
Fluent Operator:云原生日志管理的一把瑞士军刀
作者:程德昊,Fluent Member,KubeSphere Member
Fluent Operator 介绍
随着云原生技术的快速发展,技术的不断迭代,对于日志的采集、处理及转发提出了更高的要求。云原生架构下的日志方案相比基于物理机或者是虚拟机场景的日志架构设计存在很大差别。作为 CNCF 的毕业项目,Fluent Bit 无疑为解决云环境中的日志记录问题的首选解决方案之一。但是在 Kubernetes 中安装部署以及配置 Fluent Bit 都具有一定的门槛,加大了用户的使用成本。
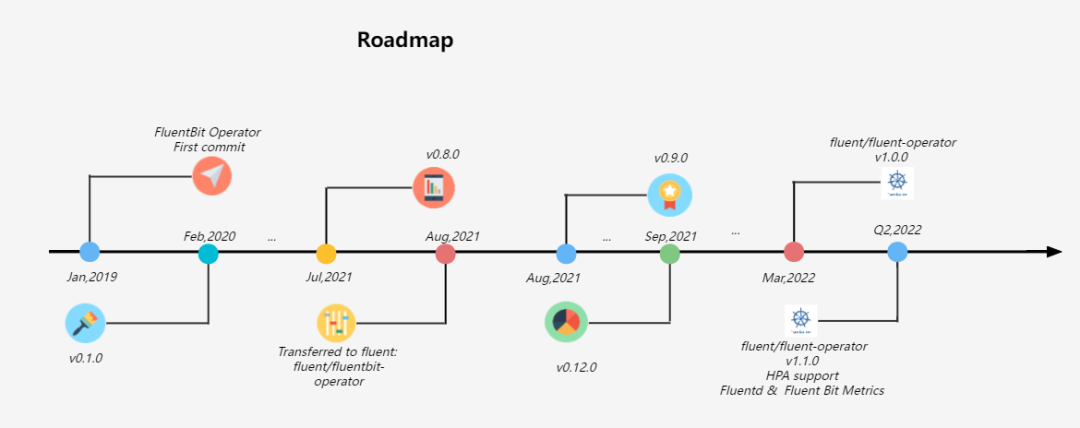
2019 年 1 月 21 日,KubeSphere 社区为了满足以云原生的方式管理 Fluent Bit 的需求开发了 Fluentbit Operator,并在 2020 年 2 月 17 日发布了 v0.1.0 版本。此后产品不断迭代,在 2021 年 8 月 4 日 正式将 Fluentbit Operator 捐献给 Fluent 社区。
Fluentbit Operator 降低了 Fluent Bit 的使用门槛,能高效、快捷的处理日志信息,但是 Fluent Bit 处理日志的能力稍弱,我们还没有集成日志处理工具,比如 Fluentd,它有更多的插件可供使用。基于以上需求,Fluentbit Operator 集成了 Fluentd,旨在将 Fluentd 集成为一个可选的日志聚合和转发层,并重新命名为 Fluent Operator(GitHub 地址:https://github.com/fluent/fluent-operator)。在 2022 年 3 月 25 日 Fluent Operator 发布了 v1.0.0 版本,并将继续迭代 Fluentd Operator,预计在 2022 年第 2 季度发布 v1.1.0 版本,增加更多的功能与亮点。
使用 Fluent Operator 可以灵活且方便地部署、配置及卸载 Fluent Bit 以及 Fluentd。同时, 社区还提供支持 Fluentd 以及 Fluent Bit 的海量插件,用户可以根据实际情况进行定制化配置。官方文档提供了详细的示例,极易上手,大大降低了 Fluent Bit 以及 Fluentd 的使用门槛。
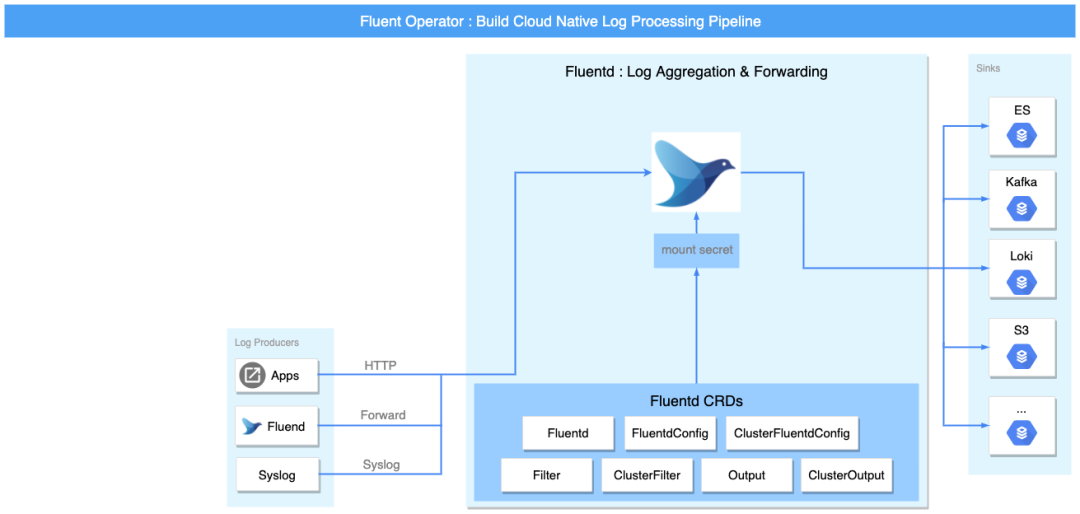
日志流水线的各个阶段
Fluent Operator 可以单独部署 Fluent Bit 或者 Fluentd,并不会强制要求使用 Fluent Bit 或 Fluentd,同时还支持使用 Fluentd 接收 Fluent Bit 转发的日志流进行多租户日志隔离,这极大地增加了部署的灵活性和多样性。 为了更全面的了解 Fluent Operator,下图以完整的日志流水线为例,将流水线分为三部分:采集和转发、过滤以及输出。
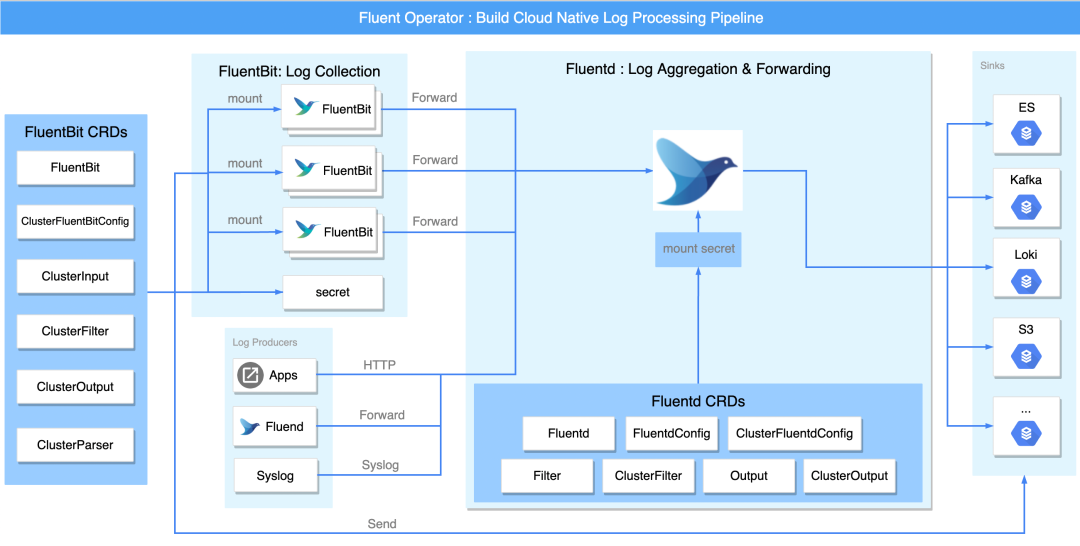
采集和转发
Fluent Bit 与 Fluentd 均可以采集日志。
