kafka服务端--KafkaController(一)
一, 概述
控制器是Kafka的核心组件之一,它的主要作用是在 ZooKeeper 的帮助下协调和管理整个Kafka集群。Kafka 利用ZooKeeper 的领导者选举机制,每个Broker 都会参与竞选主控制器,但是最终只会有一个 Broker 可以成为主控制器。下面我们简单的看一下控制器主要的作用是什么。
1、主题管理:控制器会帮助我们完成Topic 的创建、删除以及增加分区。也就是当执行 kafka-topics.sh 脚本时,大部分的后台工作是由Kafka控制器完成的。
2、分区重分配:是指 kafka-reassign-partitions.sh 脚本对已有主题分区的细粒度的分配功能。
3、Preferred 领导者选举:主要是Kafka为了避免因部分 Broker 的负载过重,而提供的一种换 Leader 的方案。
4、集群成员管理:其中包括新增 Broker、Broker 主动或被动关闭。/brokers/ids/ 下面会存放 Broker 实例的id 临时节点,当我们看到 /brokers/ids 下面有几个节点,就表示有多少个存活的 Broker 实例。当Broker 宕机时,临时节点就会被删除,此时控制器对应的监听器就会感知到Broker 下线,进而完成对应的下线工作。
5、数据服务:控制器上面存放了最全的集群元数据信息,其他 Broker 会定期接收控制器发来的更新请求,从而定期的刷新其元数据缓存数据。
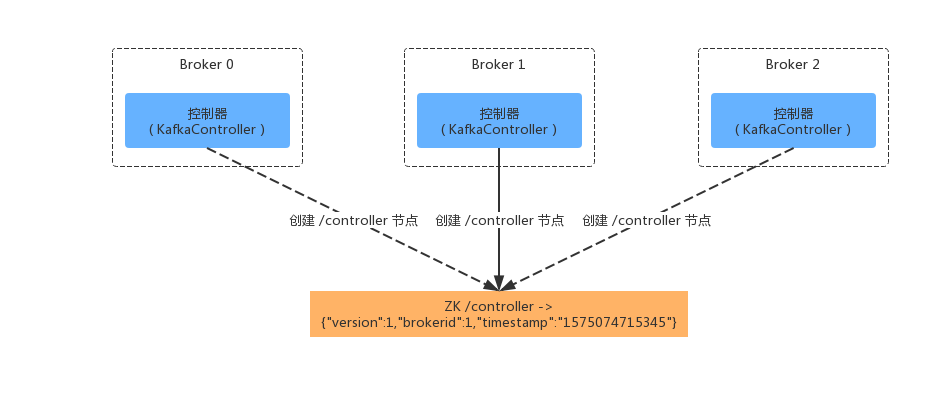
控制器选举
Kafka实现领导者选举的做法是:每个代理节点都会作为ZooKeeper的客户端,向ZooKeeper 服务端尝试创建 /controller 临时节点,但是最终只有 1 个Broker 可以成功创建临时节点。因为 /controller 节点是临时节点,当主控制器出现故障或者会话失效时,临时节点会被删除。此时所有的Broker 都会重新竞选 Leader,也就是尝试创建 /controller 临时节点,如下图所示:
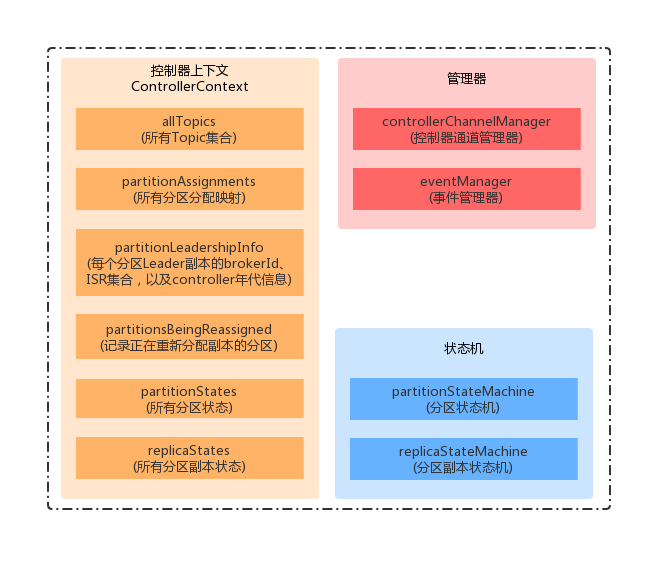
Kafka 控制器将Broker 节点信息存放在 ZooKeeper 的 /controller 节点上。除此之外,集群相关的元数据信息也会存储到 ZooKeeper 中,主控制器会读取 ZooKeeper 中的集群元数据信息,构造出控制器上下文(ControllerContext)。
控制器上下文(ControllerContext)
再讲控制器上下文之前,我们先看一下Kafka 在ZK中的存储结构。
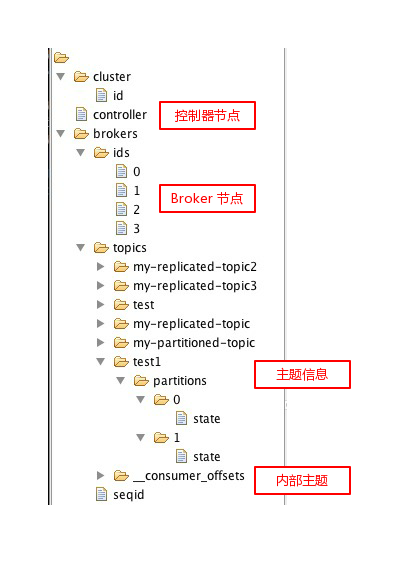
上面的ZK节点信息可以看出,Kafka的 Broker、主题、分区、控制器等相关信息都存储在其中。当控制器在初始化上下文时,就会读取ZK中的信息初始化ControllerContext 中的相关变量。下面我们看一下 ControllerContext 中的相关成员变量:
class ControllerContext(val zkUtils: ZkUtils) {
/** 管理 controller 与集群中其它 broker 之间的连接 */
var controllerChannelManager: ControllerChannelManager = _
/** 记录正在关闭的 brokerId 集合 */
