特征工程(Feature Engineering)
一、特征工程的重要性
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已,在楼主本人亲自做的机器学习项目中也发现,不同的机器学习算法对结果的准确率影响有限,好的特征工程以及数据集才影响到了模型本质的结果。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过总结和归纳,人们认为特征工程包括以下方面:
该图引用于别人的博客,在文章的最后可以看到参考链接。
但根据我个人的理解,这张图虽然比较全面,但是我认为特征工程的核心工作是一个线性的阶段性的过程,而不是图中描述的很多并行化过程。
特征工程主要有三个主要阶段,本文也将从这三个阶段讲解特征工程:1、特征清洗、数据清洗。2、特征处理、数据处理。3、特征选择
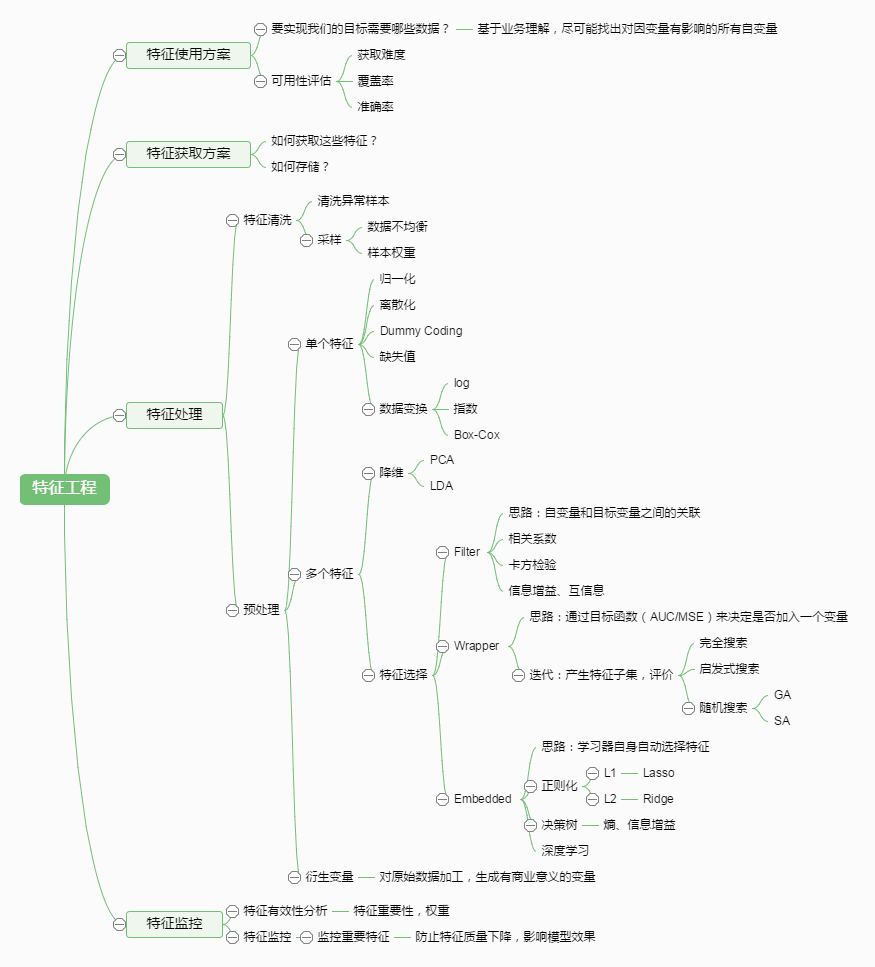
特征是机器学习系统的原材料,对最终模型的影响是毋庸置疑的。定义:特征工程是将原始数据转化为特征,更好表示预测模型处理的实际问题,提升对于未知数据的准确性。它是用目标问题所在的特定领域知识或者自动化的方法来生成、提取、删减或者组合变化得到特征。
数据特征会直接影响你使用的预测模型和实现的预测结果。准备和选择的特征越好,则实现的结果越好。影响预测结果好坏的因素:模型的选择、可用的数据、特征的提取。
优质的特征往往描述了数据的固有结构。大多数模型都可以通过数据中良好的结构很好的学习,即使不是最优的模型,优质的特征也可以得到不错的效果。优质特征的灵活性可以让你使用简单的模型运算的更快,更容易理解,更容易维护。优质的特征可以在使用不是最优的模型参数的情况下得到不错的预测结果,这样你就不必费力去选择最适合的模型和最优的参数了。
首先,我们大家都知道,数据特征会直接影响我们模型的预测性能。你可以这么说:“选择的特征越好,最终得到的性能也就越好”。这句话说得没错,但也会给我们造成误解。事实上,你得到的实验结果取决于你选择的模型、获取的数据以及使用的特征,甚至你问题的形式和你用来评估精度的客观方法也扮演了一部分。此外,你的实验结果还受到许多相互依赖的属性的影响,你需要的是能够很好地描述你数据内部结构的好特征。
(1)特征越好,灵活性越强
只要特征选得好,即使是一般的模型(或算法)也能获得很好的性能,因为大多数模型(或算法)在好的数据特征下表现的性能都还不错。好特征的灵活性在于它允许你选择不复杂的模型,同时运行速度也更快,也更容易理解和维护。
(2)特征越好,构建的模型越简单
有了好的特征,即便你的参数不是最优的,你的模型性能也能仍然会表现的很nice,所以你就不需要花太多的时间去寻找最有参数,这大大的降低了模型的复杂度,使模型趋于简单。
(3)特征越好,模型的性能越出色
显然,这一点是毫无争议的,我们进行特征工程的最终目的就是提升模型的性能。
惰性是推动科技发展的动力,很多算法工程也在思考,能不能通过模型的方式来自动的学习和构成特征呢?"所有的想法都会有实现的一天",现在市面上有效的特征构造模型有 FM(Factorization Machine 因子分解机)、深度学习(提取训练好的模型中隐层作为特征)可以自己学习出一些特征以及特征之间的组合关系,有人使用过主题模型 LDA、word2vec、FM 来作为特征生成的模型,将模型训练的中间结果,比如 LDA 的主题分布、word2vec 生成的词向量用于 LR 这样的线性模型,线上测试效果都非常好。
通过上面的例子我们可以知道特征构造大致思路,也就是从场景目标出发,去找出与之有关的因素。但是在实际场景除了天马行空想特征之外,还需要对于想出来的特征做一可行性评估:获取难度、覆盖度、准确度等,比如笛卡尔积会使得特征维度增加的非常快,会出现大量覆盖度低的特征,如果把这些覆盖度低的特征加入到模型中训练,模型会非常不稳定;然而这一系列的工作就是传说中的特征工程。
下面从特征工程的多个子问题全方位分析特种工程。
