
Word2Vec原理
原始模型:
原始模型: 就是根据输入(x,y),根据词x和词y共现的最大概率迭代模型
参考:https://www.cnblogs.com/Micang/p/10235783.html
word2vec的详细实现,简而言之,就是一个三层的神经网络。要理解word2vec的实现,需要的预备知识是神经网络和Logistic Regression。
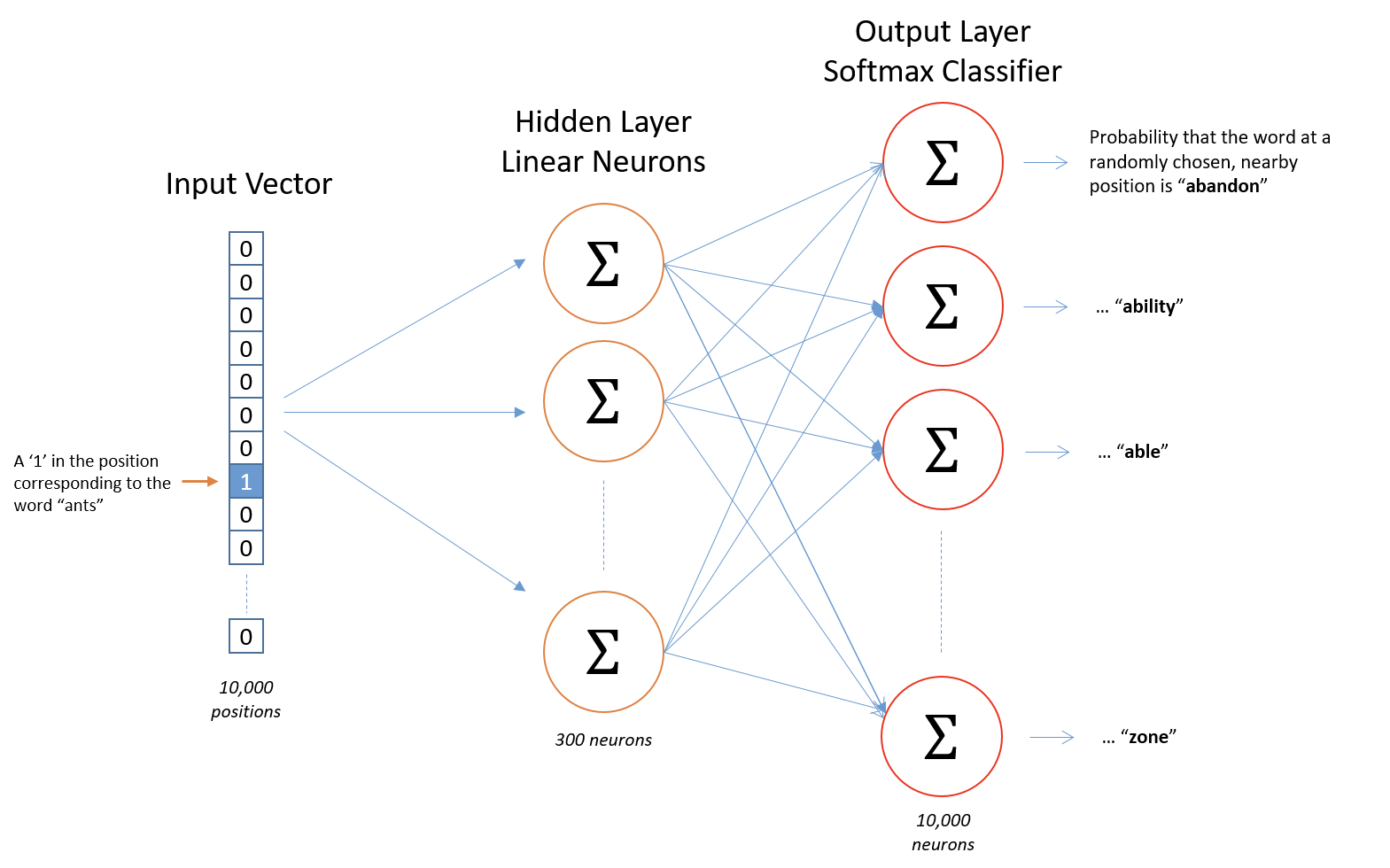
上图是Word2vec的简要流程图。首先假设,词库里的词数为10000; 词向量的长度为300(根据斯坦福CS224d的讲解,词向量一般为25-1000维,300维是一个好的选择)。下面以单个训练样本为例,依次介绍每个部分的含义。