单独部署时,可以通过 Fluent Bit 的 intput 插件或者 Fluentd 的 forward 以及 http 等插件来满足对日志收集的需求。两者结合时,Fluentd 可使用 forward 接受 Fluent Bit 的日志流转发。
在性能方面,Fluent Bit 相比 Fluentd 更轻量,内存消耗更小(约为 650KB),所以主要由 Fluent Bit 负责采集与转发日志。在各个节点上通过以 DaemonSet 形式安装的 Fluent Bit 来收集和转发日志。
过滤
日志收集的数据往往过于杂乱与冗余,这要求日志处理中间件提供对日志信息进行过滤和处理的能力。Fluent Bit 或 Fluentd 均支持 filter 插件,用户可以根据自身需求,整合和定制日志数据。
输出
Fluent Bit output 或 Fluentd output 插件将处理后的日志信息输出到多个目的地,目的地可以是 Kafka、Elasticsearch 等第三方组件。
CRD 简介
Fluent Operator 为 Fluent Bit 和 Fluentd 分别定义了两个 Group:fluentbit.fluent.io 和 fluentd.fluent.io。
fluentbit.fluent.io
fluentbit.fluent.io 分组下包含以下 6 个 CRDs:
- Fluentbit CRD 定义了 Fluent Bit 的属性,比如镜像版本、污点、亲和性等参数。
- ClusterFluentbitConfig CRD 定义了 Fluent Bit 的配置文件。
- ClusterInput CRD 定义了 Fluent Bit 的 input 插件,即输入插件。通过该插件,用户可以自定义采集何种日志。
- ClusterFilter CRD 定义了 Fluent Bit 的 filter 插件,该插件主要负责过滤以及处理 fluentbit 采集到的信息。
- ClusterParser CRD 定义了 Fluent Bit 的 parser 插件,该插件主要负责解析日志信息,可以将日志信息解析为其他格式。
- ClusterOutput CRD 定义了 Fluent Bit 的 output 插件,该插件主要负责将处理后的日志信息转发到目的地。
fluentd.fluent.io
fluentd.fluent.io 分组下包含以下 7 个 CRDs:
- Fluentd CRD 定义了 Fluentd 的属性,比如镜像版本、污点、亲和性等参数。
- ClusterFluentdConfig CRD 定义了 Fluentd 集群级别的配置文件。
- FluentdConfig CRD 定义了 Fluentd 的 namespace 范围的配置文件。
- ClusterFilter CRD 定义了 Fluentd 集群范围的 filter 插件,该插件主要负责过滤以及处理 Fluentd 采集到的信息。如果安装了 Fluent Bit,则可以更进一步的处理日志信息。
- Filter CRD 该 CRD 定义了 Fluentd namespace 的 filter 插件,该插件主要负责过滤以及处理 Fluentd 采集到的信息。如果安装了 Fluent Bit,则可以更进一步的处理日志信息。