二、特征工程的子问题
通过特征提取,我们能得到未经处理的特征,这时的特征可能有以下问题:
- 不属于同一量纲:即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
- 信息冗余:对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题。
- 定性特征不能直接使用:某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。通常使用哑编码的方式将定性特征转换为定量特征:假设有N种定性值,则将这一个特征扩展为N种特征,当原始特征值为第i种定性值时,第i个扩展特征赋值为1,其他扩展特征赋值为0。哑编码的方式相比直接指定的方式,不用增加调参的工作,对于线性模型来说,使用哑编码后的特征可达到非线性的效果。
- 存在缺失值:缺失值需要补充。
- 信息利用率低:不同的机器学习算法和模型对数据中信息的利用是不同的,之前提到在线性模型中,使用对定性特征哑编码可以达到非线性的效果。类似地,对定量变量多项式化,或者进行其他的转换,都能达到非线性的效果。
在模型训练过程中,我们会对训练数据集进行抽象、抽取大量特征,这些特征中有离散型特征也有连续型特征。若此时你使用的模型是简单模型(如LR),那么通常我们会对连续型特征进行离散化操作,然后再对离散的特征,进行one-hot编码或哑变量编码。这样的操作通常会使得我们模型具有较强的非线性能力。
1. 特征清洗、数据清洗
在实际生产环境中,业务数据并非如我们想象那样完美,可能存在各种问题,比如上报异常、恶意作弊行为、爬虫抓取等。为了让模型能够学到真实的行为规律,我们需要对已经构造的原始特征进行清洗,排除掉脏数据。主要包括一下两个方面:
1. 结合业务情况进行数据的过滤,例如去除 crawler 抓取,spam,作弊等数据。
2. 异常点检测,采用异常点检测算法对样本进行分析,常用的异常点检测算法包括
-
- 偏差检测,例如聚类,最近邻等。
- 基于统计的异常点检测算法
例如极差,四分位数间距,均差,标准差等,这种方法适合于挖掘单变量的数值型数据。全距(Range),又称极差,是用来表示统计资料中的变异量数(measures of variation) ,其最大值与最小值之间的差距;四分位距通常是用来构建箱形图,以及对概率分布的简要图表概述。
-
- 基于距离的异常点检测算法,
主要通过距离方法来检测异常点,将数据集中与大多数点之间距离大于某个阈值的点视为异常点,主要使用的距离度量方法有绝对距离 ( 曼哈顿距离 ) 、欧氏距离和马氏距离等方法。
-
- 基于密度的异常点检测算法
考察当前点周围密度,可以发现局部异常点,例如 LOF 算法
2. 特征处理、数据处理
1) 连续型特征
-
归一化
归一化有很多好处,比如可以加快梯度下降寻找最优解的速度,可以提升模型的精度,同时也使得特征之间具有可比性,当然所有的事情都是双面的,经过归一化处理之后,会损失掉源特征的一些信息,但这个损失相对应带来的好处我们还是可以接受的。
归一化可以分为以下三种类型:
- 线性归一化:
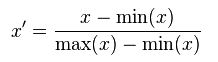
这种归一化方法比较适用在数值比较集中的情况。这种方法有个缺陷,如果 max 和 min 不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。实际使用中可以用经验常量值来替代 max 和 min。
使用preproccessing库的MinMaxScaler类对数据进行区间缩放的代码如下:
from sklearn.preprocessing import MinMaxScaler MinMaxScaler().fit_transform(iris.data)
- 标准化归一化:
在完全随机的情况下,我们可以假设我们的数据是符合标准正态分布的,也就是均值为 0,标准差为 1;那么其归一化函数如下:
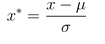
from sklearn.preprocessing import StandardScaler #标准化归一化 StandardScaler().fit_transform(iris.data)
- 非线性归一化:
在数据分化比较大的场景中,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 log、指数,正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如 log(V, 2) 还是 log(V, 10) 等。
实际业务中我们可以根据自己对数据的理解进行不同的归一化方法,下面是手游推荐业务使用到的归一化函数:
正向特征,特征越大打分越大,例如付费金额
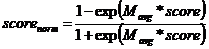 ,其中
,其中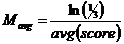
反向特征,特征越大打分越小,例如首次付费距离当前天数
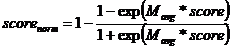 ,其中
,其中
汇总特征,取均值,例如活跃天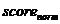 =score/天数
=score/天数
这样的归一化为啥会比其他归一化更好呢!或许数学家们可以从公式上进行推到证明,而我们的理解是,其实每个业务的数据都会有特定的分布,比如完全随机的时候数据满足正态分布,那么所选择的方法必须要符合这种数据分布的特点,一般情况下会根据自己对业务数据的了解,对公式进行调整,但是归一化的思路还是跟上面提到的一样的。
-
离散化
离散化可以理解为将连续的特征值转换为为离散的特征值的过程,也称为分区或分箱。离散化对于线性模型来说是非常有帮助的,原因是它可以将目标值 Y 与特征值的线性转为目标值与离散化之后转化的向量里的每个元素之间的线性关系,这样向量的每个分量都有一个权重,引入了非线性,提升了模型拟合能力。之前做过实验,使用同样的特征,有经过离散化处理的特征训练出来的模型,会比没有经过离散化训练出来的模型效果好 20%以上;现在使用比较多的特征离散化的方法有,等频离散、等距离散、树模型离散。
arr = np.random.randn(20) pd.cut(arr , 4)
[(-1.234, -0.551], (-1.234, -0.551], (-0.551, 0.13], (0.81, 1.491], (-1.234, -0.551], ..., (-0.551, 0.13], (-0.551, 0.13], (0.13, 0.81], (0.81, 1.491], (0.81, 1.491]] Length: 20 Categories (4, interval[float64]): [(-1.234, -0.551] < (-0.551, 0.13] < (0.13, 0.81] < (0.81, 1.491]]
arr = np.random.randn(20) pd.cut(arr , [-5,-1,0,1,5])
[(0, 1], (-1, 0], (0, 1], (-1, 0], (0, 1], ..., (-5, -1], (-1, 0], (-5, -1], (0, 1], (-5, -1]] Length: 20 Categories (4, interval[int64]): [(-5, -1] < (-1, 0] < (0, 1] < (1, 5]
2) 离散型特征
一些属性是类别型而不是数值型,举一个简单的例子,由{红,绿、蓝}组成的颜色属性,最常用的方式是把每个类别属性转换成二元属性,即从{0,1}取一个值。因此基本上增加的属性等于相应数目的类别,并且对于你数据集中的每个实例,只有一个是1(其他的为0),这也就是独热(one-hot)编码方式(类似于转换成哑变量)。