var shuttingDownBrokerIds: mutable.Set[Int] = mutable.Set.empty
/** controller 的年代信息,初始为 0,每次重新选举之后值加 1 */
var epoch: Int = KafkaController.InitialControllerEpoch - 1
/** 年代信息对应的 ZK 版本,初始为 0 */
var epochZkVersion: Int = KafkaController.InitialControllerEpochZkVersion - 1
/** 集群中全部的 topic 集合 */
var allTopics: Set[String] = Set.empty
/** 记录每个分区对应的 AR 集合 */
var partitionReplicaAssignment: mutable.Map[TopicAndPartition, Seq[Int]] = mutable.Map.empty
/** 记录每个分区的 leader 副本所在的 brokerId、ISR 集合,以及 controller 年代信息 */
var partitionLeadershipInfo: mutable.Map[TopicAndPartition, LeaderIsrAndControllerEpoch] = mutable.Map.empty
/** 记录正在重新分配副本的分区 */
val partitionsBeingReassigned: mutable.Map[TopicAndPartition, ReassignedPartitionsContext] = new mutable.HashMap
/** 记录了正在进行优先副本选举的分区 */
val partitionsUndergoingPreferredReplicaElection: mutable.Set[TopicAndPartition] = new mutable.HashSet
/** 记录了当前可用的 broker 集合 */
private var liveBrokersUnderlying: Set[Broker] = Set.empty
/** 记录了当前可用的 brokerId 集合 */
private var liveBrokerIdsUnderlying: Set[Int] = Set.empty
}当集群信息变更时,最先感知到的是ZK节点信息,上下文保存了上一次的数据。当两者不一致时,ZK节点关联的监听器触发事件处理时,监听器要对比ZK和Context,找出新增和删除的数据。步骤如下:
(1)ZK节点数据 - ControllerContext 中的数据,表示要新增的数据;
(2)ControllerContext - ZK节点数据,表示要删除的数据;
(3)将 ControllerContext 中的数据,更新为ZK节点中的最新数据;
(4)让控制器分别处理需要新增和删除的节点对应的事件。
事件处理模型
前面我们知道 ControllerContext 上下文中的信息初始化依赖 ZK 中的信息,当ZK中的信息变更时,也要更新ControllerContext 上下文中的信息。比如为某个 Topic 增加了几个分区,此时控制器除了要负责创建分区,还需要更新 ControllerContext。除此之外,还需要将变更的信息同步到其他的 Broker 节点上。这些信息变更可能是监听器触发,也可能是定时任务触发,但最终都会转换为一个个事件,压入到事件队列中去,然后由事件处理线程 (ControllerEventThread)去处理,如下图所示:
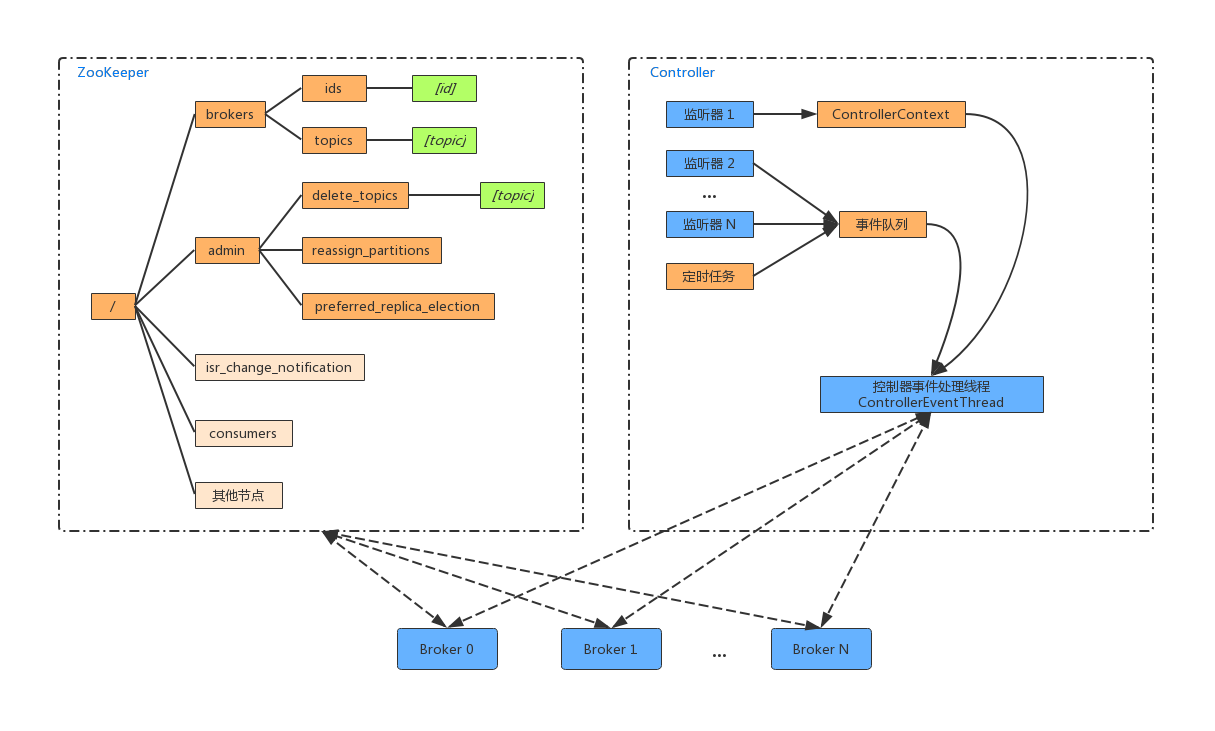
上面的事件模型是在Kafka 0.11.0 版本开始使用的,其大大的减少了控制器多线程的Bug。
采用单线程的时间处理模型将极大简化 Controller 的并发实现,只允许这个线程访问和修改 Controller 的本地状态信息,因此在 Controller 部分也就不需要到处加锁来保证线程安全了。Controller 使用了一个 ControllerEventThread 线程来处理所有的 event
ZK监听
Kafka控制器会在初始化上下文之前,向ZK节点注册一些监听器,并在初始化上下文后,执行监听器相关的时间处理。下面列举了常见的ZK节点监听:
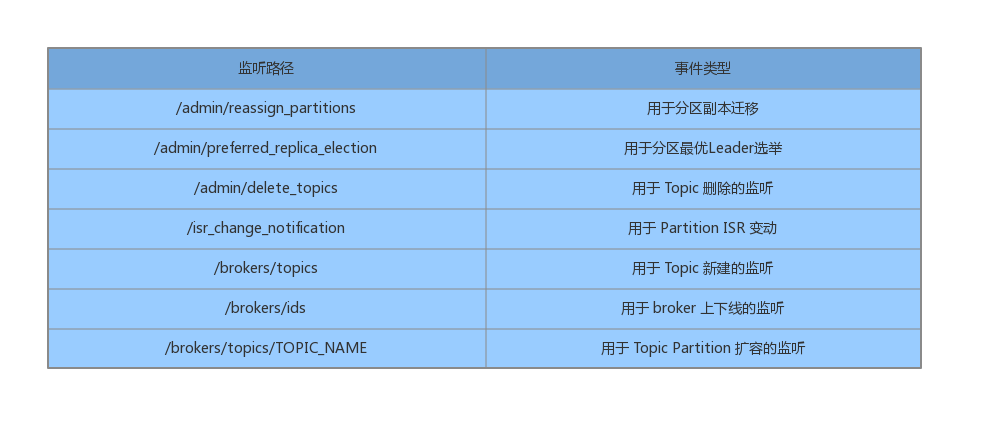
上面以/admin/开头的Node节点与管理操作有关,以/brokers/开头的与代理节点有关。控制初始化时会创建一个副本状态机(ReplicaStateMachine)和一个分区状态机(PartitionStateMachine)。状态机和控制器都是无状态的,它们都可以从共享存储(ZK)中恢复运行时需要的数据。状态机负责状态改变时的事件处理,当控制器发生故障转移时,除了重启控制器,也会重启状态机。故障转移时,不仅要保证集群的状态可以恢复,也要保证状态机可以正常运转。
二, 源码分析
代码版本: 2.0.0-SNAPSHOT
在深入到副本间的同步的内容前,先来看一下副本间同步的任务是如何从Kafka服务端启动后是如何开始的。KafkaServer启动时,主要调用KafkaServer.startup()方法进行初始化和启动,在startup()方法中初始化KafkaController并启动它。
KafkaController
Controller是Kafka的一个重要的组件,用于集群中的meta信息的管理。Controller的具体作用从KafkaController.onControllerFailover()方法中注册的监听事件可以看出来:
private def onControllerFailover() {
val childChangeHandlers = Seq(brokerChangeHandler, topicChangeHandler, topicDeletionHandler, logDirEventNotificationHandler,
isrChangeNotificationHandler)
val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)
}
KafkaController在集群的全局有且仅有一个是活动的,每个Broker都有可能成为Controller。具体的选举过程从KafkaServer的启动部分开始说起。过程如下如下:
//KafkaServer.scala
def startup() {
// ...
/* start kafka controller */
kafkaController = new KafkaController(config, zkClient, time, metrics, brokerInfo, tokenManager, threadNamePrefix)
kafkaController.startup()
// ...