1. 输入层:输入为一个词的one-hot向量表示。这个向量长度为10000。假设这个词为ants,ants在词库中的ID为i,则输入向量的第i个分量为1,其余为0。[0, 0, ..., 0, 0, 1, 0, 0, ..., 0, 0]
2. 隐藏层:隐藏层的神经元个数就是词向量的长度。隐藏层的参数是一个[10000 ,300]的矩阵。 实际上,这个参数矩阵就是词向量。回忆一下矩阵相乘,一个one-hot行向量和矩阵相乘,结果就是矩阵的第i行。经过隐藏层,实际上就是把10000维的one-hot向量映射成了最终想要得到的300维的词向量。
3. 输出层: 输出层的神经元个数为总词数10000,参数矩阵尺寸为[300,10000]。词向量经过矩阵计算后再加上softmax归一化,重新变为10000维的向量,每一维对应词库中的一个词与输入的词(在这里是ants)共同出现在上下文中的概率。
上图中计算了car与ants共现的概率,car所对应的300维列向量就是输出层参数矩阵中的一列。输出层的参数矩阵是[300,10000],也就是计算了词库中所有词与ants共现的概率。输出层的参数矩阵在训练完毕后没有作用。
4. 训练:训练样本(x, y)有输入也有输出,我们知道哪个词实际上跟ants共现,因此y也是一个10000维的向量。损失函数跟Logistic Regression相似,是神经网络的最终输出向量和y的交叉熵(cross-entropy)。最后用随机梯度下降来求解。
我们会发现Word2Vec模型是一个超级大的神经网络
举个栗子,我们拥有10000个单词的词汇表,我们如果想嵌入300维的词向量,那么我们的输入-隐层权重矩阵和隐层-输出层的权重矩阵都会有 10000 x 300 = 300万个权重,在如此庞大的神经网络中进行梯度下降是相当慢的。