
多个SHOULD的倒排表合并
BooleanScorer中的一些变量跟方法
static final int SHIFT = 11;
static final int SIZE = 1 << SHIFT;
static final int SET_SIZE = 1 << (SHIFT - 6);
static class Bucket {
// 谋篇文档的分数
double score;
// 某篇文档包含查询关键字的个数(去重)
int freq;
}
// 初始化一个SIZE大小的数组, 数组下标是文档号。
final Bucket[] buckets = new Bucket[SIZE];
// 每一个数组元素的二进制值的每一个bit位用来描述文档号是否出现(后面会解释这句话)
final long[] matching = new long[SET_SIZE];每一个term匹配到的每一个文档号都会作为参数传入到下面的collect(int doc)方法中,用来统计文档号出现的次数
public void collect(int doc) throws IOException {
//doc为文档号, MASK的值为2047,作为理解倒排表合并的原理,我们不用考虑文档号大于2047的情况
final int i = doc & MASK;
// 每32篇文档都会记录在matching[idx]数组的同一个元素中
// 比如说 0~31的文档号就被记录在 matching[0]这个数组元素中(看不懂?没关系,往下看就知道了)
final int idx = i >>> 6;
// 用来去重的存储文档号, 二进制表示的数值中,每个为1的bit位的所属第几位就是文档号的值
// 比如 00...01001(32位二进制), 说明存储了 文档号 0跟3
// matching在后面遍历中使用,因为我们还要判断每一篇文档出现的次数是否满足minSHouldMatch
// 那么通过这个matching值就可以从buckets[]数组中以O(1)的复杂度找到每一篇文档出现的次数
matching[idx] |= 1L << i;
// 引用bucket对象,buckets[]数组下标是文档号
// bucket中的freq统计某个文档号出现的次数
final Bucket bucket = buckets[i];
bucket.freq++;
// 这里可以看出,打分是一个累加的过程
bucket.score += scorer.score();
}在上面的collect(int doc)方法调用结束后,每篇文档的包含查询关键字的个数(去重)都已经计算完毕,接着只需要一一取出跟minShouldMatch的值进行比较,大于minShouldMatch的文档号即是满足要求长度文档。 前面说道,Bucket[]数组的下标是文档号,那么我们通过matching[idx],就能以O(1)的时间复杂度知道Bucket[]数组中哪些下标是有值的。
private void scoreMatches(LeafCollector collector, int base) throws IOException {
// 取出前面计算出的数组
long matching[] = this.matching;
for (int idx = 0; idx < matching.length; idx++) {
// 取出其中一个matching[]数组的值
long bits = matching[idx];
// 反序列化的过程,得到所有的文档号
while (bits != 0L) {
int ntz = Long.numberOfTrailingZeros(bits);
int doc = idx << 6 | ntz;
// 每得到一个文档号就调用下面的方法去跟minShouldMatch比较
scoreDocument(collector, base, doc);
bits ^= 1L << ntz;
}
}
}
private void scoreDocument(LeafCollector collector, int base, int i) throws IOException {
final FakeScorer fakeScorer = this.fakeScorer;
final Bucket bucket = buckets[i];
// if语句为true:文档号出现的次数满足minShouldMatch
if (bucket.freq >= minShouldMatch) {
... ...
// 根据之前得到的windowBase值,恢复文档号真正的值
final int doc = base | i;
... ...
// 满足minShouldMatch的文档号传给Collector,完成结果的收集
collector.collect(doc);
}
bucket.freq = 0;
bucket.score = 0;
}例子
文档0:a
文档1:b
文档2:c
文档3:a c e
文档4:h
文档5:c e
文档6:c a
文档7:f
文档8:b c d e c e
文档9:a c e a b c查询关键字如下
BooleanQuery.Builder query = new BooleanQuery.Builder();
query.add(new TermQuery(new Term("content", "a")), BooleanClause.Occur.SHOULD);
query.add(new TermQuery(new Term("content", "b")), BooleanClause.Occur.SHOULD);
query.add(new TermQuery(new Term("content", "c")), BooleanClause.Occur.SHOULD);
query.add(new TermQuery(new Term("content", "e")), BooleanClause.Occur.SHOULD);
query.setMinimumNumberShouldMatch(2);处理包含关键字“a”的文档
将包含“a”的文档号记录到bucket[]数组中(图中书写错误。。。谅解~应该是的bucket[])
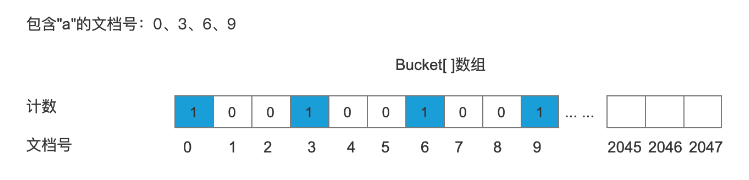
处理包含关键字“b”的文档
将包含“b”的文档号记录到Bucket[]数组中

处理包含关键字“c”的文档
将包含“c”的文档号记录到Bucket[]数组中
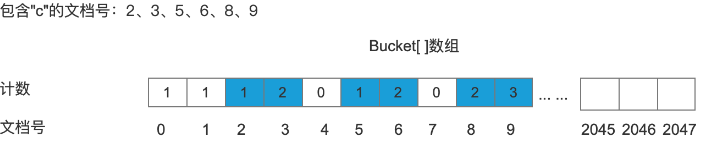
处理包含关键字“e”的文档
将包含“e”的文档号记录到Bucket[]数组中
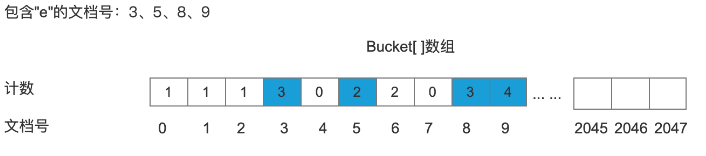
统计文档号
接着我们根据matching[]数组中的元素以 0(1) 的时间复杂度找到Bucket[]中所有的文档号,如果不通过matching[],那么我们必须对Bucket[]的每一个元素遍历查找
在当前的例子中,我们只要用到matching[]的第一个元素,第一个元素的值是879(为什么只要用到第一个元素跟第一个元素的是怎么得来的,在BooleanScorer类中我加了详细的注释,这里省略)

根据二进制中bit位的值为1,这个bit位的位置来记录包含查询关键字的文档号,包含查询关键字的文档号只有0,1,2,3,5,6,8,9一共8篇文档,接着根据这些文档号,把他们作为bucket[]数组的下标,去找到每一个数组元素中的值,如果元素的值大于等于minShouldMatch,对应的文档就是我们最终的结果,我们的例子中
query.setMinimumNumberShouldMatch(2);所以根据最终的bucket[]
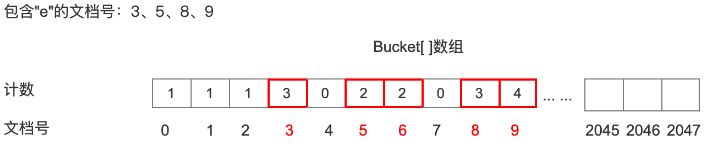
只有文档号3,文档号5,文档6,文档8,文档9对应元素值大于minShouldMatch,满足查询要求

