分布式锁解决 集群下一人一单问题的理论
分布式锁的定义
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁
前面sychronized锁失效的原因是
- 原本,由于每一个JVM都有一个独立的锁监视器,用于监视当前JVM中的sychronized锁,所以无法保障多个集群下只有一个线程访问一个代码块。
- 所以直接将使用一个分布锁,在整个系统的全局中设置一个锁监视器,从而保障不同节点的JVM都能够识别,从而实现集群下只允许一个线程访问一个代码块
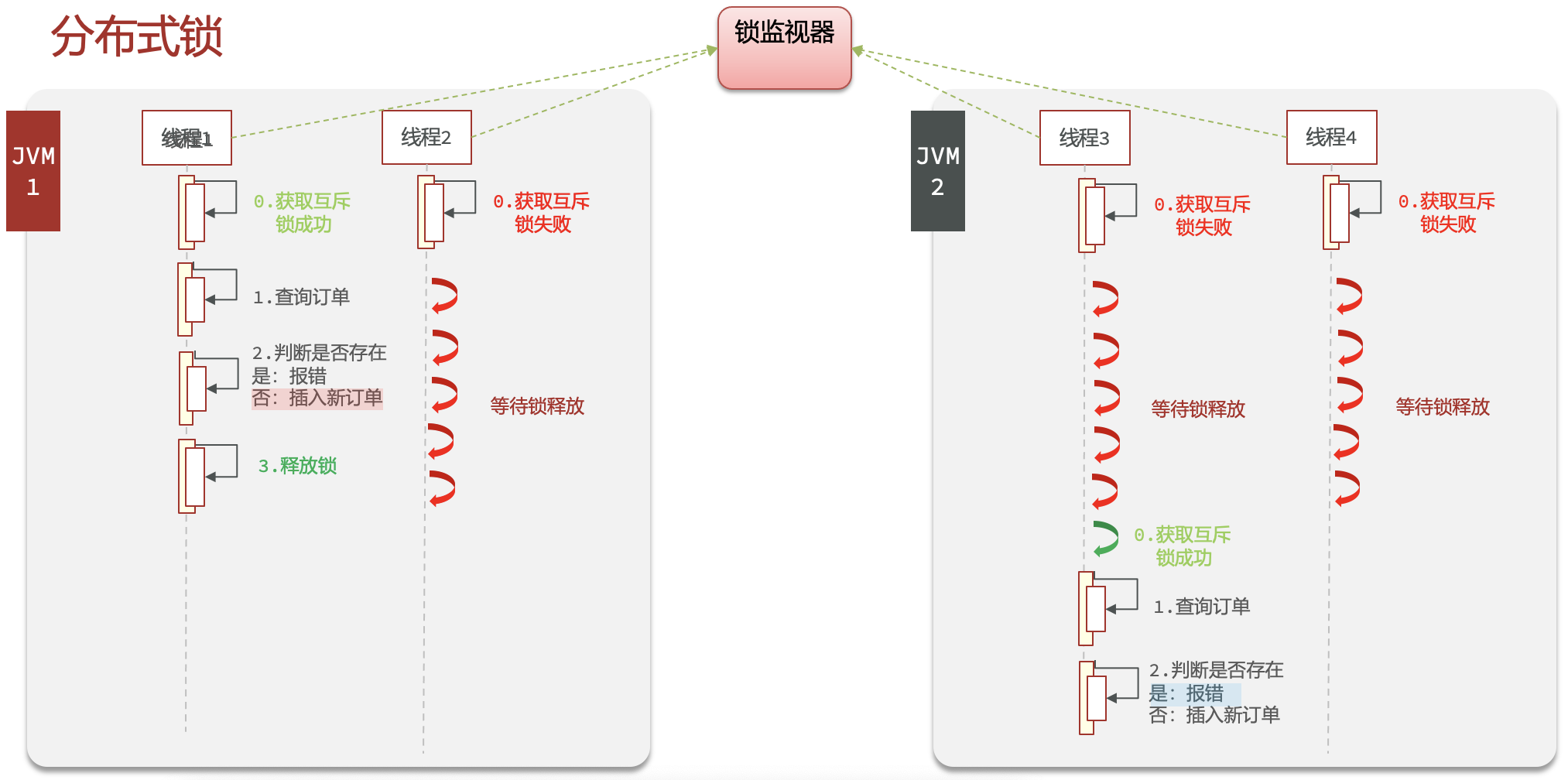
分布式锁的特点
- 多线程可见。
- 互斥。分布式锁必须能够确保在任何时刻只有一个节点能够获得锁,其他节点需要等待。
- 高可用。分布式锁应该具备高可用性,即使在网络分区或节点故障的情况下,仍然能够正常工作。(容错性)当持有锁的节点发生故障或宕机时,系统需要能够自动释放该锁,以确保其他节点能够继续获取锁。
- 高性能。分布式锁需要具备良好的性能,尽可能减少对共享资源的访问等待时间,以及减少锁竞争带来的开销。
- 安全性。
- (可重入性)如果一个节点已经获得了锁,那么它可以继续请求获取该锁而不会造成死锁。
- (锁超时机制)为了避免某个节点因故障或其他原因无限期持有锁而影响系统正常运行,分布式锁通常应该设置超时机制,确保锁的自动释放。
分布式锁的常见实现方式
| MySQL | Redis | Zookeeper | |
|---|---|---|---|
| 互斥 | 利用MySQL本身的互斥锁机制 | 利用setnx这样的互斥命令 | 利用节点的唯一性和有序性实现互斥 |
| 高可用 | Good | Good | Good |
| 高性能 | 一般 | Good | 一般 |
| 安全性 | 断开连接,自动释放 | 利用锁超时时间,到期释放 | 临时节点,断开连接自动释放 |
- 基于关系数据库:
- 可以利用数据库的事务特性和唯一索引来实现分布式锁。
- 通过向数据库插入一条具有唯一约束的记录作为锁,
- 其他进程在获取锁时会受到数据库的并发控制机制限制。
- 基于缓存(如Redis):
- 使用分布式缓存服务(如Redis)提供的原子操作来实现分布式锁。
- 通过将锁信息存储在缓存中,其他进程可以通过检查缓存中的锁状态来判断是否可以获取锁。
- 基于ZooKeeper:
- ZooKeeper是一个分布式协调服务,可以用于实现分布式锁。
- 通过创建临时有序节点,
- 每个请求都会尝试创建一个唯一的节点,并检查自己是否是最小节点,如果是,则表示获取到了锁。
- 基于分布式算法:
- 还可以利用一些分布式算法来实现分布式锁,例如Chubby、DLM(Distributed Lock Manager)等。
- 这些算法通过在分布式系统中协调进程之间的通信和状态变化,实现分布式锁的功能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号