1]中查找 */
if (!dictIsRehashing(d)) return NULL;
}
return NULL;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号