
为什么Lucene检索可以比mysql快
Mysql只有term dictionary这一层,是以b-tree排序的方式存储在磁盘上的。检索一个term需要若干次的random access的磁盘操作。而Lucene在term dictionary的基础上添加了term index来加速检索,term index以树的形式缓存在内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘的random access次数。
额外值得一提的两点是:term index在内存中是以FST(finite state transducers)的形式保存的,其特点是非常节省内存。Term dictionary在磁盘上是以分block的方式保存的,一个block内部利用公共前缀压缩,比如都是Ab开头的单词就可以把Ab省去。这样term dictionary可以比b-tree更节约磁盘空间。
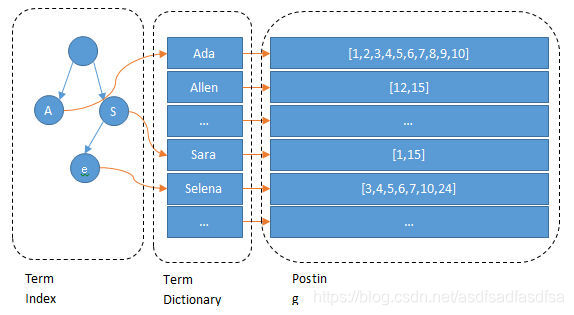
对于联合查询: 所以给定查询过滤条件 age=18 的过程就是先从term index找到18在term dictionary的大概位置,然后再从term dictionary里精确地找到18这个term,然后得到一个posting list或者一个指向posting list位置的指针。然后再查询 gender=女 的过程也是类似的。最后得出 age=18 AND gender=女 就是把两个 posting list 做一个“与”的合并。
这个理论上的“与”合并的操作可不容易。对于mysql来说,如果你给age和gender两个字段都建立了索引,查询的时候只会选择其中最selective的来用,然后另外一个条件是在遍历行的过程中在内存中计算之后过滤掉。那么要如何才能联合使用两个索引呢?有两种办法:
- 使用skip list数据结构。同时遍历gender和age的posting list,互相skip;
- 使用bitset数据结构,对gender和age两个filter分别求出bitset,对两个bitset做AN操作
利用 Skip List 合并
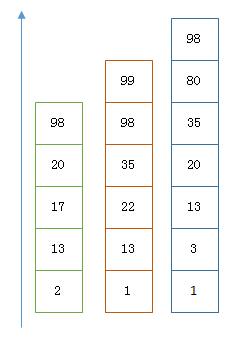
以上是三个posting list。我们现在需要把它们用AND的关系合并,得出posting list的交集。首先选择最短的posting list,然后从小到大遍历。遍历的过程可以跳过一些元素,比如我们遍历到绿色的13的时候,就可以跳过蓝色的3了,因为3比13要小。
整个过程如下
Next -> 2
Advance(2) -> 13
Advance(13) -> 13
Already on 13
Advance(13) -> 13 MATCH!!!
Next -> 17
Advance(17) -> 22
Advance(22) -> 98
Advance(98) -> 98
Advance(98) -> 98 MATCH!!!
最后得出的交集是[13,98],所需的时间比完整遍历三个posting list要快得多。但是前提是每个list需要指出Advance这个操作,快速移动指向的位置。什么样的list可以这样Advance往前做蛙跳?skip list:
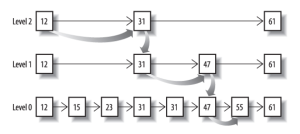
从概念上来说,对于一个很长的posting list,比如:
[1,3,13,101,105,108,255,256,257]
我们可以把这个list分成三个block:
[1,3,13] [101,105,108] [255,256,257]
然后可以构建出skip list的第二层:
[1,101,255]
1,101,255分别指向自己对应的block。这样就可以很快地跨block的移动指向位置了。
Lucene自然会对这个block再次进行压缩。其压缩方式叫做Frame Of Reference编码。示例如下:
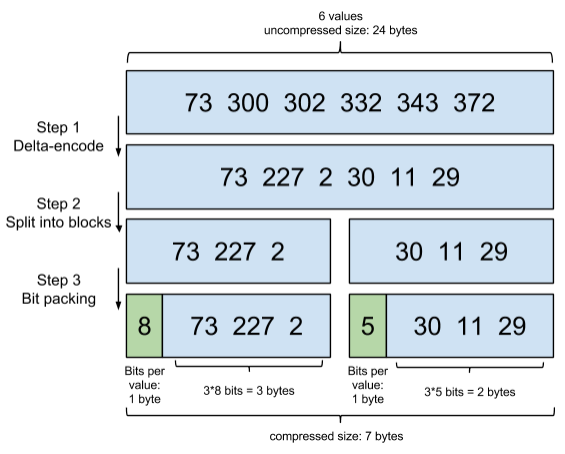
考虑到频繁出现的term(所谓low cardinality的值),比如gender里的男或者女。如果有1百万个文档,那么性别为男的posting list里就会有50万个int值。用Frame of Reference编码进行压缩可以极大减少磁盘占用。这个优化对于减少索引尺寸有非常重要的意义。当然mysql b-tree里也有一个类似的posting list的东西,是未经过这样压缩的。
因为这个Frame of Reference的编码是有解压缩成本的。利用skip list,除了跳过了遍历的成本,也跳过了解压缩这些压缩过的block的过程,从而节省了cpu。