如果你不了解这个编码的话,你可能会觉得分解会增加没必要的麻烦(因为编码大量的增加了数据集的维度)。相反,你可能会尝试将类别属性转换成一个标量值,例如颜色属性可能会用{1,2,3}表示{红,绿,蓝}。这里存在两个问题:首先,对于一个数学模型,这意味着某种意义上红色和绿色比和蓝色更“相似”(因为|1-3| > |1-2|)。除非你的类别拥有排序的属性(比如铁路线上的站),这样可能会误导你的模型。然后,可能会导致统计指标(比如均值)无意义,更糟糕的情况是,会误导你的模型。还是颜色的例子,假如你的数据集包含相同数量的红色和蓝色的实例,但是没有绿色的,那么颜色的均值可能还是得到2,也就是绿色的意思。
one-hot编码和dummy编码是比较像的两种编码,两者的区别是,如果离散型特征有5个属性,one-hot编码会生成5个特征,而dummy编码则生成4个。
from sklearn.preprocessing import OneHotEncoder data = iris.target.reshape((-1,1)) print(data.shape) data = OneHotEncoder().fit_transform(data) print(data.shape)
(150, 1) (150, 3)
3) 时间型特征
时间特征既可以看作是连续型,也可以看作是离散型。
连续型:持续时间(单页浏览时长)、间隔时间(上次购买、点击离现在的时间)
离散型:哪个时段(0-24),星期几,工作日/周末/法定假日。
4) 文本型特征
文本型特征常见的处理方法有两类,第一类采用最普通的词袋(bag of words)模型,以及在此基础上加入ngram扩充词袋,以及使用tfidf加权特征值。第二类是基于Word2vec生成词向量。
-
词袋模型
文本数据预处理后,去掉停用词,剩下的词组成的list, 在词库中的映射稀疏向量,这就是词袋模型。以下摘自sklearn文档
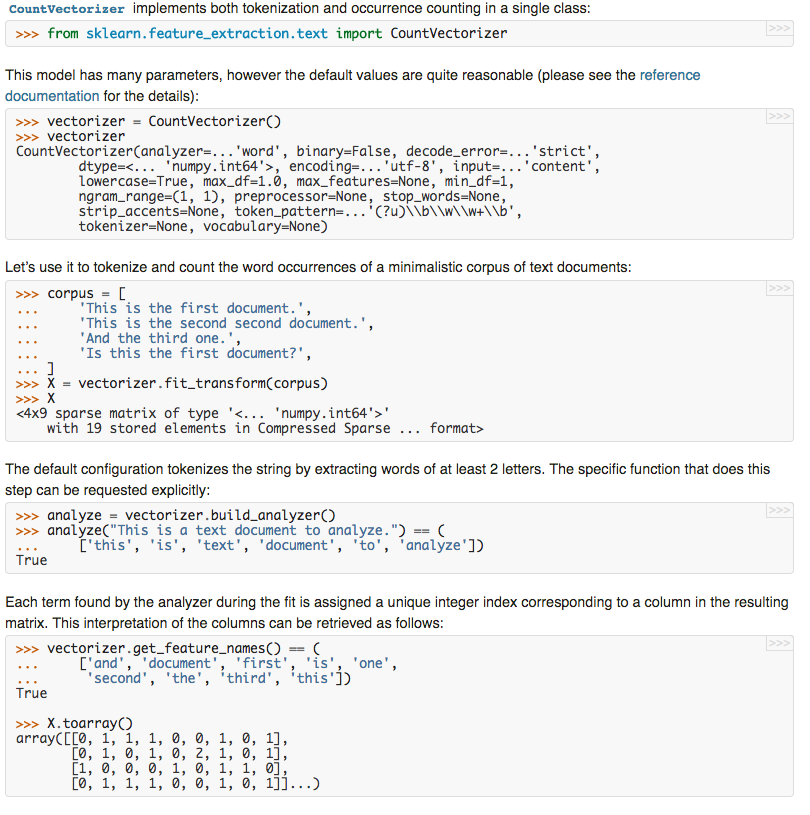
-
词袋模型 + ngram
由于普通的词袋模型没有很好的考虑上下文的关系,只把每个单词当做单个特征来处理,因此就有了ngram改进普通的词袋模型,普通的词袋模型是1-gram,两个单词为2-gram,以此类推。
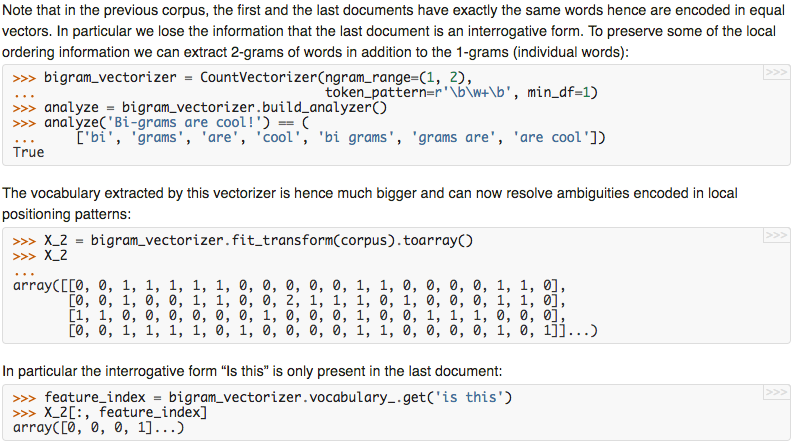
-
词袋模型 + ngram + tfidf加权
原本的词袋模型其实是表征的词袋中每一个词在该文档中的出现次数 ,但如果这个词仅在所以样本中都出现了很多次,该词的特征值就失去了良好的特征表达能力,因此就出现了tfidf来平衡权值。TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。
在一份给定的文件里,词频(term frequency,TF)指的是某一个给定的词语在该文件中出现的频率。这个数字是对词数(term count)的归一化,以防止它偏向长的文件。(同一个词语在长文件里可能会比短文件有更高的词数,而不管该词语重要与否。)对于在某一特定文件里的词语 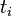 来说,它的重要性可表示为:
来说,它的重要性可表示为:
以上式子中 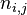 是该词 在文件
是该词 在文件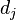 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
逆向文件频率(inverse document frequency,IDF)是一个词语普遍重要性的度量。某一特定词语的IDF,可以由总文件数目除以包含该词语之文件的数目,再将得到的商取对数得到