- ClusterOutput CRD 该 CRD 定义了 Fluentd 的集群范围的 output 插件,该插件主要负责将处理后的日志信息转发到目的地。
- Output CRD 该 CRD 定义了 Fluentd 的 namespace 范围的 output 插件,该插件主要负责将处理后的日志信息转发到目的地。
编排原理简介 (instance + mounted secret + CRD 的抽象能力)
尽管 Fluent Bit 与 Fluentd 都有收集、处理(解析和过滤)以及输出日志的能力,但它们有着不同的优点。Fluent Bit 相对 Fluentd 更为轻量与高效,而 Fluentd 插件更为丰富。
为了兼顾这些优点,Fluent Operator 允许用户以多种方式灵活地使用 Fluent Bit 和 Fluentd:
- Fluent Bit only 模式:如果您只需要在收集日志并在简单处理后将日志发送到最终目的地,您只需要 Fluent Bit。
- Fluentd only 模式:如果需要通过网络以 HTTP 或 Syslog 等方式接收日志,然后将日志处理并发送到最终的目的地,则只需要 Fluentd。
- Fluent Bit + Fluentd 模式:如果你还需要对收集到的日志进行一些高级处理或者发送到更多的 sink,那么你可以组合使用 Fluent Bit 和 Fluentd。
Fluent Operator 允许您根据需要在上述 3 种模式下配置日志处理管道。Fluentd 与 Fluent Bit 具有丰富的插件以满足用户的各种自定义化需求,由于 Fluentd 与 Fluent Bit 的配置挂载方式相似,所以以 Fluent Bit 配置文件的挂载方式来进行简单介绍。
在 Fluent Bit CRD 中每个 ClusterInput, ClusterParser, ClusterFilter,ClusterOutput 代表一个 Fluent Bit 配置部分,由 ClusterFluentBitConfig 标签选择器选择。Fluent Operator 监视这些对象,构建最终配置,最后创建一个 Secret 来存储安装到 Fluent Bit DaemonSet 中的配置。整个工作流程如下所示:

因为 Fluent Bit 本身没有重新加载接口(详细信息请参阅此已知问题),为了使 Fluent Bit 能够在 Fluent Bit 配置更改时获取并使用最新配置,添加了一个名为 fluentbit watcher 的包装器,以便在检测到 Fluent Bit 配置更改时立即重新启动 Fluent Bit 进程。这样,无需重新启动 Fluent Bit pod 即可重新加载新配置。
为了使用户配置更为方便,我们基于 CRD 强大的抽象能力将应用以及配置的参数提取出来。用户可以通过定义的 CRD 来对 Fluent Bit 以及 Fluentd 进行配置。Fluent Operator 监控这些对象的变化从而更改 Fluent Bit 以及 Fluentd 的状态及配置。特别是插件的定义,为了使用户更为平滑地过渡,我们在命名上基本与 Fluent Bit 原有的字段保持一致,降低使用的门槛。
