减小内存的占用问题——享元模式和单例模式的对比分析
前言
接口的常用用法都有什么?策略模式复习总结 的话题提起了:如何解决策略类膨胀的问题,说到
“有时候可以通过把依赖于环境Context类的状态保存到客户端里面,而将策略类设计成可共享的,这样策略类实例可以被不同客户端使用。”
换言之,可以使用享元模式来减少对象的数量,享元模式它的英文名字叫 Flyweigh 模式,翻译为羽量级(搏击比赛的术语,也就是轻量级的体现)模式,它是构造型模式之一,它通过与其他类似对象共享数据来减小内存占用,也正应了它的名字:享-分享。
那么享元模式到底是什么样子的呢?下面看个例子,有一个文档,里面写了很多英文,大家知道英文字母有26个,大小写一起一共是52个:

保存这个文件的时候,所有单词都占据了一份内存,每个字母都是一个对象,如果文档里的字母有重复的,怎么办?
难道每次都要创建新的字母对象去保存么?答案是否定的,其实每个字母只需要创建一次,然后把他们保存起来,当再次使用的时候直接在已经创建好的字母里取就ok了,这就是享元模式的一个思想的体现。
说到这儿,其实想起了Java的String类,这个类就是应用了享元模式
享元模式的样子
先看享元模式的具体实现例子:
抽象享元角色(接口或者抽象类):所有具体享元类的父类,规定一些需要实现的公共接口
具体享元角色:抽象享元角色的具体实现类,并实现了抽象享元角色规定的方法
享元工厂角色:负责创建和管理享元角色。它必须保证享元对象可以被系统适当地共享。当一个客户端对象调用一个享元对象的时候,享元工厂角色会检查系统中是否已经有一个符合要求的享元对象。如果已经有了,享元工厂角色就应当提供这个已有的享元对象,如果系统中没有一个适当的享元对象的话,享元工厂角色就应当创建一个合适的享元对象。
生成字符的例子
代码如下:
public interface ICharacter { /** * 享元模式的抽象享元角色,所有具体享元类的父类,规定一些需要实现的公共接口。其实没有这个接口也可以的。 * 显式我自己的字母 */ void displayCharacter(); } /** * 具体的享元模式角色 */ public class ChracterBuilder implements ICharacter { private char aChar; public ChracterBuilder(char c) { this.aChar = c; } @Override public void displayCharacter() { System.out.println(aChar); } } // 享元工厂类 public class FlyWeightFactory { /** * 享元工厂里维护一个内存的“共享池”,来避免大量相同内容对象的开销。这种开销最常见、最直观的就是内存的损耗。 * 我们这里使用数组也行,或者 HashMap(concurrenthashmap等) */ private Map<Character, ICharacter> characterPool; public FlyWeightFactory() { this.characterPool = new HashMap<>(); } public ICharacter getICharater(Character character) { // 创建(获得)一个对象的时候,先去 pool 里判断,是否已经存在 ICharacter iCharacter = this.characterPool.get(character); if (iCharacter == null) { // 如果共享池里没有,才 new 一个新的,并同时加到 pool 里,缓存起来 iCharacter = new ChracterBuilder(character); this.characterPool.put(character, iCharacter); } // 否则,直接从pool里取出,不再新建 return iCharacter; } }
客户端调用,下面的客户端代码其实不是享元模式的真正体现,只是普通的调用,为了对比说明问题:
public class MainFlyWeight { public static void main(String[] args) { // 不用享元模式,我们每次创建相同内容的字母的时候,都要new一个新的对象 ICharacter iCharacter = new ChracterBuilder('a'); ICharacter iCharacter1 = new ChracterBuilder('b'); ICharacter iCharacter2 = new ChracterBuilder('b'); ICharacter iCharacter3 = new ChracterBuilder('b'); ICharacter iCharacter4 = new ChracterBuilder('b'); iCharacter.displayCharacter(); iCharacter1.displayCharacter(); iCharacter2.displayCharacter(); iCharacter3.displayCharacter(); iCharacter4.displayCharacter(); if (iCharacter2 == iCharacter1) { System.out.print("true"); } else { // 执行后,发现打印了 false,说明是两个不同的对象 System.out.print("false"); } }
下面使用享元模式,必须指出的是,使用享元模式,那么客户端绝对不可以直接将具体享元类实例化,而必须通过工厂得到享元对象
public class MainFlyWeight { public static void main(String[] args) { // 使用享元模式,必须指出的是,客户端不可以直接将具体享元类实例化,而必须通过一个工厂 FlyWeightFactory flyWeightFactory = new FlyWeightFactory(); ICharacter iCharacter = flyWeightFactory.getICharater('a'); ICharacter iCharacter1 = flyWeightFactory.getICharater('b'); ICharacter iCharacter2 = flyWeightFactory.getICharater('b'); iCharacter.displayCharacter(); iCharacter1.displayCharacter(); iCharacter2.displayCharacter(); if (iCharacter1 == iCharacter2) { // 确实打印了 =============,说明对象共享了 System.out.print("============"); } } }
打印的都一样,但是对象使用的内存却不一样了,减少了内存的占用。
类图如下:
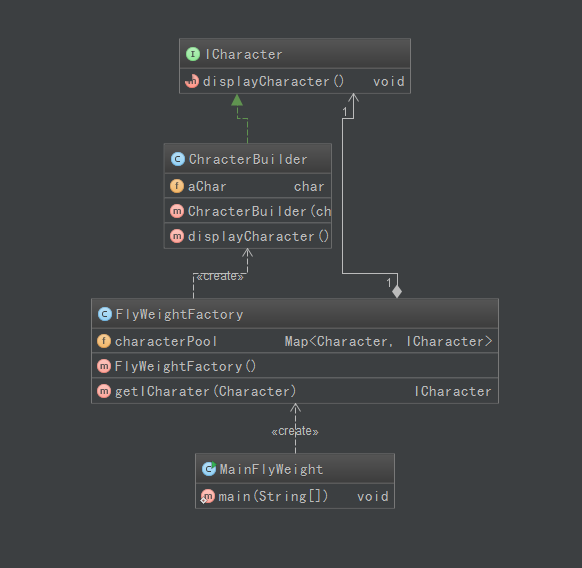
一般而言,享元工厂对象在整个系统中只有一个,因此也可以使用单例模式,由工厂方法产生所需要的享元对象。且设计模式不用拘泥于具体代码, 代码实现可能有n多种方式,n多语言……
教师管理的例子
再看一例子,需求很简单。有一个老师类,继承 Person 类,老师类里保存一个数字编号,客户端可以通过它来找到对应的老师。
为了节省篇幅,简单的堆砌一个 name 信息即可。
其中享元工厂类设计为单例的。
public class Person { private String name;/** * person是享元抽象角色 */ public Person(String name) {this.name = name; } public Person() { }public String getName() { return name; } public void setName(String name) { this.name = name; } } // 具体享元角色 public class Teacher extends Person { private int number; public Teacher(int number, String name) { super(name); this.number = number; } public Teacher() { super(); } public int getNumber() { return number; } public void setNumber(int number) { this.number = number; } } // 享元工厂类,设计为单例的 public class TeacherFactory { private Map<Integer, Teacher> integerTeacherMapPool; private TeacherFactory() { this.integerTeacherMapPool = new