 ,有时候为了防止出现0的情况,会加上平滑
,有时候为了防止出现0的情况,会加上平滑 。
。
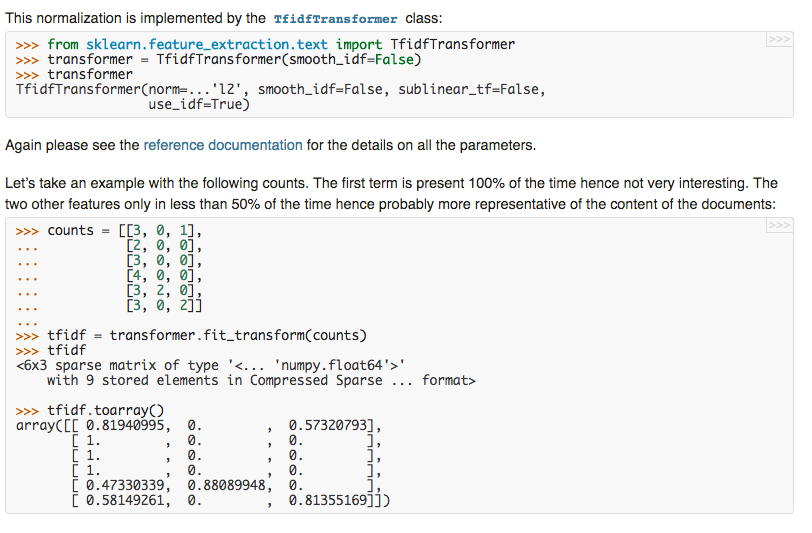
-
word2vec
前面提到的基于词袋的三种特征方法是自然语言处理以前的方法,都是会生成很稀疏的矩阵,而且对表达词与词之间的相似性能力有限。而word2vec可以将自然语言中的字词转为计算机可以理解的稠密向量(Dense Vector)。Python版的word2vec工具箱:gensim
2013年,Google开源了一款用于词向量计算的工具——word2vec,引起了工业界和学术界的关注。首先,word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练;其次,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。在本文,由于篇幅原因,就不对word2vec做详细的原理介绍,以后会专门写一篇介绍Word2vec原理的文章。
5) 统计型特征
当前样本集的各种统计信息,包括均值、最大值、1分位数、4分位数等。
import pandas as pd
import numpy as np
series = pd.Series(np.random.randn(500))
series.describe()
count 500.000000
mean -0.063427
std 1.007670
min -3.032698
25% -0.749055
50% 0.001290
75% 0.607432
max 2.900834
dtype: float64
6) 组合特征(交叉特征)
-
简单特征组合:拼接型
1.user_id&&category: 10001&&女裙,10002&&男士牛仔
2.user_id&&style:10001&&蕾丝,10002&&全棉
实际应用过程中不会直接将用户id号和商品组合而产生非常稀疏的矩阵,会事先对用户做一个聚类。
-
模型特征组合:GBDT
GBDT + LR是一套经典的特征组合+训练的方式,最早由Facebook提出。
思路大概是用先用GBDT训练模型,由于树模型是具有很好的解释性的,从根节点到叶子节点的路径就是一条特征组合,然后可以将组合特征和原始特征一起训练。
7) 缺失值处理
在实际业务中,可能会因为各种原因会造成数据的缺失,比如某些用户年龄、性别、设备这类型的特征无法获取到,同时线上模型又有使用这些类型的特征,那么缺失了这些特征的用户在线上打分的时候会出现比较大的偏差;通常会有几种方式来进行处理:数值型特征可以使用均值或者中位数进行简单的替换,年龄这类型的特征可以通过关系链进行加权打分,当然也可以通过把缺失的全部都归为一类,用户默认值来替代。
当然对于新用户或者新 item 来说其实也是属于一种缺失值情况,对于这种情况已经属于领一个非常大的领域,那就是推荐系统的启动问题。对于冷启动我问题,现在的做法会从两个方面着手,一种是通过集体智慧来解决,另外一种是通过网络模型;第一种方法就是使用协同过滤的思想,与这个新用户类似的用户表现来知道新用户的推荐。第二种利用网络把 item 周围信息考虑进去,比如下面会提到的层次平滑,热传导模型也可以通过引入基础属性到二部图中,达到解决冷启动问题。
3. 特征选择
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
- 特征是否发散:如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性:这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
特征选择的原因是因为特征维度太高,可能出现冗余:部分特征的相关度太高了,消耗计算性能;也可能会出现噪声:部分特征是对预测结果没有帮助甚至有负影响。