如何实现多租户日志隔离
Fluent Bit 可以高效的采集日志,但是如果需要对日志信息进行复杂处理,Fluent Bit 则稍显力不从心,而 Fluentd 则可以借助其丰富的插件完成对日志信息的高级处理。fluent-operator 为此抽象了 Fluentd 的各种插件,以便可以对日志信息进行处理来满足用户的自定义需求。
从上面 CRD 的定义可以看出,我们将 Fluentd 的 config 及插件的 CRD 分成了 cluster 级别与 namespace 级别的 CRD。通过将 CRD 定义为两种范围,借助 Fluentd 的 label router 插件,就可以达到多租户隔离的效果。
我们在 clusterfluentconfig 添加了 watchNamespace 字段,用户可以根据自己的需求选择监听哪些 namespace,如果为空,则表示监控所有的 namespace。而 namesapce 级别的 fluentconfig 只能监听自己所位于的 namespace 中的 CR 及全局级别的配置。所以 namespace 级别的日志既可以输出到该 namespace 中的 output,也可以输出到 clsuter 级别的 output,从而达到多租户隔离的目的。
Fluent Operator vs logging-operator
差别
- 两者皆可自动部署 Fluent Bit 与 Fluentd。logging-operator 需要同时部署 Fluent Bit 和 Fluentd,而 Fluent Operator 支持可插拔部署 Fluent Bit 与 Fluentd,非强耦合,用户可以根据自己的需要自行选择部署 Fluentd 或者是 Fluent Bit,更为灵活。
- 在 logging-operator 中 Fluent Bit 收集的日志都必须经过 Fluentd 才能输出到最终的目的地,而且如果数据量过大,那么 Fluentd 存在单点故障隐患。Fluent Operator 中 Fluent Bit 可以直接将日志信息发送到目的地,从而规避单点故障的隐患。
- logging-operator 定义了 loggings,outputs,flows,clusteroutputs 以及 clusterflows 四种 CRD,而 Fluent Operator 定义了 13 种 CRD。相较于 logging-operator,Fluent Operator 在 CRD 定义上更加多样,用户可以根据需要更灵活的对 Fluentd 以及 Fluent Bit 进行配置。同时在定义 CRD 时,选取与 Fluentd 以及 Fluent Bit 配置类似的命名,力求命名更加清晰,以符合原生的组件定义。
- 两者均借鉴了 Fluentd 的 label router 插件实现多租户日志隔离。
展望:
- 支持 HPA 自动伸缩;
- 完善 Helm Chart,如收集 metrics 信息;
- ...