更糟糕的是,你需要大量的训练数据来调整这些权重并且避免过拟合。百万数量级的权重矩阵和亿万数量级的训练样本意味着训练这个模型将会是个灾难
下面主要介绍两种方法优化训练过程。
1.负采样(negative sampling)
负采样(negative sampling)解决了这个问题,它是用来提高训练速度并且改善所得到词向量的质量的一种方法。不同于原本每个训练样本更新所有的权重,负采样每次让一个训练样本仅仅更新一小部分的权重,这样就会降低梯度下降过程中的计算量。至于具体的细节我在这里就不在介绍了
2.层序softmax也是解决这个问题的一种方法。这里也不做详细介绍
word2vec:由于训练词向量模型的目标不是为了得到一个多么精准的语言模型,而是为了获得它的副产物——词向量(与神经网络的不同之处)。所以要做到的不是在几万几十万个token中艰难计算softmax获得最优的那个词(就是预测的对于给定词的下一词),
而只需能做到在几个词中找到对的那个词就行,这几个词包括一个正例(即直接给定的下一词),和随机产生的噪声词(采样抽取的几个负例);
或者就是说训练一个sigmoid二分类器(利用哈夫曼树变成多个二分类)!!!!!!!,只要模型能够从中找出正确的词就认为完成任务。

上图所示,基于词频率的会以为网吧和网咖完全不一样,不同于词频,对于神经网络来说,''网吧''词向量约等于''网咖''词向量
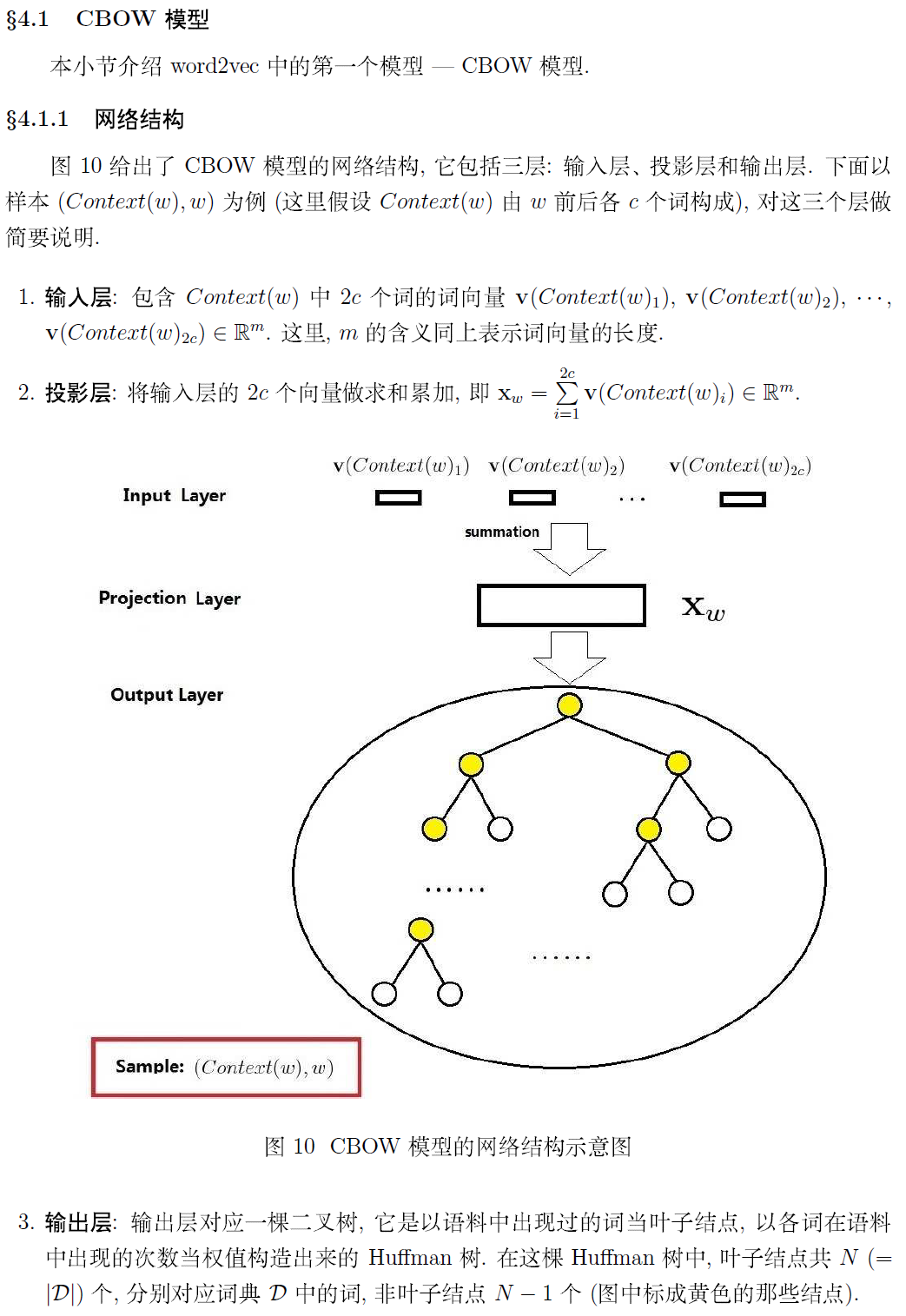
我们就需要训练神经网络语言模型,即CBOW和Skip-gram模型。这个模型的输出我们不关心,我们关心的是模型中第一个隐含层中的参数权重,这个参数矩阵就是我们需要的词向量。它的每一行就是词典中对应词的词向量,行数就是词典的大小