}
在KafkaController.startup()方法中首先通过zk注册监听事件,监听StateChangeHandler,并将Startup放入ControllerEventManager的事件队列中,调用ControllerEventManager的startup()方法。ControllerEventManager为处理ControllerEvent的后台线程,用于在后台处理Startup,Reelect等事件。
//KafkaController.scala
def startup() = {
//registerStateChangeHandler用于session过期后触发重新选举
zkClient.registerStateChangeHandler(new StateChangeHandler {
override val name: String = StateChangeHandlers.ControllerHandler
override def afterInitializingSession(): Unit = {
eventManager.put(RegisterBrokerAndReelect)
}
override def beforeInitializingSession(): Unit = {
val expireEvent = new Expire
eventManager.clearAndPut(expireEvent)
// 阻塞等待时间被处理结束,session过期触发重新选举,必须等待选举这个时间完成Controller才能正常工作
expireEvent.waitUntilProcessingStarted()
}
})
// 放入Startup并启动eventManager后台线程开始选举
eventManager.put(Startup)
eventManager.start()
}
这里我们针对性地分析Startup这个事件的具体被执行的过程。在Startup的回调方法process()中,首先在zk中监听/controller路径。并且调用elect()进行选举过程。
// KafkaController.scala
case object Startup extends ControllerEvent {
def state = ControllerState.ControllerChange
override def process(): Unit = {
zkClient.registerZNodeChangeHandlerAndCheckExistence(controllerChangeHandler)
elect()
}
}
private def elect(): Unit = {
val timestamp = time.milliseconds
// 获得注册/controller成功的brokerId
activeControllerId = zkClient.getControllerId.getOrElse(-1)
// 开始创建临时节点前检查,如果/controller节点已经存在,说明已经有broker成为controller,
//因此本broker直接退出controller选举
if (activeControllerId != -1) {
return
}
try {
// 创建临时节点,声明本broker成为controller
zkClient.checkedEphemeralCreate(ControllerZNode.path, ControllerZNode.encode(config.brokerId, timestamp))
// 未抛异常说明写入创建成功,本broker荣升为controller
info(s"${config.brokerId} successfully elected as the controller")
activeControllerId = config.brokerId
onControllerFailover()
} catch {
// 如果其它broker已经创建了该节点,说明controller已经产生,则改写本地activeControllerId,做好自己的臣民本职工作
case _: NodeExistsException =>
activeControllerId = zkClient.getControllerId.getOrElse(-1)
// log
case e2: Throwable =>
error(s"Error while electing or becoming controller on broker ${config.brokerId}", e2)
// 遇到不可知错误,取消zk相关节点的监听注册,并调用删除/controller的zk的node
triggerControllerMove()
}
}
//
private def onControllerFailover() {
// 从zk读取epoch, epochZkVersion
readControllerEpochFromZooKeeper()
//更新zk总control节点,将epoch + 1
incrementControllerEpoch()
info("Registering handlers")
// before reading source of truth from zookeeper, register the listeners to get broker/topic callbacks
// 在读取zk之前注册brokerchange, topicchange, topicdeletion, logDirEventNoti,isrChange等事件,从这行及下面事件注册也看出control在集群中的作用
val childChangeHandlers = Seq(brokerChangeHandler, topicChangeHandler, topicDeletionHandler, logDirEventNotificationHandler,
isrChangeNotificationHandler)
childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler)
//同样地注册ReplicaElection,partitionReassignment事件
val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler)
nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence)
// 清理已存在的LogDirEventNotifications在zk上的记录
zkClient.deleteLogDirEventNotifications()
// 清理已存在的IsrChangeNotifications在zk上的记录
zkClient.deleteIsrChangeNotifications()
// 初始化controller context
// 在initializeControllerContext()中:
// 1. 注册监听所有topic的partitionModification事件
// 2. 从zk中获取所有topic的副本分配信息
// 3. 在zk中监听所有broker的更新情况
// 4. 从zk中读取topicPartition的leadership,更新本地缓存
// 5. 初始化ControllerChannelManager,为每个broker生成一个后台通信线程用于和broker通信,并启动后台线程
// 6. 从zk的/admin/reassign_partitions路径下读取partition的reassigned信息放入缓存用于后续处理
initializeControllerContext()
// 获取被删除的topics
val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress()
//初始化通过topicDeletionManager,如果isDeleteTopicEnabled则在zk中直接删除topicsToBeDeleted
topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)
// controller context 初始化结束之后发送请求更新metadata,这是因为需要在brokers能处理LeaderAndIsrRequests前获取哪些brokers是live的,
sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)
UpdateMetadataRequest
// 启动副本状态机,初始化zk中所有副本的状态
// 如果是online的副本则标记为OnlineReplica状态,否则标记为ReplicaDeletionIneligible
// 生成LeaderAndIsrRequest请求并发送到对应brokerId
replicaStateMachine.startup()
// 启动分区状态机,初始化分区状态至OnlinePartition,对于那些NewPartition,OfflinePartition状态的分区进行选举并在zk中更新updateLeaderAndIsr
partitionStateMachine.startup()
// 检查是否topic的partition的副本需要重新分配(reassign),如果partitionsBeingReassigned缓存中的分配信息和controllerContext缓存中不一致,则需要触发重新分配
maybeTriggerPartitionReassignment(controllerContext.partitionsBeingReassigned.keySet)
topicDeletionManager.tryTopicDeletion()
val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections()
onPreferredReplicaElection(pendingPreferredReplicaElections)
// 定时任务 other code ...