特征选择的目的是选择模型最优特征子集。特征与特征之间多多少少会有一些相互作用,比如有些特征是包含其他特征,有些特征与另一些特征存在相关性的,也有一些特征需要与其他特征组合起来才能起作用,还有一些特征是会存在负相关的,如果只使用正是因为特征之间的这些关系,合理的选择适合的特征集合对于模型效果有非常大的作用。现有的特征选择方法可以大体分成三种类型:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
特征选择主要有两个目的:
- 减少特征数量、降维,使模型泛化能力更强,减少过拟合;
- 增强对特征和特征值之间的理解。
1) Filter(过滤法)
这种方法是衡量单个特征值与目标变量也就是样本 label 值之间的关联。但这种方法的缺点是没有考虑到特征之间的关联,有可能把有用的关联特征过滤掉。
对于分类问题(y离散),可采用:
卡方检验,互信息
对于回归问题(y连续),可采用:
皮尔森相关系数,最大信息系数
-
互信息和最大信息系数 (Mutual information and maximal information coefficient (MIC)
经典的互信息(互信息为随机变量X与Y之间的互信息I(X;Y)I(X;Y)为单个事件之间互信息的数学期望)也是评价定性自变量对定性因变量的相关性的,互信息计算公式如下:

互信息直接用于特征选择其实不是太方便:1、它不属于度量方式,也没有办法归一化,在不同数据及上的结果无法做比较;2、对于连续变量的计算不是很方便(X和Y都是集合,x,y都是离散的取值),通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
最大信息系数克服了这两个问题。它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。
from sklearn.feature_selection import SelectKBest from minepy import MINE #由于MINE的设计不是函数式的,定义mic方法将其为函数式的,返回一个二元组,二元组的第2项设置成固定的P值0.5 def mic(x, y): m = MINE() m.compute_score(x, y) return (m.mic(), 0.5) #选择K个最好的特征,返回特征选择后的数据 SelectKBest(lambda X, Y: array(map(lambda x:mic(x, Y), X.T)).T, k=2).fit_transform(iris.data, iris.target)
MIC的统计能力遭到了一些质疑 ,当零假设不成立时,MIC的统计就会受到影响。在有的数据集上不存在这个问题,但有的数据集上就存在这个问题。
-
卡方检验
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:

from sklearn.datasets import load_iris from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import chi2 iris = load_iris() X, y = iris.data, iris.target X.shape (150, 4) X_new = SelectKBest(chi2, k=2).fit_transform(X, y) X_new.shape (150, 2)
-
Pearson相关系数
皮尔森相关系数是一种最简单的,能帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全的负相关,+1表示完全的正相关,0表示没有线性相关。
Pearson Correlation速度快、易于计算,经常在拿到数据(经过清洗和特征提取之后的)之后第一时间就执行。Scipy的 pearsonr 方法能够同时计算 相关系数 和p-value.