HashMap<>(); } public static TeacherFactory getInstance() { return Holder.instance; } public Teacher getTeacher(int num) { Teacher teacher = integerTeacherMapPool.get(num); if (teacher == null) { // TODO 模拟用,不要把 teacher 写死,每次使用 set teacher = new Teacher(); teacher.setNumber(num); integerTeacherMapPool.put(num, teacher); } return teacher; } private static class Holder { private static final TeacherFactory instance = new TeacherFactory(); } } /////// 客户端,查询老师 public class MainClass { public static void main(String[] args) { // 先创建工厂 TeacherFactory teacherFactory = TeacherFactory.getInstance(); // 通过工厂得到具体老师对象 Teacher teacher = teacherFactory.getTeacher(1000); Teacher teacher1 = teacherFactory.getTeacher(1001); Teacher teacher2 = teacherFactory.getTeacher(1000); System.out.println(teacher.getNumber()); System.out.println(teacher1.getNumber()); System.out.println(teacher2.getNumber()); // 判断是否是相等对象 if (teacher == teacher2) { // 确实打印了,ok System.out.print("____________-"); } } }
享元模式的使用场景
1、应用程序的底层性能优化时常用的一种策略
比如,一个系统中存在着大量的细粒度对象,且这些细粒度对象耗费了大量的内存。这里也要明白,享元模式比起工厂,单例,策略,装饰,观察者等模式,其实不算是常用的设计模式,它主要用在底层的设计上比较多,比如 JDK 的 String 类,Integer 的 valueOf(int)方法等。
2、管理大量相似对象的一种策略,可以理解为缓存的实现方案
其实感觉1和2是一个意思。。。
3、大量的细粒度对象的状态中的大部分都可以外部化
理解对象的内部状态和外部状态两个概念
现在多了几个新的概念(外部化,内部,外部状态……):
内部状态:存储在享元对象内部的对象(可以理解为其内部的一些稳定的属性),这些属性对象是不会随环境的改变而变化的。正因为这个原因,一个享元对象才可以被共享
外部状态:对象的一些属性会随环境的改变而改变,属于不稳定的属性,故这些属性对象不可以被共享。
由此得到一个结论:享元对象的外部状态必须由客户端保存,并在享元对象被创建之后,在需要使用的时候再传入到享元对象内部。外部状态不可以影响享元对象的内部状态,它们是相互独立的
满足以上的这些条件的系统才可以使用享元模式。
回忆之前的教师管理例子:具体享元角色类Teacher类的int类型的number属性,其实就是一个内部状态,它的值会在享元对象被创建时赋予,也就是所谓的内部状态对象让享元对象自己去保存,且可以被客户端共享,所有的内部状态在对象创建之后,就不再改变。
具有外部状态的享元模式实现——模拟数据库连接池小例子
这个教师管理的例子,其享元对象没有外部状态,下面看一个具有外部状态+内部状态的享元模式例子——常见的一些数据库连接池,其实就是利用享元模式对数据库连接进行封装和共享。
如果一个享元对象有外部状态,所有的外部状态都必须存储在客户端,在使用享元对象时,再由客户端传入享元对象。
public interface BaseDao { /** * 连接数据源,享元模式的抽象享元角色 * @param session String 数据源连接的session,该参数就是外部状态 */ void connect(String session); }
例子里只有一个外部状态——connect()方法的参数 session,实际上这个 session 是很复杂的,我们这里简单的用 string 代替。