}
可以看到在Controller启动后,如果当选为Controller,则进行一些缓存的清理,并在zk上注册监听事件,监听那些Broker变化,Topic变化等事件,用于行使Controller的具体职责。并且通过发送UpdateMetadataRequest,用于各个Broker更新metadata。在启动过程中,Controller还会启动副本状态机和分区状态机。这两个状态机用于记录副本和分区的状态,并且预设了状态转换的处理方法。在Controller启动时会分别调用两个状态机的startup()方法,在该方法中初始化副本和分区的状态,并且主要地触发LeaderAndIsrRequest请求到Broker。
KafkaApis
下面来看Broker接收到LeaderAndIsrRequest请求的处理过程。
//KafkaApis.scala
def handle(request: RequestChannel.Request) {
case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request)
}
def handleLeaderAndIsrRequest(request: RequestChannel.Request) {
val correlationId = request.header.correlationId
val leaderAndIsrRequest = request.body[LeaderAndIsrRequest]
// 副本leadership变更回调方法
def onLeadershipChange(updatedLeaders: Iterable[Partition], updatedFollowers: Iterable[Partition]) {
// 如果topic为内部topic:GROUP_METADATA_TOPIC_NAME或TRANSACTION_STATE_TOPIC_NAME
// 通过groupCoordinator/txnCoordinator进行迁移工作
updatedLeaders.foreach { partition =>
if (partition.topic == GROUP_METADATA_TOPIC_NAME)
groupCoordinator.handleGroupImmigration(partition.partitionId)
else if (partition.topic == TRANSACTION_STATE_TOPIC_NAME)
txnCoordinator.handleTxnImmigration(partition.partitionId, partition.getLeaderEpoch)
}
updatedFollowers.foreach { partition =>
if (partition.topic == GROUP_METADATA_TOPIC_NAME)
groupCoordinator.handleGroupEmigration(partition.partitionId)
else if (partition.topic == TRANSACTION_STATE_TOPIC_NAME)
txnCoordinator.handleTxnEmigration(partition.partitionId, partition.getLeaderEpoch)
}
}
if (authorize(request.session, ClusterAction, Resource.ClusterResource)) {
// 调用replicaManager.becomeLeaderOrFollower()逐个对分区进行处理
val response = replicaManager.becomeLeaderOrFollower(correlationId, leaderAndIsrRequest, onLeadershipChange)
sendResponseExemptThrottle(request, response)
} else {
// 身份校验失败
}
}
handleLeaderAndIsrRequest()方法中在验证身份通过情况下,调用replicaManager.becomeLeaderOrFollower()方法处理请求,该方法针对本broker是否是某partition的leader分别做不同操作,具体实现如下:
// ReplicaManager.scala
def becomeLeaderOrFollower(correlationId: Int,
leaderAndIsrRequest: LeaderAndIsrRequest,
onLeadershipChange: (Iterable[Partition], Iterable[Partition]) => Unit): LeaderAndIsrResponse = {
replicaStateChangeLock synchronized {
if (leaderAndIsrRequest.controllerEpoch < controllerEpoch) {
// 请求中epoch过期,直接返回错误码
} else {
val responseMap = new mutable.HashMap[TopicPartition, Errors]
val controllerId = leaderAndIsrRequest.controllerId
controllerEpoch = leaderAndIsrRequest.controllerEpoch
// First check partition's leader epoch
val partitionState = new mutable.HashMap[Partition, LeaderAndIsrRequest.PartitionState]()
// 根据ReplicaManager的缓存过滤出之前未保存过的topicPartition
val newPartitions = leaderAndIsrRequest.partitionStates.asScala.keys.filter(topicPartition => getPartition(topicPartition).isEmpty)
// 对leaderAndIsrRequest请求中的tp逐个处理
leaderAndIsrRequest.partitionStates.asScala.foreach { case (topicPartition, stateInfo) =>
val partition = getOrCreatePartition(topicPartition)
val partitionLeaderEpoch = partition.getLeaderEpoch
if (partition eq ReplicaManager.OfflinePartition) {
// partition已经离线
responseMap.put(topicPartition, Errors.KAFKA_STORAGE_ERROR)
} else if (partitionLeaderEpoch < stateInfo.basePartitionState.leaderEpoch) {
if(stateInfo.basePartitionState.replicas.contains(localBrokerId))
// 合法的epoch,且本地brokerid在assigned列表中
partitionState.put(partition, stateInfo)
else {
// brokerId不在副本的assigned列表中
responseMap.put(topicPartition, Errors.UNKNOWN_TOPIC_OR_PARTITION)
}
} else {
// 其他情况,记录错误在返回结果集中
responseMap.put(topicPartition, Errors.STALE_CONTROLLER_EPOCH)
}
}
// partitionState经过上面的逐个校验,里面存放的都是通过检验的请求数据
//如果partition的leader与本地brokerId一致,说明该分区的leader为本机器上的副本
val partitionsTobeLeader = partitionState.filter { case (_, stateInfo) =>
stateInfo.basePartitionState.leader == localBrokerId
}
// 否则本地的副本为follower副本
val partitionsToBeFollower = partitionState -- partitionsTobeLeader.keys
// 如果那些标记本地broker为leader的tp列表partitionsTobeLeader不为空,则调用makeLeaders()方法进行一些副本leader的工作
val partitionsBecomeLeader = if (partitionsTobeLeader.nonEmpty)
// 使得本地副本为leader需要做:
// 1. 停止partition对应的fetch线程
// 2. 更新缓存中分区的metadata数据
// 3. 将该partition加入到partitionleader集合中
makeLeaders(controllerId, controllerEpoch, partitionsTobeLeader, correlationId, responseMap)
else
Set.empty[Partition]
// 标记本地副本为follower副本,则调用makeFollowers()方法做副本工作
val partitionsBecomeFollower = if (partitionsToBeFollower.nonEmpty)
//对于给定的这些副本,将本地副本设置为 follower
// 1. 从 leader partition 集合移除这些 partition;
// 2. 将这些 partition 标记为 follower,之后这些 partition 就不会再接收 produce 的请求了;
// 3. 停止对这些 partition 的副本同步,这样这些副本就不会再有(来自副本请求线程)的数据进行追加了;