import numpy as np from scipy.stats import pearsonr np.random.seed(0) size = 300 x = np.random.normal(0, 1, size) # pearsonr(x, y)的输入为特征矩阵和目标向量 print("Lower noise", pearsonr(x, x + np.random.normal(0, 1, size))) print("Higher noise", pearsonr(x, x + np.random.normal(0, 10, size))) >>> # 输出为二元组(sorce, p-value)的数组 Lower noise (0.71824836862138386, 7.3240173129992273e-49) Higher noise (0.057964292079338148, 0.31700993885324746)
-
基于模型的特征排序 (Model based ranking)
这种方法的思路是直接使用你要用的机器学习算法,针对每个单独的特征和响应变量建立预测模型。假如特征和响应变量之间的关系是非线性的,可以用基于树的方法(决策树、随机森林)、或者扩展的线性模型 等。基于树的方法比较易于使用,因为他们对非线性关系的建模比较好,并且不需要太多的调试。但要注意过拟合问题,因此树的深度最好不要太大,再就是运用交叉验证。
在我之前讲解随机森林模型的博客中介绍了随机森林的一个重要特性OOB估计,可以在不进行交叉验证的情况下高效的计算特征对模型的重要程度。
from sklearn.cross_validation import cross_val_score, ShuffleSplit from sklearn.datasets import load_boston from sklearn.ensemble import RandomForestRegressor import numpy as np # Load boston housing dataset as an example boston = load_boston() X = boston["data"] Y = boston["target"] names = boston["feature_names"] rf = RandomForestRegressor(n_estimators=20, max_depth=4) scores = [] # 单独采用每个特征进行建模,并进行交叉验证 for i in range(X.shape[1]): score = cross_val_score(rf, X[:, i:i+1], Y, scoring="r2", # 注意X[:, i]和X[:, i:i+1]的区别 cv=ShuffleSplit(len(X), 3, .3)) scores.append((format(np.mean(score), '.3f'), names[i])) print(sorted(scores, reverse=True))
-
方差选择法
这种方法和前几种方法不太一样,前几种方法是计算单个特征与结果值之间的相关程度从而删选特征,这种方法仅从特征的统计特性来考虑,没有考虑和结果值之间的相关度。
假设某特征的特征值只有0和1,并且在所有输入样本中,95%的实例的该特征取值都是1,那就可以认为这个特征作用不大。如果100%都是1,那这个特征就没意义了。当特征值都是离散型变量的时候这种方法才能用,如果是连续型变量,就需要将连续变量离散化之后才能用。而且实际当中,一般不太会有95%以上都取某个值的特征存在,所以这种方法虽然简单但是不太好用。可以把它作为特征选择的预处理,先去掉那些取值变化小的特征,然后再从接下来提到的的特征选择方法中选择合适的进行进一步的特征选择。
from sklearn.feature_selection import VarianceThreshold X = [[0, 0, 1], [0, 1, 0], [1, 0, 0], [0, 1, 1], [0, 1, 0], [0, 1, 1]] sel = VarianceThreshold(threshold=(.8 * (1 - .8))) sel.fit_transform(X) array([[0, 1], [1, 0], [0, 0], [1, 1], [1, 0], [1, 1]])
2) Wrapper(包装法)
Wrapper 这一类特征选择方法,应该来说是比较科学的,但是也是非常耗时,工业界在生产环境中很少使用,非常耗时,也是一个 NP 复杂的问题,一般通过不断迭代,然后每次加入一个特征,来训练模型,使用模型评估比如 AUC 或者 MSE 等函数评估是否将特征加入到特征子集中。
递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,移除若干权值系数的特征,再基于新的特征集进行下一轮训练。
sklearn官方解释:对特征含有权重的预测模型(例如,线性模型对应参数coefficients),RFE通过递归减少考察的特征集规模来选择特征。首先,预测模型在原始特征上训练,每个特征指定一个权重。之后,那些拥有最小绝对值权重的特征被踢出特征集。如此往复递归,直至剩余的特征数量达到所需的特征数量。
RFECV 通过交叉验证的方式执行RFE,以此来选择最佳数量的特征:对于一个数量为d的feature的集合,他的所有的子集的个数是2的d次方减1(包含空集)。指定一个外部的学习算法,比如SVM之类的。通过该算法计算所有子集的validation error。选择error最小的那个子集作为所挑选的特征。