以下出自: https://me.csdn.net/peghoty





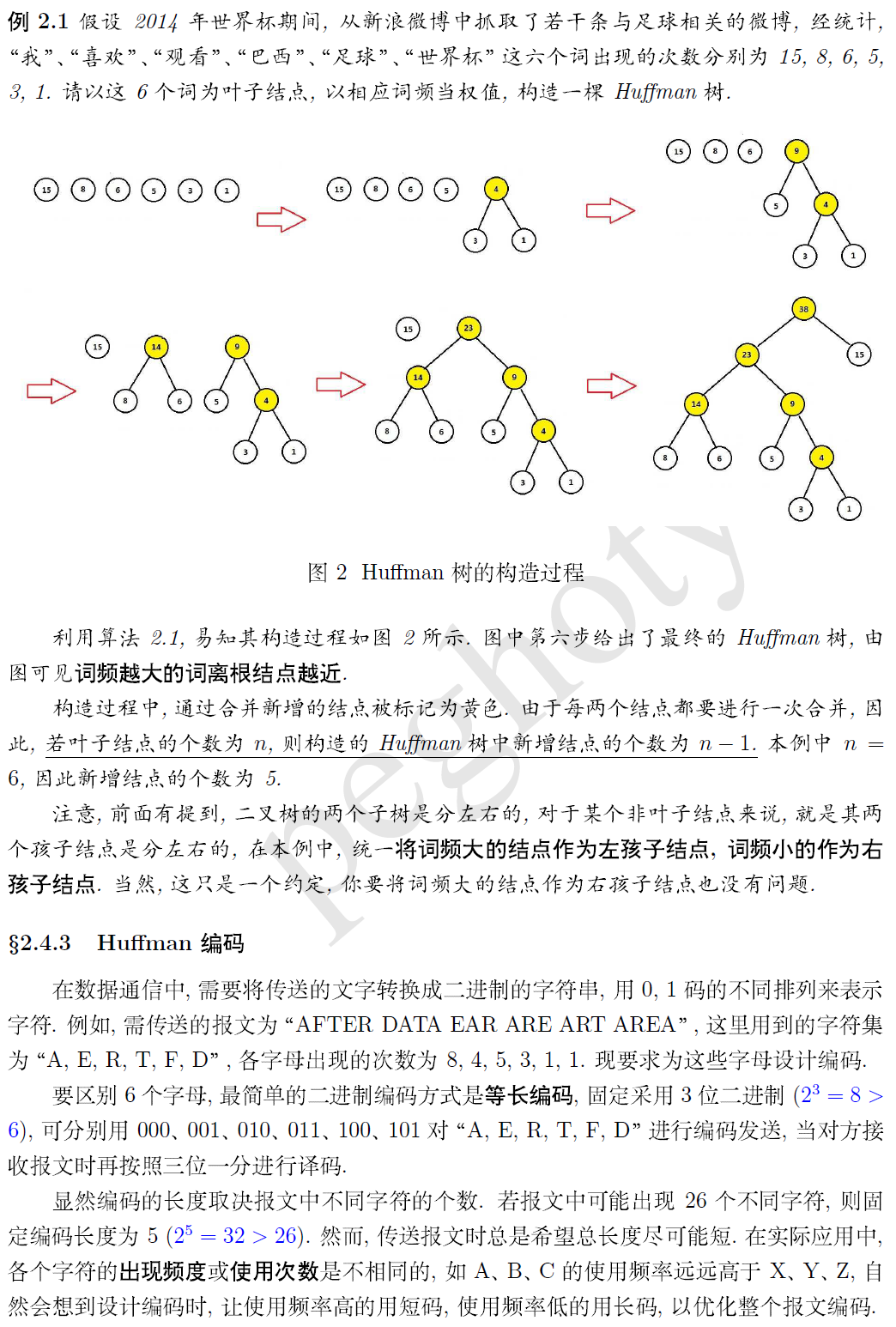
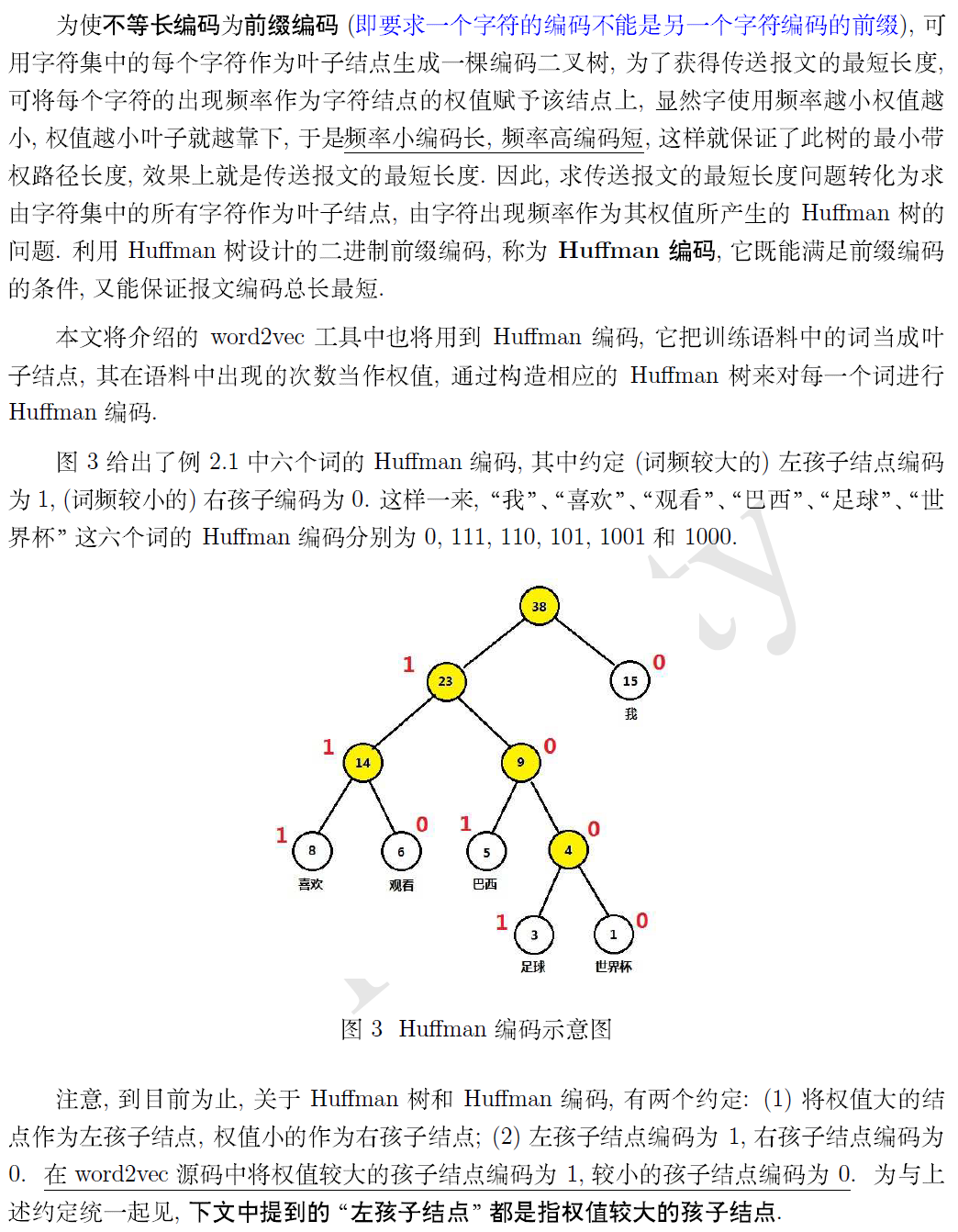












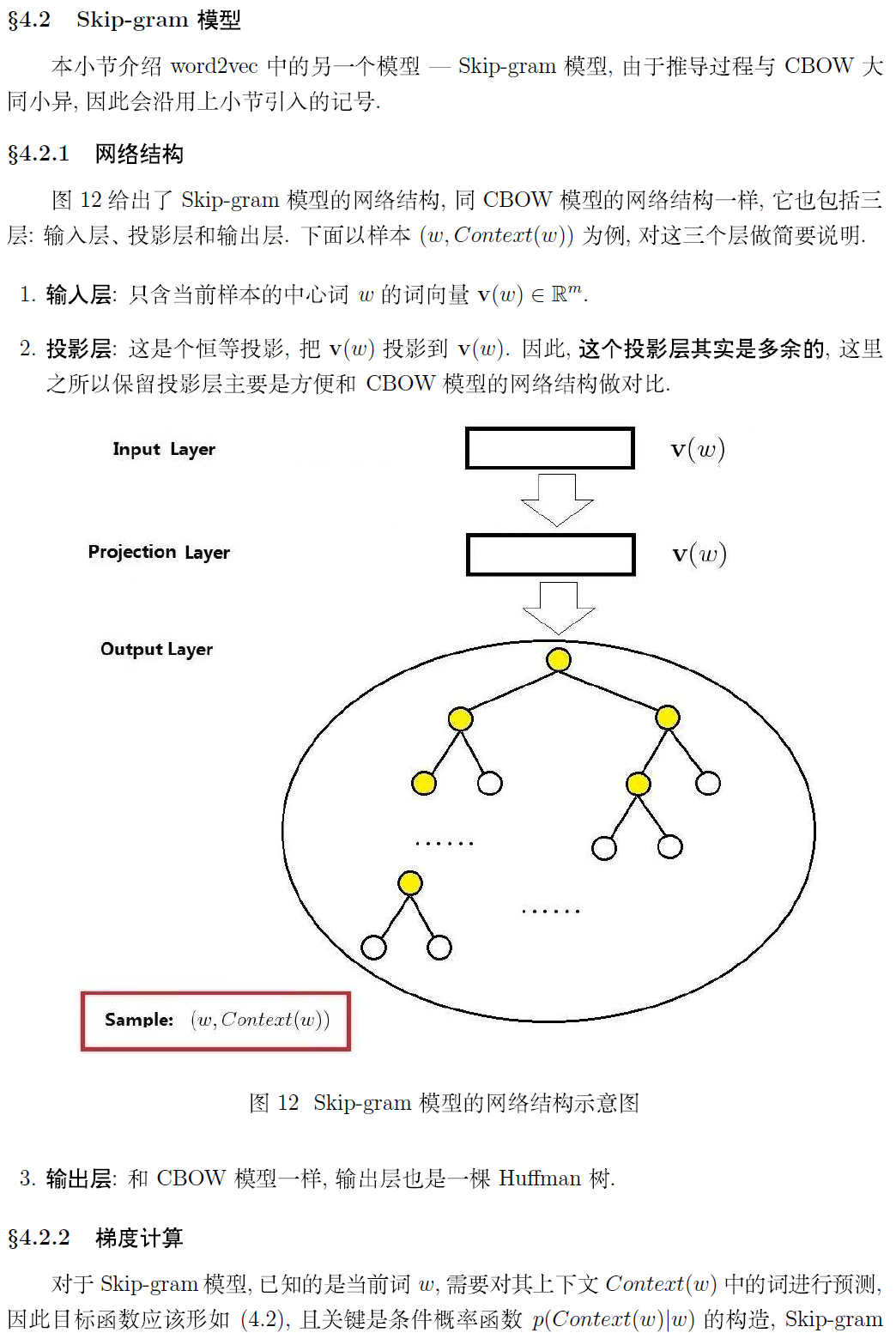

















层次化softmax的原理参见: https://blog.csdn.net/qq_39422642/article/details/78659872
负采样的损失函数见: https://blog.csdn.net/shinanhualiu/article/details/49891597