// 4. 对这些 partition 的 offset 进行 checkpoint,如果日志需要截断就进行截断操作;
// 5. 清空 purgatory 中的 produce 和 fetch 请求;
// 6. 如果 broker 没有掉线,向这些 partition 的新 leader 启动副本同步线程;
//通过这些操作的顺序性,保证了这些副本在 offset checkpoint 之前将不会接收新的数据,
//这样的话,在 checkpoint 之前这些数据都可以保证刷到磁盘
makeFollowers(controllerId, controllerEpoch, partitionsToBeFollower, correlationId, responseMap)
else
Set.empty[Partition]
leaderAndIsrRequest.partitionStates.asScala.keys.foreach(topicPartition =>
//处理offline partition,在allPartitions中设置(tp, OfflinePartition)
if (getReplica(topicPartition).isEmpty && (allPartitions.get(topicPartition) ne ReplicaManager.OfflinePartition))
allPartitions.put(topicPartition, ReplicaManager.OfflinePartition)
)
// 第一次处理leaderisrrequest请求时初始化highwatermark线程,定期为各个partition写入highwatermark到highwatermark文件中
if (!hwThreadInitialized) {
startHighWaterMarksCheckPointThread()
hwThreadInitialized = true
}
// 处理newPartitions
val newOnlineReplicas = newPartitions.flatMap(topicPartition => getReplica(topicPartition))
// Add future replica to partition's map
val futureReplicasAndInitialOffset = newOnlineReplicas.filter { replica =>
logManager.getLog(replica.topicPartition, isFuture = true).isDefined
}.map { replica =>
replica.topicPartition -> BrokerAndInitialOffset(BrokerEndPoint(config.brokerId, "localhost", -1), replica.highWatermark.messageOffset)
}.toMap
futureReplicasAndInitialOffset.keys.foreach(tp => getPartition(tp).get.getOrCreateReplica(Request.FutureLocalReplicaId))
futureReplicasAndInitialOffset.keys.foreach(logManager.abortAndPauseCleaning)
replicaAlterLogDirsManager.addFetcherForPartitions(futureReplicasAndInitialOffset)
// 关闭空闲的fetcher线程
replicaFetcherManager.shutdownIdleFetcherThreads()
replicaAlterLogDirsManager.shutdownIdleFetcherThreads()
// 调用回调方法,用于处理group,txn的迁移工作
onLeadershipChange(partitionsBecomeLeader, partitionsBecomeFollower)
new LeaderAndIsrResponse(Errors.NONE, responseMap.asJava)
}
}
}
ReplicaManager.becomeLeaderOrFollower()方法中如果本Broker为分区的leader,则调用 makeLeaders()方法进行停止fetcher线程,更新缓存等。如果本Broker为分区的follower,则调用makeFollowers(), 该方法中更新缓存,停止接收Producer请求,对日志进行offset进行处理,并且在broker可用情况下向新的leader开启同步线程。下面看两个方法的具体实现过程。
// ReplicaManager.scala
private def makeLeaders(controllerId: Int,
epoch: Int,
partitionState: Map[Partition, LeaderAndIsrRequest.PartitionState],
correlationId: Int,
responseMap: mutable.Map[TopicPartition, Errors]): Set[Partition] = {
for (partition <- partitionState.keys)
responseMap.put(partition.topicPartition, Errors.NONE)
val partitionsToMakeLeaders = mutable.Set[Partition]()
try {
// 停止partition对应的fetch线程
replicaFetcherManager.removeFetcherForPartitions(partitionState.keySet.map(_.topicPartition))
// Update the partition information to be the leader
partitionState.foreach{ case (partition, partitionStateInfo) =>
try {
// 对每个partition分别调用makeLeader()方法,使得当前partition成为leader
// 如果makeLeader方法中,更新isr队列,在allReplicasMap缓存中移除那些被controller删除的副本brokerId
// 并且将follower副本逐个设置lastFetchLeaderLogEndOffset,lastFetchTimeMs,_lastCaughtUpTimeMs等offset变量
// 如果本leader副本为新的leader副本,则为新leader副本创建highWatermarkMetadata
// 并更新lastfetch信息
// makeLeader返回结果为是否是新leader
if (partition.makeLeader(controllerId, partitionStateInfo, correlationId)) {
partitionsToMakeLeaders += partition
} else // 与之前的leaderId一致
// log
} catch {
// 异常处理
}
}
} catch {
// 异常处理
}
//other log ...
partitionsToMakeLeaders
}
private def makeFollowers(controllerId: Int,
epoch: Int,
partitionStates: Map[Partition, LeaderAndIsrRequest.PartitionState],
correlationId: Int,
responseMap: mutable.Map[TopicPartition, Errors]) : Set[Partition] = {
// other code ...
for (partition <- partitionStates.keys)
responseMap.put(partition.topicPartition, Errors.NONE)
val partitionsToMakeFollower: mutable.Set[Partition] = mutable.Set()
// other code ...
try {
// TODO: Delete leaders from LeaderAndIsrRequest
partitionStates.foreach { case (partition, partitionStateInfo) =>
val newLeaderBrokerId = partitionStateInfo.basePartitionState.leader
try {
metadataCache.getAliveBrokers.find(_.id == newLeaderBrokerId) match
//当且仅当leader是否可用时变更副本状态
case Some(_) =>
// 当副本leader可用时,通过partition.makeFollower()方法进行设置leader,清空isr的工作
// 如果缓存中的leaderReplicaIdOpt与本次发送过来请求中一致,则makeFollower返回false,否则更新leaderReplicaIdOpt并返回true
if (partition.makeFollower(controllerId, partitionStateInfo, correlationId))
partitionsToMakeFollower += partition
else
// 旧的leader和新的leader一致
case None =>
// 即便leader不可用,但是任然创建本地副本,保证本地副本的watermark存在于checkpoint文件中
partition.getOrCreateReplica(isNew = partitionStateInfo.isNew)
}
} catch {
// handle exception code ...