用法详解
借助 Fluent Operator 可以对日志进行复杂处理,在这里我们可以通过 fluent-operator-walkthrough 中将日志输出到 elasticsearch 与 kafka 的例子对 Fluent Operator 的实际功能进行介绍。要获得 Fluent Operator 的一些实际操作经验,您需要一个 Kind 集群。同时你还需要在这种类型的集群中设置一个 Kafka 集群和一个 Elasticsearch 集群。
# 创建一个 kind 的集群并命名为 fluent
./create-kind-cluster.sh
# 在 Kafka namespace 下创建一个 Kafka 集群
./deploy-kafka.sh
# 在 elastic namespace 下创建一个 Elasticsearch 集群
./deploy-es.sh
Fluent Operator 控制 Fluent Bit 和 Fluentd 的生命周期。您可以使用以下脚本在 fluent 命名空间中启动 Fluent Operator:
./deploy-fluent-operator.sh
Fluent Bit 和 Fluentd 都已被定义为 Fluent Operator 中的 CRD,您可以通过声明 FluentBit 或 Fluentd 的 CR 来创建 Fluent Bit DaemonSet 或 Fluentd StatefulSet。
Fluent Bit Only 模式
Fluent Bit Only 将只启用轻量级的 Fluent Bit 对日志进行采集、处理以及转发。
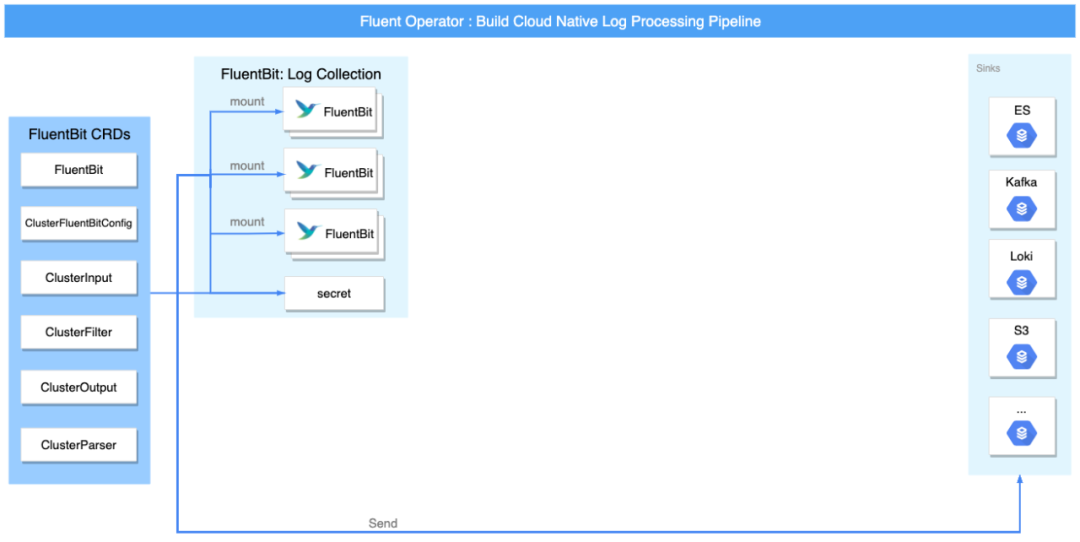
使用 Fluent Bit 收集 kubelet 的日志并输出到 Elasticsearch
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: FluentBit
metadata:
name: fluent-bit
namespace: fluent
labels:
app.kubernetes.io/name: fluent-bit
spec:
image: kubesphere/fluent-bit:v1.8.11
positionDB:
hostPath:
path: /var/lib/fluent-bit/
resources:
requests:
cpu: 10m
memory: 25Mi
limits:
cpu: 500m
memory: 200Mi
fluentBitConfigName: fluent-bit-only-config
tolerations:
- operator: Exists
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFluentBitConfig
metadata:
name: fluent-bit-only-config
labels:
app.kubernetes.io/name: fluent-bit
spec:
service:
parsersFile: parsers.conf
inputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
filterSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
outputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterInput
metadata:
name: kubelet
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
systemd:
tag: service.kubelet
path: /var/log/journal
db: /fluent-bit/tail/kubelet.db
dbSync: Normal
systemdFilter:
- _SYSTEMD_UNIT=kubelet.service
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFilter
metadata:
name: systemd
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
match: service.*
filters:
- lua:
script:
key: systemd.lua
name: fluent-bit-lua
call: add_time
timeAsTable: true
---
apiVersion: v1
data:
systemd.lua: |
function add_time(tag, timestamp, record)
new_record = {}
timeStr = os.date("!*t", timestamp["sec"])
t = string.format("%4d-%02d-%02dT%02d:%02d:%02d.%sZ",
timeStr["year"], timeStr["month"], timeStr["day"],
timeStr["hour"], timeStr["min"], timeStr["sec"],
timestamp["nsec"])
kubernetes = {}
kubernetes["pod_name"] = record["_HOSTNAME"]
kubernetes["container_name"] = record["SYSLOG_IDENTIFIER"]
kubernetes["namespace_name"] = "kube-system"
new_record["time"] = t
new_record["log"] = record["MESSAGE"]
new_record["kubernetes"] = kubernetes
return 1, timestamp, new_record
end
kind: ConfigMap
metadata:
labels:
app.kubernetes.io/component: operator
app.kubernetes.io/name: fluent-bit-lua
name: fluent-bit-lua
namespace: fluent
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: es
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "fluentbit-only"
spec:
matchRegex: (?:kube|service)\.(.*)
es:
host: elasticsearch-master.elastic.svc
port: 9200
generateID: true
logstashPrefix: fluent-log-fb-only
logstashFormat: true