外部状态:对象的一些属性会随环境的改变而改变,属于不稳定的属性,故这些属性对象不可以被共享。
享元对象的外部状态必须由客户端保存,并在享元对象被创建之后,在需要使用的时候再传入到享元对象内部。
外部状态不可以影响享元对象的内部状态,它们是相互独立的
public class DaoA implements BaseDao { /** * 内部状态,存储每个数据库连接的一些信息,这里也用字符串简化了 */ private String strConn = null; /** * 内部状态在创建享元对象的时候作为参数传入构造器 */ public DaoA(String s) { this.strConn = s; } /** * 外部状态 session 作为参数传入抽象方法,可以改变方法的行为,但是对于内部状态不做改变,两者独立 * 外部状态(对象)存储在客户端,当客户端使用享元对象的时候才被传入享元对象,而不是开始就有。*/ @Override public void connect(String session) { System.out.print("内部状态 是" + this.strConn); System.out.print("外部状态 是" + session); } }
享元工厂
public enum Factory { /** * 单例模式的最佳实现是使用枚举类型。只需要编写一个包含单个元素的枚举类型即可 * 简洁,且无偿提供序列化,并由JVM从根本上提供线程安全的保障,绝对防止多次实例化,且能够抵御反射和序列化的攻击。 */ instance; /** * 可以有自己的操作 */ private Map<String, BaseDao> stringBaseDaoMapPool = new HashMap<>(); public BaseDao factory(String s) { BaseDao baseDao = this.stringBaseDaoMapPool.get(s); if (baseDao == null) { baseDao = new DaoA(s); this.stringBaseDaoMapPool.put(s, baseDao); } return baseDao; } }
下面是客户端调用,虽然客户端申请了三个享元对象,但是实际创建的享元对象只有两个,这就是共享的含义
public class Client { public static void main(String[] args) { BaseDao baseDao = Factory.instance.factory("A连接数据源"); BaseDao baseDao1 = Factory.instance.factory("B连接数据源"); BaseDao baseDao2 = Factory.instance.factory("A连接数据源"); baseDao.connect("session1"); baseDao1.connect("session2"); baseDao2.connect("session1"); if (baseDao == baseDao2) { // 确实打印了 System.out.print("==========="); } } }
享元模式的优点和缺陷
享元模式的优点在于,它能大幅度地降低内存中对象的数量。但是,它做到这一点所付出的代价也是很高的:
1、享元模式使得系统更加复杂。
为了使对象可以共享,需要将一些状态外部化,这使得程序的逻辑复杂化
2、享元模式将享元对象的状态外部化,而读取外部状态使得运行时间稍微变长
3、享元模式需要维护一个记录了系统已有的所有享元的哈希表,也称之为对象池,这也需要耗费一定的资源。应当在有足够多的享元实例可供共享时才值得使用享元模式。
单例模式和享元模式的比较
享元模式到这里总结的差不多了,前面的享元模式的例子,工厂Factory类使用了单例模式实现,那么这里还要顺便总结一个老生常谈,但是又不见得真的谈对了的设计模式——单例模式。
具体细节:最简单的设计模式——单例模式的演进和推荐写法(Java 版)。
下面是简单分析:
享元是对象级别的:在多个使用到这个对象的地方都只需要使用这一个对象即可满足要求。
单例是类级别的:这个类必须只能实例化出一个对象。
可以这么说:单例是享元的一种特例。设计模式不用拘泥于具体代码, 代码实现可能有 n 多种方式,而单例可以看做是享元的实现方式中的一种,只不过他比享元更加严格的控制了对象的唯一性。
享元模式和线程安全
前面的例子都是使用的 hashmap,作为对象池,如果在多线程的场景下,是否安全呢?