}
}
// 通过replicaFetcherManager将那些leader有变化的副本的同步线程移除,后面会重新添加对应的同步线程
replicaFetcherManager.removeFetcherForPartitions(partitionsToMakeFollower.map(_.topicPartition))
//
partitionsToMakeFollower.foreach { partition =>
val topicPartitionOperationKey = new TopicPartitionOperationKey(partition.topicPartition)
// 将为延迟完成的Produce, Fetch工作做完
tryCompleteDelayedProduce(topicPartitionOperationKey)
tryCompleteDelayedFetch(topicPartitionOperationKey)
}
if (isShuttingDown.get()) {
// 如果isShuttingDown,则跳过添加后台同步线程
}
else {
// 从缓存中读取leader的endpoint及本replica的hiehwatermark的offset
val partitionsToMakeFollowerWithLeaderAndOffset = partitionsToMakeFollower.map(partition =>
partition.topicPartition -> BrokerAndInitialOffset(
metadataCache.getAliveBrokers.find(_.id == partition.leaderReplicaIdOpt.get).get.brokerEndPoint(config.interBrokerListenerName),
partition.getReplica().get.highWatermark.messageOffset)).toMap
//
replicaFetcherManager.addFetcherForPartitions(partitionsToMakeFollowerWithLeaderAndOffset)
}
}
} catch {
// handle exception code ...
}
}
partitionsToMakeFollower
}
在ReplicaManager.makeFollowers()方法调用了replicaFetcherManager.addFetcherForPartitions()方法进行后台同步线程的创建。为每个变更了leader的副本创建一个ReplicaFetcherThread后台线程并启动,用于副本的主从同步。
// AbstractFetcherManager.scala
def addFetcherForPartitions(partitionAndOffsets: Map[TopicPartition, BrokerAndInitialOffset]) {
lock synchronized {
// 通过简单的hash运算获得FetcherId,并与broker组成key,将partitionAndOffsets进行group
val partitionsPerFetcher = partitionAndOffsets.groupBy { case(topicPartition, brokerAndInitialFetchOffset) =>
BrokerAndFetcherId(brokerAndInitialFetchOffset.broker, getFetcherId(topicPartition.topic, topicPartition.partition))}
def addAndStartFetcherThread(brokerAndFetcherId: BrokerAndFetcherId, brokerIdAndFetcherId: BrokerIdAndFetcherId) {
// 创建ReplicaFetcherThread线程并启动
val fetcherThread = createFetcherThread(brokerAndFetcherId.fetcherId, brokerAndFetcherId.broker)
fetcherThreadMap.put(brokerIdAndFetcherId, fetcherThread)
fetcherThread.start
}
for ((brokerAndFetcherId, initialFetchOffsets) <- partitionsPerFetcher) {
val brokerIdAndFetcherId = BrokerIdAndFetcherId(brokerAndFetcherId.broker.id, brokerAndFetcherId.fetcherId)
// 如果缓存中存在brokerIdAndFetcherId,且host,port都一致,则直接复用,
// 其他情况停止原来线程(如果有),并且新建后台线程并启动
fetcherThreadMap.get(brokerIdAndFetcherId) match {
case Some(f) if f.sourceBroker.host == brokerAndFetcherId.broker.host && f.sourceBroker.port == brokerAndFetcherId.broker.port =>
// reuse the fetcher thread
case Some(f) =>
f.shutdown()
addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId)
case None =>
addAndStartFetcherThread(brokerAndFetcherId, brokerIdAndFetcherId)
}
// 调用addPartitions()方法进行对offset进行处理
fetcherThreadMap(brokerIdAndFetcherId).addPartitions(initialFetchOffsets.map { case (tp, brokerAndInitOffset) =>
tp -> brokerAndInitOffset.initOffset
})
}
}
// log code ...
}
特别地,AbstractFetcherThread.addPartitions()中,如果offset超过了范围,则需要调用ReplicaFetcherThread.handleOffsetOutOfRange()方法进行截断处理,并返回可以新的offsetToFetch。该方法中,如果leaderEndOffset<本地副本的offset,则截断本地副本日志。
如果leaderEndOffset >= replica.logEndOffset.messageOffset。出现这种情况,可能是是follower宕机很久了,可能他的endOffset都小于leader的beginOffset,另一种情况是脏选举的发生。这种情况下可能出现数据不一致的情况,Kafka并未提供解决方案,与前面那种情况合并,Kafka处理的方案是发送ListOffsetRequest请求获取leader的beginOffset,在leaderStartOffset和本地副本logEndOffset取较大值作为fetch的起始。如果这种情况下将本地log都截断掉,设置leaderStartOffset为本地log的起始offset,等待同步线程拉取数据。
ReplicaFetcherThread
至此,正式引入我们这篇博文的主题: ReplicaFetcherThread。该线程继承自AbstractFetcherThread,而AbstractFetcherThread又继承自ShutdownableThread。在ShutdownableThread的run()方法中可以看到后台线程是一直循环调用doWork()进行发送fetch请求并处理结果。我们直接看AbstractFetcherThread的doWork()方法。
// AbstractFetcherThread.scala
override def doWork() {
// 每次doWork()先调用maybeTruncate()方法,从leader获取epochandoffset,更新本地副本fetchOffset,是否截断等
maybeTruncate()
val fetchRequest = inLock(partitionMapLock) {
// 通过ReplicaFetcherThread.buildFetchRequest()方法构造fetchrequest,在请求中,对每个tp逐个设置拉取的offset,startoffset,fetchsize等,最终形成一个整个的请求
val ResultWithPartitions(fetchRequest, partitionsWithError) = buildFetchRequest(states)
if (fetchRequest.isEmpty) {
// log code ...