timeKey: "@timestamp"
EOF
使用 Fluent Bit 收集 kubernetes 的应用日志并输出到 Kafka
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: FluentBit
metadata:
name: fluent-bit
namespace: fluent
labels:
app.kubernetes.io/name: fluent-bit
spec:
image: kubesphere/fluent-bit:v1.8.11
positionDB:
hostPath:
path: /var/lib/fluent-bit/
resources:
requests:
cpu: 10m
memory: 25Mi
limits:
cpu: 500m
memory: 200Mi
fluentBitConfigName: fluent-bit-config
tolerations:
- operator: Exists
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFluentBitConfig
metadata:
name: fluent-bit-config
labels:
app.kubernetes.io/name: fluent-bit
spec:
service:
parsersFile: parsers.conf
inputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
filterSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
outputSelector:
matchLabels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterInput
metadata:
name: tail
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
spec:
tail:
tag: kube.*
path: /var/log/containers/*.log
parser: docker
refreshIntervalSeconds: 10
memBufLimit: 5MB
skipLongLines: true
db: /fluent-bit/tail/pos.db
dbSync: Normal
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterFilter
metadata:
name: kubernetes
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/mode: "k8s"
spec:
match: kube.*
filters:
- kubernetes:
kubeURL: https://kubernetes.default.svc:443
kubeCAFile: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
kubeTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
labels: false
annotations: false
- nest:
operation: lift
nestedUnder: kubernetes
addPrefix: kubernetes_
- modify:
rules:
- remove: stream
- remove: kubernetes_pod_id
- remove: kubernetes_host
- remove: kubernetes_container_hash
- nest:
operation: nest
wildcard:
- kubernetes_*
nestUnder: kubernetes
removePrefix: kubernetes_
---
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: kafka
labels:
fluentbit.fluent.io/enabled: "false"
fluentbit.fluent.io/mode: "k8s"
spec:
matchRegex: (?:kube|service)\.(.*)
kafka:
brokers: my-cluster-kafka-bootstrap.kafka.svc:9091,my-cluster-kafka-bootstrap.kafka.svc:9092,my-cluster-kafka-bootstrap.kafka.svc:9093
topics: fluent-log
EOF
Fluent Bit + Fluentd 模式
凭借 Fluentd 丰富的插件,Fluentd 可以充当日志聚合层,执行更高级的日志处理。您可以使用 Fluent Operator 轻松地将日志从 Fluent Bit 转发到 Fluentd。
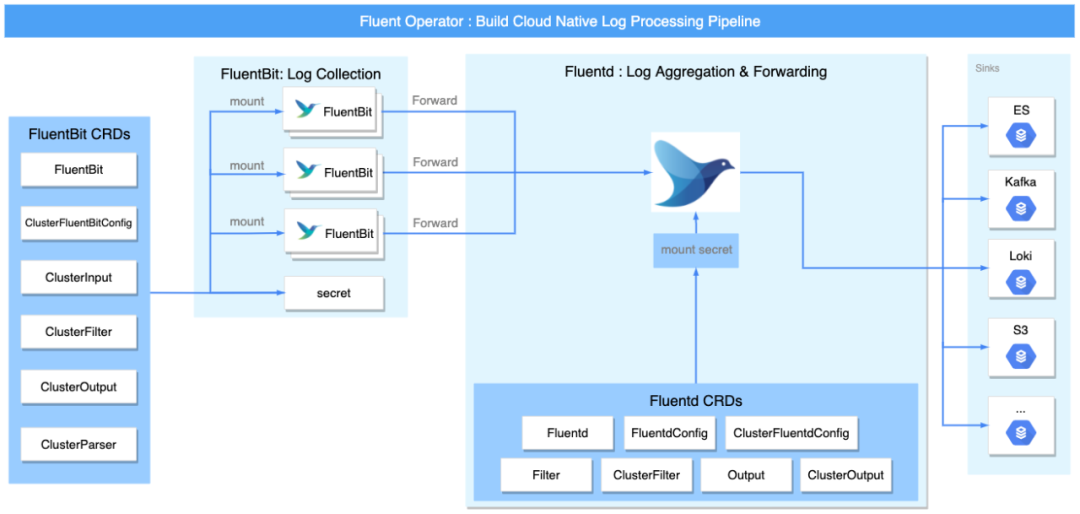
将日志从 Fluent Bit 转发到 Fluentd
要将日志从 Fluent Bit 转发到 Fluentd,您需要启用 Fluent Bit 的 forward 插件,如下所示:
cat <<EOF | kubectl apply -f -
apiVersion: fluentbit.fluent.io/v1alpha2
kind: ClusterOutput
metadata:
name: fluentd
labels:
fluentbit.fluent.io/enabled: "true"
fluentbit.fluent.io/component: logging
spec:
matchRegex: (?:kube|service)\.(.*)
forward:
host: fluentd.fluent.svc
port: 24224
EOF
部署 Fluentd
Fluentd forward Input 插件会在部署 Fluentd 时默认启用,因此你只需要部署下列 yaml 来部署 Fluentd:
apiVersion: fluentd.fluent.io/v1alpha1
kind: Fluentd
metadata:
name: fluentd
namespace: fluent
labels:
app.kubernetes.io/name: fluentd
spec:
globalInputs:
- forward:
bind: 0.0.0.0
port: 24224
replicas: 1
image: kubesphere/fluentd:v1.14.4
fluentdCfgSelector:
matchLabels:
config.fluentd.fluent.io/enabled: "true"
ClusterFluentdConfig: Fluentd 集群范围的配置