答案是否定的,必须给工厂里的 getxxx 方法加锁,比如直接使用 synchronized 关键字即可。看下面例子:
public class TeacherFactory { private Map<Integer, Teacher> integerTeacherMapPool; private TeacherFactory() { this.integerTeacherMapPool = new HashMap<>(); } public static TeacherFactory getInstance() { return Holder.instance; } public synchronized Teacher getTeacher(int num) { Teacher teacher = integerTeacherMapPool.get(num); if (teacher == null) { // TODO 模拟用,不要把 teacher 写死,每次使用 set teacher = new Teacher(); teacher.setNumber(num); integerTeacherMapPool.put(num, teacher); } return teacher; } private static class Holder { private static final TeacherFactory instance = new TeacherFactory(); } }
如果不加锁,可能有如下场景:
| 线程1 | 线程2 |
| 执行 getTeacher(100) 方法 | |
| 判断拿出的对象是否为 null | |
| 为 null,new Teacher | |
| 执行 getTeacher(100) 方法 | |
| 判断拿出的对象是否为 null | |
| 为 null,new Teacher | |
| put 到对象池 | |
| put 到对象池 |
当然,也可以直接使用 concurrentHashMap
在JDK中有哪些使用享元模式的例子?举例说明。
说两个,一个是String类,第二个是java.lang.Integer 的 valueOf(int)方法。
String 类
针对String,也是老生常谈了,它是final的,字符串常量通常是在编译的时候就确定好的,定义在类的方法区里。如下:
String s1 = "hello"; String s2 = "he" + "llo"; if (s1 == s2) { System.out.print("====");// 打印了,说明 s1,s2 引用了同一个对象 hello }
使用相同的字符序列,而不是使用 new 关键字创建的两个字符串,会创建指向Java字符串常量池中的同一个字符串的指针。字符串常量池是 Java 节约资源的一种方式,其实就是使用了享元模式的思想。
字符串的分配,和其他的对象分配一样,耗费高昂的时间与空间代价,JVM 为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。
字符串类维护了一个字符串池,每当代码创建字符串常量时,JVM 会首先检查字符串常量池,如果字符串已经在池中,就返回池中的实例的引用;如果字符串不在池中,就会实例化一个字符串并放到池中,Java能够进行这样的优化是因为字符串是不可变的,可以不用担心数据冲突
java.lang.Integer 的 valueOf(int)方法源码分析(8.0版本)
先看一个例子A
Integer a = 1; Integer b = 1; System.out.print(a == b); // true
再看一例子B
// 再看一例子; Integer a = new Integer(1); Integer b = new Integer(1); System.out.print(a == b); // false
如上比较的结果很容易理解,再看一个“奇怪的”例子C
Integer a = 200; Integer b = 200; System.out.println(a == b); // false
比较的结果怎么还是 false 呢? 例子 A 里明明是 true,为什么到了例子 C 里就是 false 了?
反编译上述程序,看看发生了什么
public static main([Ljava/lang/String;)V L0 LINENUMBER 19 L0 SIPUSH 200 INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer; // 发现每次都是使用了自动装箱 ASTORE 1 L1 LINENUMBER 20 L1 SIPUSH 200 INVOKESTATIC java/lang/Integer.valueOf (I)Ljava/lang/Integer; ASTORE 2
发现每次赋值的时候,都会自动调用其自动装箱方法,如下
Integer c = Integer.valueOf(200);
再看该方法源码
public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }
发现,当使用Integer的自动装箱时,i 值在 cache 的 low 和 high 之间时,会用缓存保存起来,供客户端多次使用,以节约内存。如果不在这个范围内,则创建一个新的 Integer 对象,这就是享元模式的设计思想。
看看范围:-128~+127
欢迎关注
dashuai的博客是终身学习践行者,大厂程序员,且专注于工作经验、学习笔记的分享和日常吐槽,包括但不限于互联网行业,附带分享一些PDF电子书,资料,帮忙内推,欢迎拍砖!



private static class IntegerCache { static final int low = -128; static final int high; static final Integer cache[]; static { // high value may be configured by property int h = 127; String integerCacheHighPropValue = sun.misc.VM.getSavedProperty("java.lang.Integer.IntegerCache.high"); if (integerCacheHighPropValue != null) { try { int i = parseInt(integerCacheHighPropValue); i = Math.max(i, 127); // Maximum array size is Integer.MAX_VALUE h = Math.min(i, Integer.MAX_VALUE - (-low) -1); } catch( NumberFormatException nfe) { // If the property cannot be parsed into an int, ignore it. } } high = h; cache = new Integer[(high - low) + 1]; int j = low; for(int k = 0; k < cache.length; k++) cache[k] = new Integer(j++); // range [-128, 127] must be interned (JLS7 5.1.7) assert IntegerCache.high >= 127; } private IntegerCache() {} }


 欢迎关注微信公众号
欢迎关注微信公众号