partitionMapCond.await(fetchBackOffMs, TimeUnit.MILLISECONDS)
}
handlePartitionsWithErrors(partitionsWithError)
fetchRequest
}
// 如果构建的请求不为empty,则调用processFetchRequest()处理请求
if (!fetchRequest.isEmpty)
processFetchRequest(fetchRequest)
}
private def processFetchRequest(fetchRequest: REQ) {
val partitionsWithError = mutable.Set[TopicPartition]()
var responseData: Seq[(TopicPartition, PD)] = Seq.empty
try {
// 发送请求并阻塞直到结果返回
responseData = fetch(fetchRequest)
} catch {
case t: Throwable =>
// 异常处理,发生异常则等待一段时间
}
fetcherStats.requestRate.mark()
if (responseData.nonEmpty) {
// process fetched data
inLock(partitionMapLock) {
// 返回结果不为空,则逐个tp进行结果处理
responseData.foreach { case (topicPartition, partitionData) =>
val topic = topicPartition.topic
val partitionId = topicPartition.partition
Option(partitionStates.stateValue(topicPartition)).foreach(currentPartitionFetchState =>
// 结果返回期间可能发生了日志阶段或者分区被删除重加等操作,因此这里只对offset与请求offset一致,并且PartitionFetchState的状态为isReadyForFetch的情况下进行处理
if (fetchRequest.offset(topicPartition) == currentPartitionFetchState.fetchOffset &&
currentPartitionFetchState.isReadyForFetch) {
partitionData.error match {
case Errors.NONE =>
try {
val records = partitionData.toRecords
val newOffset = records.batches.asScala.lastOption.map(_.nextOffset).getOrElse(
currentPartitionFetchState.fetchOffset)
fetcherLagStats.getAndMaybePut(topic, partitionId).lag = Math.max(0L, partitionData.highWatermark - newOffset)
// 调用子类实现的processPartitionData()方法处理返回结果
processPartitionData(topicPartition, currentPartitionFetchState.fetchOffset, partitionData)
val validBytes = records.validBytes
// 如果validBytes>0 ,且后台线程没有将tp从partitionStates移除
if (validBytes > 0 && partitionStates.contains(topicPartition)) {
// 更新tp的分区状态信息
partitionStates.updateAndMoveToEnd(topicPartition, new PartitionFetchState(newOffset))
fetcherStats.byteRate.mark(validBytes)
}
} catch {
// 异常处理
}
case Errors.OFFSET_OUT_OF_RANGE =>
try {
// 如果为OFFSET_OUT_OF_RANGE异常,则根据返回结果进行日志截断,截断过程和AbstractFetcherThread.addPartitions()处理规程一致
val newOffset = handleOffsetOutOfRange(topicPartition)
// 更新offset缓存
partitionStates.updateAndMoveToEnd(topicPartition, new PartitionFetchState(newOffset))
} catch {
// exception handle code ...
}
// exception handle code ...
}
})
}
}
}
// 错误处理
if (partitionsWithError.nonEmpty) {
debug(s"Handling errors for partitions $partitionsWithError")
handlePartitionsWithErrors(partitionsWithError)
}
}
副本主从同步过程中,processFetchRequest()方法在处理正常结果情况下会调用ReplicaFetcherThread.processPartitionData()对fetch回的结果进行处理。
// ReplicaFetcherThread.scala
def processPartitionData(topicPartition: TopicPartition, fetchOffset: Long, partitionData: PartitionData) {
val replica = replicaMgr.getReplicaOrException(topicPartition)
val partition = replicaMgr.getPartition(topicPartition).get
val records = partitionData.toRecords
maybeWarnIfOversizedRecords(records, topicPartition)
// 确保开始fetchOffset与现有分区log的endOffset一致才写入数据
if (fetchOffset != replica.logEndOffset.messageOffset)
throw new IllegalStateException("Offset mismatch for partition %s: fetched offset = %d, log end offset = %d.".format(
topicPartition, fetchOffset, replica.logEndOffset.messageOffset))
// trace log code ...
// Append the leader's messages to the log
// 作为follower将leader的同步结果append到本地副本log中,append()的细节在前一篇介绍log读写的分析博文中有具体介绍,这里不再展开
partition.appendRecordsToFollower(records)
// trace log code ...
// 在本地副本的logEndOffset.messageOffset和返回结果partitionData.highWatermark中取较小值作为followerHighWatermark,来更新副本内存缓存的highWatermark
val followerHighWatermark = replica.logEndOffset.messageOffset.min(partitionData.highWatermark)
val leaderLogStartOffset = partitionData.logStartOffset
replica.highWatermark = new LogOffsetMetadata(followerHighWatermark)
// 如果leaderlogStartOffset<本地highWatermark.messageOffset,且newLogStartOffset > logStartOffset,
// 则更新本地的log start offset
replica.maybeIncrementLogStartOffset(leaderLogStartOffset)
if (quota.isThrottled(topicPartition))
quota.record(records.sizeInBytes)
replicaMgr.brokerTopicStats.updateReplicationBytesIn(records.sizeInBytes)
}
至此,从controller到同步线程的拉取数据同步循环就介绍完毕了。
总结
本文从KafkaServer的启动切入,介绍了集群在启动时全局会选举一个Controller,负责Topic创建删除,副本选举,副本重新分配等事件的处理。在启动后向各个Broker发送各自所有的分区对应的LeaderAndIsrRequest。各个Broker对所拥有的副本做处理。特别地,如果本地副本角色为follower,则开启同步线程定期从leader中拉取数据进行,并修改本地offset等缓存。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号