tensorflow的nec_loss的源码分析: https://blog.csdn.net/weixin_42001089/article/details/81224869
https://www.cnblogs.com/xiaojieshisilang/p/9284634.html
https://blog.csdn.net/qq_36092251/article/details/79684721
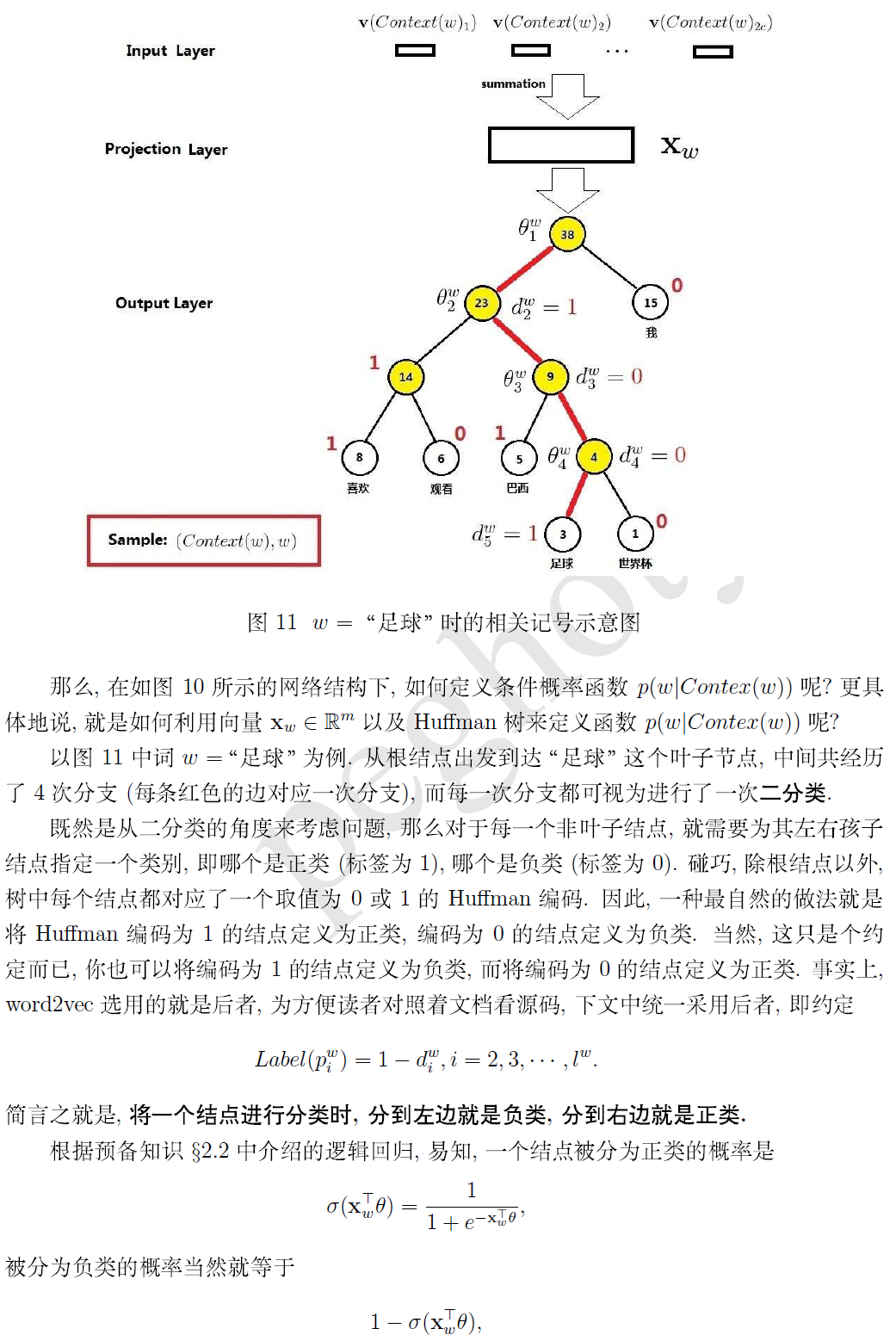
使用huffman树的原因:
1.实际上就是将神经网络转化为huffman树???
2.使N分类问题变成logN分类
3.词频低的遍历次数多(分类次数多),反之, 这样可以降低整个计算量
4. 每个词都有唯一编码
5.构建huffman树是所有语料中的所有词共同参与, 只构建一次, 在以后的每个语料训练中使用同一个huffman树