如果你定义了 ClusterFluentdConfig,那么你可以收集任意或者所有 namespace 下的日志。我么可以通过 watchedNamespaces 字段来选择所需要采集日志的 namespace。以下配置是采集 kube-system 以及 default namespace 下的日志:
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "cluster"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-es
labels:
output.fluentd.fluent.io/scope: "cluster"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-fd
EOF
FluentdConfig: Fluentd namespace 范围的配置
如果你定义了 FluentdConfig,那么你只能将与该 FluentdConfig 同一 namespace 下的日志发送到 Output,通过这种方式实现了不同 namespace 下的日志隔离。
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
outputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "namespace"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: namespace-fluentd-output-es
namespace: fluent
labels:
output.fluentd.fluent.io/scope: "namespace"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-namespace-fd
EOF
根据 namespace 将日志路由到不同的 Kafka topic
同样您可以使用 Fluentd 的 filter 插件根据不同的 namespace 将日志分发到不同的 topic。在这里我们包含在 Fluentd 内核中的插件 recordTransformer,该插件可以对事件进行增删改查。
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-kafka
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterFilterSelector:
matchLabels:
filter.fluentd.fluent.io/type: "k8s"
filter.fluentd.fluent.io/enabled: "true"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/type: "kafka"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFilter
metadata:
name: cluster-fluentd-filter-k8s
labels:
filter.fluentd.fluent.io/type: "k8s"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- recordTransformer:
enableRuby: true
records:
- key: kubernetes_ns
value: ${record["kubernetes"]["namespace_name"]}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-kafka
labels:
output.fluentd.fluent.io/type: "kafka"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- kafka:
brokers: my-cluster-kafka-bootstrap.default.svc:9091,my-cluster-kafka-bootstrap.default.svc:9092,my-cluster-kafka-bootstrap.default.svc:9093
useEventTime: true
topicKey: kubernetes_ns
EOF
同时使用集群范围与 namespace 范围的 FluentdConfig
当然,你可以像下面一样同时使用 ClusterFluentdConfig 与 FluentdConfig。FluentdConfig 会将 fluent namespace 下的日志发送到 ClusterOutput,而 ClusterFluentdConfig 同时也会将 watchedNamespaces 字段下的 namespace(即 kube-system 以及 default 两个 namespace)发送到 ClusterOutput。
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-hybrid
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config-hybrid
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-es-hybrid
labels:
output.fluentd.fluent.io/scope: "hybrid"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-hybrid-fd
EOF
在多租户场景下同时使用集群范围与 namespace 范围的 FluentdConfig
在多租户场景下,我们可以同时使用集群范围与 namespace 范围的 FluentdConfig 达到日志隔离的效果。
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: namespace-fluentd-config-user1
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
outputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-cluster-only
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- kubesphere-system
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/scope: "cluster-only"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: namespace-fluentd-output-user1