from sklearn.feature_selection import RFE from sklearn.linear_model import LogisticRegression #递归特征消除法,返回特征选择后的数据 #参数estimator为基模型 #参数n_features_to_select为选择的特征个数 RFE(estimator=LogisticRegression(), n_features_to_select=2).fit_transform(iris.data, iris.target)
3) Embedded(包装法)
单变量特征选择方法独立的衡量每个特征与响应变量之间的关系,另一种主流的特征选择方法是基于机器学习模型的方法。有些机器学习方法本身就具有对特征进行打分的机制,或者很容易将其运用到特征选择任务中,例如回归模型,SVM,决策树,随机森林等等。
-
基于惩罚项的特征选择法
之前我写的一篇文章对比了L1、L2正则化的区别,L1正则化具有截断性,L2正则化具有缩放效应,所以我们可以很好的利用线性模型的两种正则化选择特征、
使用L1范数作为惩罚项的线性模型(Linear models)会得到稀疏解:大部分特征对应的系数为0。当你希望减少特征的维度以用于其它分类器时,可以通过 feature_selection.SelectFromModel 来选择不为0的系数。特别指出,常用于此目的的稀疏预测模型有 linear_model.Lasso(回归), linear_model.LogisticRegression 和 svm.LinearSVC(分类):
from sklearn.feature_selection import SelectFromModel from sklearn.linear_model import LogisticRegression #带L1惩罚项的逻辑回归作为基模型的特征选择 SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(iris.data, iris.target)
-
基于树模型的特征选择法
GBDT在计算每个节点的重要程度时可以同时用来做特征选择,RF可以用他的OOB估计来评价特征的重要程度
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型,来选择特征的代码如下:
from sklearn.feature_selection import SelectFromModel from sklearn.ensemble import GradientBoostingClassifier #GBDT作为基模型的特征选择 SelectFromModel(GradientBoostingClassifier()).fit_transform(iris.data, iris.target)
4. 特征评估
前面写了很多特征构造和处理的方法,可能更多时间我们更想知道一个特征是否真的靠谱,在时间有限的情况下,用贪心的思想,每次选择表现最好的特征加入到模型训练中,这个时候就会特征评估这个东西了,特征评估可能会从几个维度进行衡量:
1、特征自身的质量
-
- 特征覆盖度,这个指标是衡量某个特征能够影响的样本量,一般情况下,会排查覆盖度特别低的
- 特征的准确性,也就是说特征值是否考虑,会不会存在太多错误数据
- 特征方差,衡量特征是否有区分度,比如 100 个训练样本,有 99 个是 0,那么这个特征方差就特别低,肯定有问题。
2、特征与目标值的相关性
-
- 相关系数
- 单特征 AUC
5. 降维
当特征选择完成后,可以直接训练模型了,但是可能由于特征矩阵过大,导致计算量大,训练时间长的问题,因此降低特征矩阵维度也是必不可少的。常见的降维方法除了以上提到的基于L1惩罚项的模型以外,另外还有主成分分析法(PCA)和线性判别分析(LDA),线性判别分析本身也是一个分类模型。PCA和LDA有很多的相似点,其本质是要将原始的样本映射到维度更低的样本空间中,但是PCA和LDA的映射目标不一样:PCA是为了让映射后的样本具有最大的发散性;而LDA是为了让映射后的样本有最好的分类性能。所以说PCA是一种无监督的降维方法,而LDA是一种有监督的降维方法。
from sklearn.decomposition import PCA #主成分分析法,返回降维后的数据 #参数n_components为主成分数目 PCA(n_components=2).fit_transform(iris.data)
参考链接:
https://cloud.tencent.com/developer/article/1005443
http://www.cnblogs.com/jasonfreak/p/5448385.html
https://www.cnblogs.com/lianyingteng/p/7792693.html
http://blog.csdn.net/sangyongjia/article/details/52440063
https://www.cnblogs.com/iloveai/p/word2vec.html
https://www.cnblogs.com/stevenlk/p/6543628.html
寒小阳-特征工程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号