namespace: fluent
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-user1-fd
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-user1
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/user: "user1"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-user1-fd
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-cluster-only
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/scope: "cluster-only"
spec:
outputs:
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-cluster-only-fd
EOF
为 Fluentd 输出使用缓冲区
您可以添加一个缓冲区来缓存 output 插件的日志。
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFluentdConfig
metadata:
name: cluster-fluentd-config-buffer
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
watchedNamespaces:
- kube-system
- default
clusterFilterSelector:
matchLabels:
filter.fluentd.fluent.io/type: "buffer"
filter.fluentd.fluent.io/enabled: "true"
clusterOutputSelector:
matchLabels:
output.fluentd.fluent.io/type: "buffer"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterFilter
metadata:
name: cluster-fluentd-filter-buffer
labels:
filter.fluentd.fluent.io/type: "buffer"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- recordTransformer:
enableRuby: true
records:
- key: kubernetes_ns
value: ${record["kubernetes"]["namespace_name"]}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: ClusterOutput
metadata:
name: cluster-fluentd-output-buffer
labels:
output.fluentd.fluent.io/type: "buffer"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- stdout: {}
buffer:
type: file
path: /buffers/stdout.log
- elasticsearch:
host: elasticsearch-master.elastic.svc
port: 9200
logstashFormat: true
logstashPrefix: fluent-log-buffer-fd
buffer:
type: file
path: /buffers/es.log
EOF
Fluentd Only 模式
你同样可以开启 Fluentd Only 模式,该模式只会部署 Fluentd statefulset。
使用 Fluentd 从 HTTP 接收日志并输出到标准输出
如果你想单独开启 Fluentd 插件,你可以通过 HTTP 来接收日志。
cat <<EOF | kubectl apply -f -
apiVersion: fluentd.fluent.io/v1alpha1
kind: Fluentd
metadata:
name: fluentd-http
namespace: fluent
labels:
app.kubernetes.io/name: fluentd
spec:
globalInputs:
- http:
bind: 0.0.0.0
port: 9880
replicas: 1
image: kubesphere/fluentd:v1.14.4
fluentdCfgSelector:
matchLabels:
config.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: FluentdConfig
metadata:
name: fluentd-only-config
namespace: fluent
labels:
config.fluentd.fluent.io/enabled: "true"
spec:
filterSelector:
matchLabels:
filter.fluentd.fluent.io/mode: "fluentd-only"
filter.fluentd.fluent.io/enabled: "true"
outputSelector:
matchLabels:
output.fluentd.fluent.io/mode: "true"
output.fluentd.fluent.io/enabled: "true"
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Filter
metadata:
name: fluentd-only-filter
namespace: fluent
labels:
filter.fluentd.fluent.io/mode: "fluentd-only"
filter.fluentd.fluent.io/enabled: "true"
spec:
filters:
- stdout: {}
---
apiVersion: fluentd.fluent.io/v1alpha1
kind: Output
metadata:
name: fluentd-only-stdout
namespace: fluent
labels:
output.fluentd.fluent.io/enabled: "true"
output.fluentd.fluent.io/enabled: "true"
spec:
outputs:
- stdout: {}
EOF
本文由博客一文多发平台 OpenWrite 发布!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号